
Part one of this blog talked about being proactive – but that is not enough. There is too much uncertainty in the world, and you need to be reactive when things don’t quite go as planned. Once again, let’s look to the dictionary for a definition of reactive: “acting in response to a situation rather than creating or controlling it.”
Personally, I would rather control the situation but if I can’t, it seems that responding is the next best choice. But how effectively you respond is the difference between being a valued contributor to the organization or just keeping your desk chair warm!
SAN Administrator Responsibilities
As a SAN administrator your job is to provide applications with access to fast and reliable SAN storage. You provision LUNs on the storage arrays, define storage masking views that contain the server’s initiators, provide LUN access and create zoning on the SAN fabric that allows connectivity. You do your best to maintain an efficient environment and follow vendor best practices to provide applications with appropriate service levels and capacity.
There are many things you can control but there is much outside of your control. You can often influence but not always control aspects of the server configurations such as host connectivity or multi-pathing. Often you don’t have visibility into the host configurations. More germane to this blog, you do not control the applications or workloads running on the hosts attached to the SAN fabric and storage.
As applications evolve, workload variance will occur and subsequently performance bottlenecks in the SAN infrastructure could very well happen. There are quite a few approaches to managing this:
- Leverage Quality of Service controls on the storage controller that prioritize one workload over another. (This can be highly politicized and may not be appropriate for all organizations.)
- Define volume level or host level limits on throughput or IOPS via the storage controller. (This is a very heavy-handed approach that must be implemented carefully as it often pits infrastructure management against the business instead of promoting a healthy partnership.)
- Exploit physical or logical mechanisms to create segregated environments such as Production, User Acceptance Testing, and Development. (This can help but doesn’t resolve problems that may spring up within each individual isolated area.)
- Group it all together and throw ridiculously fast hardware at everything. (This approach can help but there are some drawbacks. It typically increases the overall cost and, there will always be edge cases where a new or existing workload simply surprises everyone.)
SAN Infrastructure Common Problem Scenarios and Best Practices
Since there is no perfect approach to managing the resources in a shared SAN infrastructure you can be sure that the unexpected will happen. This means that events such as hardware failures, workload spikes, or changing access patterns may impact a shared resource in the SAN infrastructure leading to unplanned performance impacts.
Fortunately, there is no need to panic because most issues can be addressed in a straightforward manner. I’m going to walk you through a few common scenarios and best practices:
Scenario #1: Noisy neighbor – This often happens in VMware or virtualized environments in which hosts share the same LUN. There can be a very busy VM that drives such a high amount of load that it starves the other VMs for access to the shared resource.
Scenario #2: Over-subscribed ports – Often there are many host ports that feed into a limited number of actual SAN connections. Whether these are over-subscribed storage ports or over-subscribed NPIV connections, the result is a highly utilized fabric port that can cause performance bottlenecks if extreme.
Scenario #3: In certain rare occasions a misconfigured host has only a single path to the fabric and the single path fails before it is identified. This results in a loss of access by a host and any applications running on it. This can have a large impact on the user depending on failover capabilities that may be configured.
Best Practice #1: Quickly Identify the Noisy Neighbor
In practice, a victim of this kind of “cyber bullying” will just call the help desk and complain about performance. Then the VMware server administrator can identify the VM’s supporting the affected application and its associated datastores.
From a VMware perspective it is easy to identify the datastores with the poor performance. From there, the trick is to identify the bully and understand the underlying storage performance.
In Figure 1 below you can see the VMware guests that are active for a particular datastore. Once the datastore is identified, the chart is easily created within IntelliMagic Vision by clicking filter which then automatically shows only the VMs associated with the datastore in question.
