Monitor Virtual Tape Performance & Availability with IntelliMagic Vision
IntelliMagic Vision enables performance analysts to manage and optimize their z/OS Virtual Tape environments more effectively and efficiently.
Prevent risks, save time, and optimally configure your environment.

Monitor and Optimize Virtual Tape Costs & Performance with Built-In Health Insights

Proactively Analyze and Prevent Risks
Utilize built-in health insights and artificial intelligence to proactively identify risks, ensure availability, and optimize your Virtual Tape environment.
Save Time and Quickly Resolve Issues
Quickly spot and resolve issues using thousands of out-of-the-box reports, built-in live edit, compare, share, and drill down features.

Expedite Learning and Enhance Domain Expertise
Detailed built-in explanations, guided drilldown options, and end-to-end z/OS support facilitates easy system understanding and knowledge transfer.
Built-In Intelligence at Your Fingertips
Monitor All Cache Flows in a TS7700 Cluster
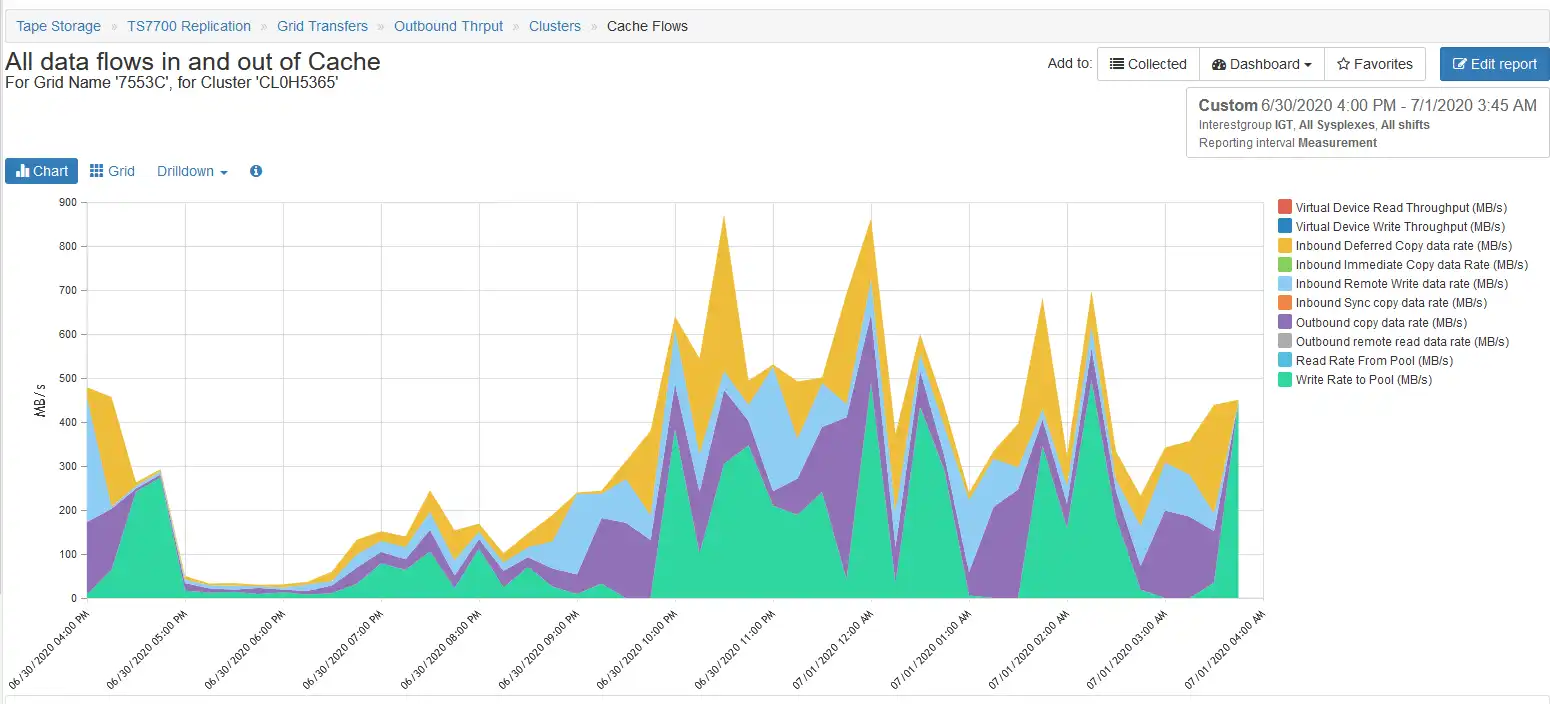
Cache bandwidth in a TS7700 is one of the most important keys for performance. If the cache bandwidth is exhausted, that may impact job runtimes and also the RPO for disaster recovery locations.
