
There’s no law that requires GDPS implementations to use the Copy Once Facility for Global Mirror, but in my opinion, there ought to be.
The Copy Once Facility incorporates a simple idea: Copy Once describes a group of volumes without critical data; data that does not need to be continuously copied. An old version of the data on these volumes is sufficient for recovery. The beauty of the Copy Once Facility is that it is largely an act of omission: the volumes in the Copy Once group are suspended and withdrawn from the Global Mirror Session after the initial copies are completed.
An additional feature of Copy Once is that you can periodically refresh the data in the DR Site if you want to. Refresh is only required if volumes move, if volumes are added or deleted, or if data gets resized. Some installations perform a refresh once a quarter as a matter of policy to ensure they have a valid copy of the data.
Some examples of good candidates for Copy Once are volumes that provide Data Set Allocation for data to be overwritten in recovery, volumes for which an old version of the data is just fine in case of recovery, such as my TSO data, and volumes for which only the VOLSER is needed at the recovery site, such as Work/Temp/Sortwk volumes.
Examining IBM GDPS with Global Mirror
Recently, one of our customers asked us to conduct an experiment using IntelliMagic Vision for z/OS to demonstrate the bandwidth benefits of the Copy Once Facility that they were already using. In this study, we examined their IBM GDPS implementation with Global Mirror and compared the Global Mirror Send Rate with and without Copy Once. The ‘Copy Once’ activity was measured on Monday December 8th and Tuesday December 9th, and what we called ‘All Active’ measurements were taken exactly a week later, on Monday December 15th and Tuesday the 16th, after temporarily setting all Copy Once volumes to normal copy mode where they are all mirrored continuously.
This environment has its Primary volumes on site ‘A’, a Secondary Metro Mirror copy on site ‘B’ for High Availability and a Tertiary Global Mirror copy on site ‘C’ for Disaster Recovery. In order to record the copy activity, we made sure SMF record type 74.8 (PPRC Link Statistics) was available and made one volume on the DSS containing the Secondary Volumes online to z/OS. This allowed us to capture the Link Statistics for the Synchronous Metro Mirror write activity (A->B) and the Asynchronous Global Mirror write activity (B->C) for the same intervals.
We wanted to compare the used bandwidth (MB/sec) on the remote copy links in the Copy Once situation to the used bandwidth when the Copy Once Facility was not used. Note that the Copy Once Facility only applies to the Global Mirror part, that is, the Tertiary copies. There is no comparable feature for the Secondary copies under Metro Mirror – all data must get copied all the time.
The following table describes the status of the remote copy setup between the A, B and C sites on the two pairs of dates in the study.
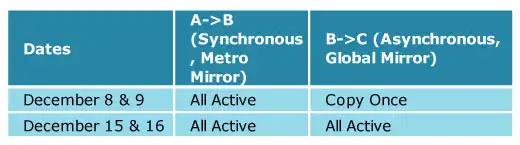
In the table below you can see the 24-hour averages of the MB/sec that was being sent from the Primary to the Secondary and from the Secondary to the Tertiary on the days we investigated. These values were taken from an export we made from IntelliMagic Vision.
DSS Group 1:

DSS Group 2:

DSS Group 3:

Bandwidth Savings from Copy Once
Remember that the Metro Mirror Send Rate between A and B is independent of whether Copy Once is used or not, since Copy Once is only applicable to the Global Mirror relationship between B and C. Thus, the A->B Send Rate comparison was only included to gauge how similar the primary workload was during the ‘All Active’ and ‘Copy Once’ time frames.
The first observation was that on the Tuesday during the Copy Once timeframe, the write workload for DSS Group 1 was much higher than during the ‘All Active’ Tuesday. We had expected that the A-> B Send Rates would be roughly equal, say within 10-15% of each other, given that we are comparing weekdays to the exact same day in the following week.
When we discussed this observation with the customer, this discrepancy between the Tuesdays for DSS Group 1 was not considered a large enough problem to throw it out of the comparison (chalk it up to an unexpectedly busy day).
To show the savings on bandwidth because of Copy Once, we first looked at the B->C Send Rate which measures the used bandwidth for the Asynchronous copy for both scenarios. The difference in the table shows a negative number if there is a decrease in bandwidth in the Copy Once situation, compared to the ‘All Active’ situation. You can see the decrease is omnipresent and significant; the only case where the savings were expressed in a single digit number was for the above mentioned anomalous Tuesday for DSS Group 1.
To express the savings more clearly, and independent of day-to-day primary workload changes, we created a “Percent sent to Tertiary” calculation to show what percentage of the Synchronous copy activity to the Secondary is also copied from the Secondary to the Tertiary site.
During the “All Active” times, when every volume is actively copied under Global Mirror, we would expect the B -> C send rate to be quite close to the A -> B Send Rate; and indeed the table shows values around 80%. During “Copy Once” times, this percentage drops significantly, sometimes even to under 40%. The “Relative Difference” value shows how much savings in Secondary-to-Tertiary bandwidth can be achieved just by starting using the Copy Once facility.
Benefits of GDPS Copy Once
On the whole, the use of Copy Once Facility provided a savings of between 28% and 50% of the Disaster Recovery bandwidth which would have been required if the Copy Once Facility did not exist and all volumes were continuously mirrored. One could argue that the higher bandwidth must somehow be provisioned for the initial copy and refresh activity, but the counter to that argument is that the refresh can occur at a time of your choosing, when overall bandwidth requirements are low.
Based on the case above, I believe that using the Copy Once Facility of GDPS is good practice. A Copy Once Facility is not expensive to implement or maintain and can save up to 50% of the bandwidth that would be required if it wasn’t available. These results can also be extrapolated to zGM, SRDF/A, or HUR environments since Copy Once concerns the characteristics of the data in the data center and not the replication technique selected.
If you would like a better understanding of the potential bandwidth savings from implementing GDPS Copy Once in your environment, please contact us to schedule a discussion with one of our technical experts.
IntelliMagic Vision in GDPS Environments
This IntelliMagic Technical Note provides a brief overview of how IntelliMagic Vision complements IBM’s Geographically Dispersed Parallel Sysplex (GDPS) solution.
This article's author
 Dave Heggen
Dave Heggen Read this blog
Related Resources
Unraveling the z16: Understanding the Virtual Cache Architecture and Real-World Performance | IntelliMagic zAcademy
This webinar will provide detailed z16 insights, including an overview of all key z16 advances and a deep dive into the new cache architecture.
Metro Global Mirror (MGM) Monitoring in GDPS Sites | IntelliMagic zAcademy
This webinar provides practical advice about monitoring the recovery point objective (RPO) and factors affecting RPO.
IntelliMagic Vision Support for Hitachi VSP SMF Records from Mainframe Analytics Recorder
Learn how to gain insight into the health of the Hitachi Virtual Storage Platforms VSP 5000 series and VSP F/G1x00 storage systems using the SMF records created by the Hitachi Mainframe Analytics Recorder.
Book a Demo or Connect With an Expert
Discuss your technical or sales-related questions with our mainframe experts today