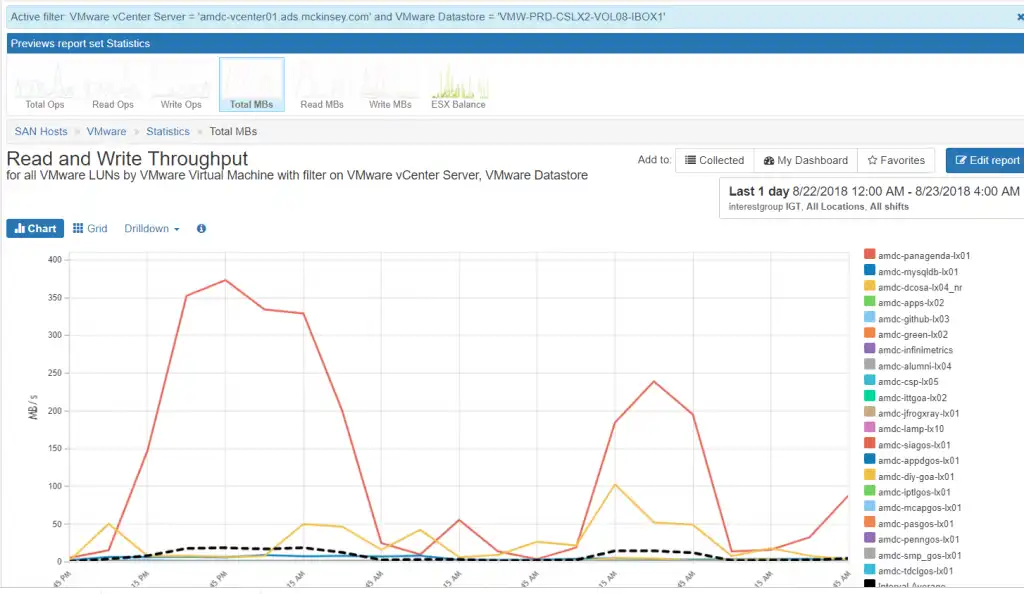
Figure 1: VMware Throughput Filtered on Hot Datastore
By drilling down to the LUN performance for the heavy hitter I can see that the performance is actually quite good on the associated back-end storage as demonstrated in Figure 2. If the VM is experiencing performance issues, it is at a higher level than the storage array.
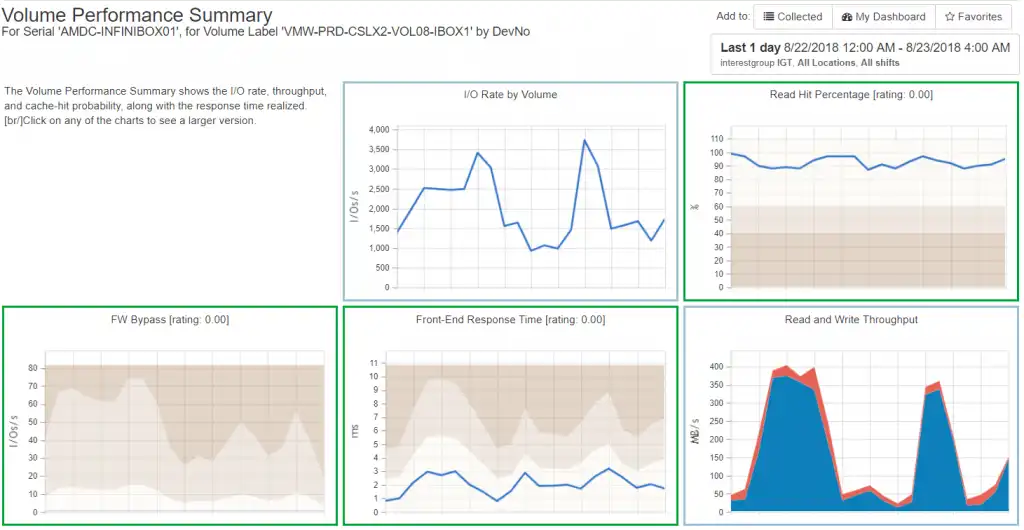
Figure 2: LUN Performance
Best Practice #2: Quickly Identify the Overutilized Port and the Connected Host Ports
It is important to monitor your busy SAN ports and to understand which hosts and host initiators are connected to the ports. In a SAN environment many physical hosts will drive I/O workload through four to six storage ports depending on the technology. IntelliMagic Vision identifies the hot ports and with just a few clicks you can find the connected initiator WWPNs or masking views.
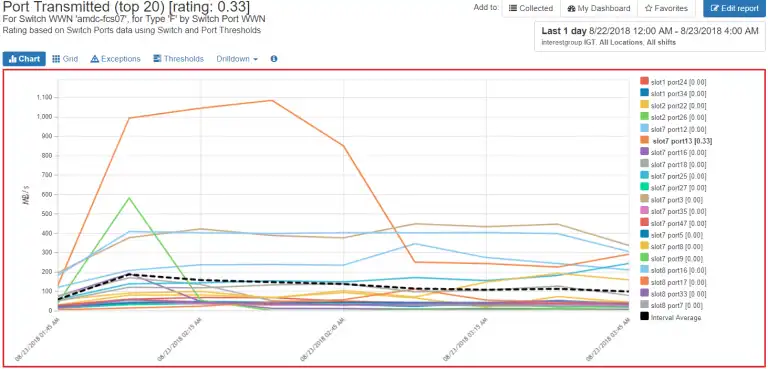
Figure 3: Hot Ports
Once you identify the hot port you can click on the port to identify the connected hosts:
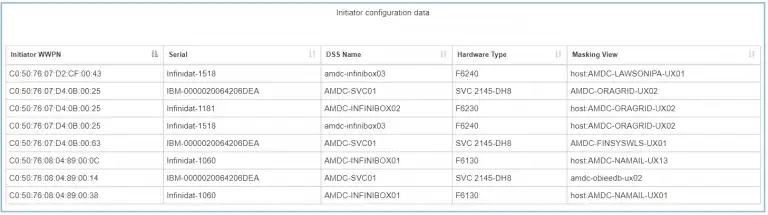
Figure 4: Masking Views for Hot Port
Once you have the connected hosts you can review the workload for those hosts and re-balance the host workloads across different storage ports to eliminate the bottleneck.
Best Practice #3: Proactively Identify Hosts with only a Single Path to the SAN
SAN Fabric best practices are predicated on high performance and high availability. These attributes are fundamentally built into the media and protocol but despite best efforts sometimes hardware fails, or configuration mistakes are made.
For this reason, it is important to identify any hosts with a single path to the fabric. This can be done by inspecting each host’s active paths to the fabric and seeing if there are errors on any of the paths or if there is traffic across the paths.
In a large environment this doesn’t scale. IntelliMagic Vision provides reports that show any hosts with a single path to the SAN fabric. In a few seconds you can audit your SAN environment to ensure you don’t have any potential availability issues. Figure 5 shows a host that has a single path to the fabric.
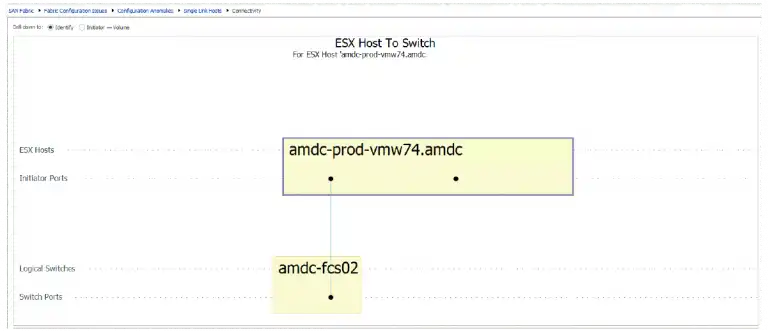
Figure 5: Host with Single Paths
In the end it is the responsibility of the SAN administrator to ensure the environment is healthy and running with minimal surprises. To accomplish this, there are times you should be proactive and others where you must be reactive.
IntelliMagic Vision is designed to provide the automated diagnostics to perform root cause analysis and proactive performance management that ensures smooth sailing. If you are interested in seeing how we can help your environment run smoothly please contact me at brett.allison@intellimagic.com.
This article's author
 Brett Allison
Brett Allison Share this blog
Best Practices for Managing your SAN Performance Part 3: Planning
Read part 3 of the blogRelated Resources
Finding Hidden Time Bombs in Your VMware Connectivity
Seeing real end-to-end risks from the VMware guest through the SAN fabric to the Storage LUN is difficult, leading to many SAN Connectivity issues.
Should There Be a Sub-Capacity Processor Model in Your Future? | IntelliMagic zAcademy
In this webinar, you'll learn about the shift towards processor cache efficiency and its impact on capacity planning, alongside success stories and insights from industry experts.
How to Detect and Resolve “State in Doubt” Errors
IntelliMagic Vision helps reduce the visibility gaps and improves availability by providing deep insights, practical drill downs and specialized domain knowledge for your SAN environment.
Request a Free Trial or Schedule a Demo Today
Discuss your technical or sales-related questions with our availability experts today