IntelliMagic Vision provides insights into which activities are consuming this resource over time. This information gives the input for tuning measurements, e.g. changes to premigration behavior or deferred copy parameters.
Recovery Point Objective Monitoring – Replication Backlog
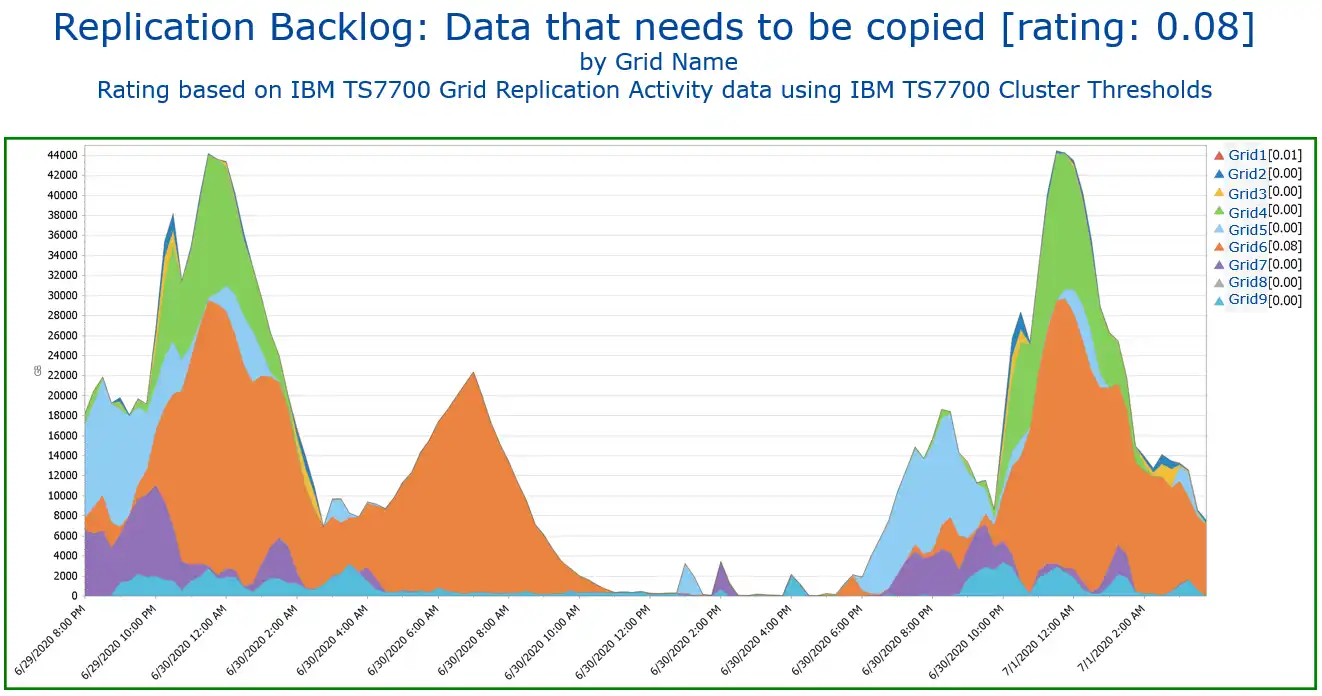
A lot of customers have a third datacenter in a remote location today. Due to performance reasons the data in this location is usually not synchronously replicated. So it is essential to understand how much data is not replicated at a certain point in time.
The chart below shows the so-called replication backlog, which means the amount of data not yet replicated.
RPO Monitoring – Average Deferred Queue Age
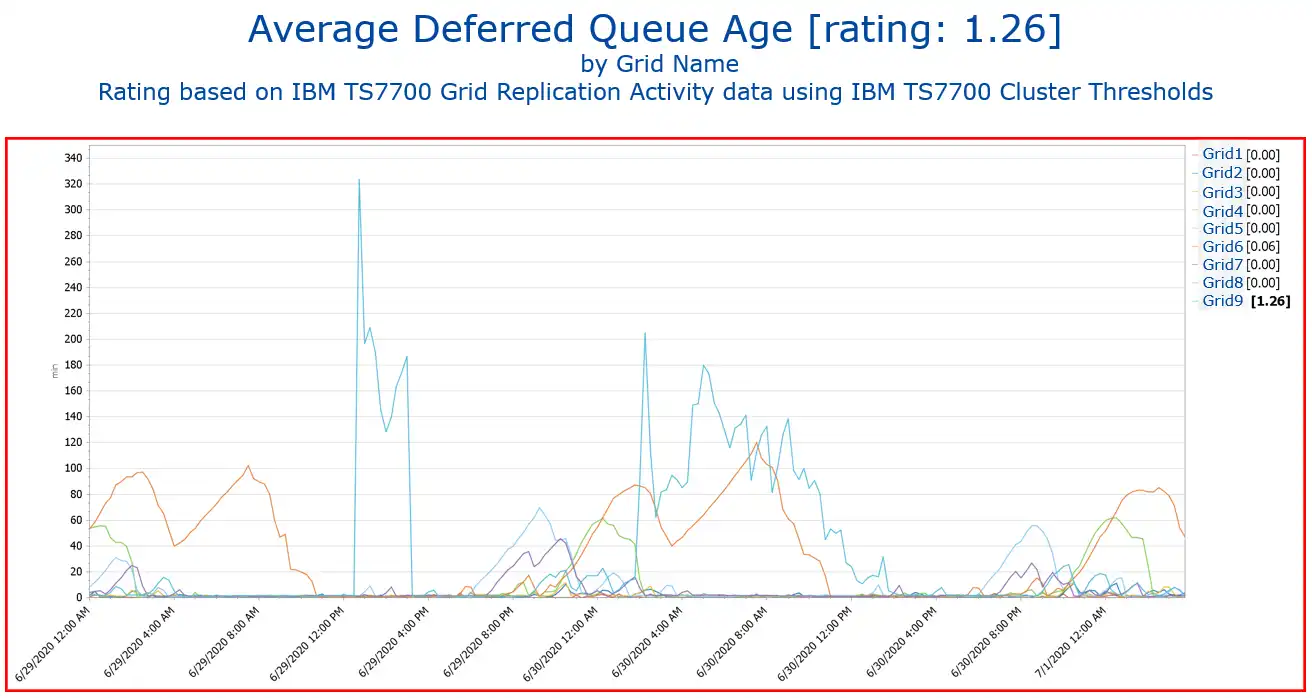
The second question the customer worries about is how many minutes or hours the replication of the data is behind data creation. IntelliMagic Vision answers this question as well.
The waiting time until the copies are processed is too long. This triggers an exception warning to indicate that this should be investigated.
Local Replication Times
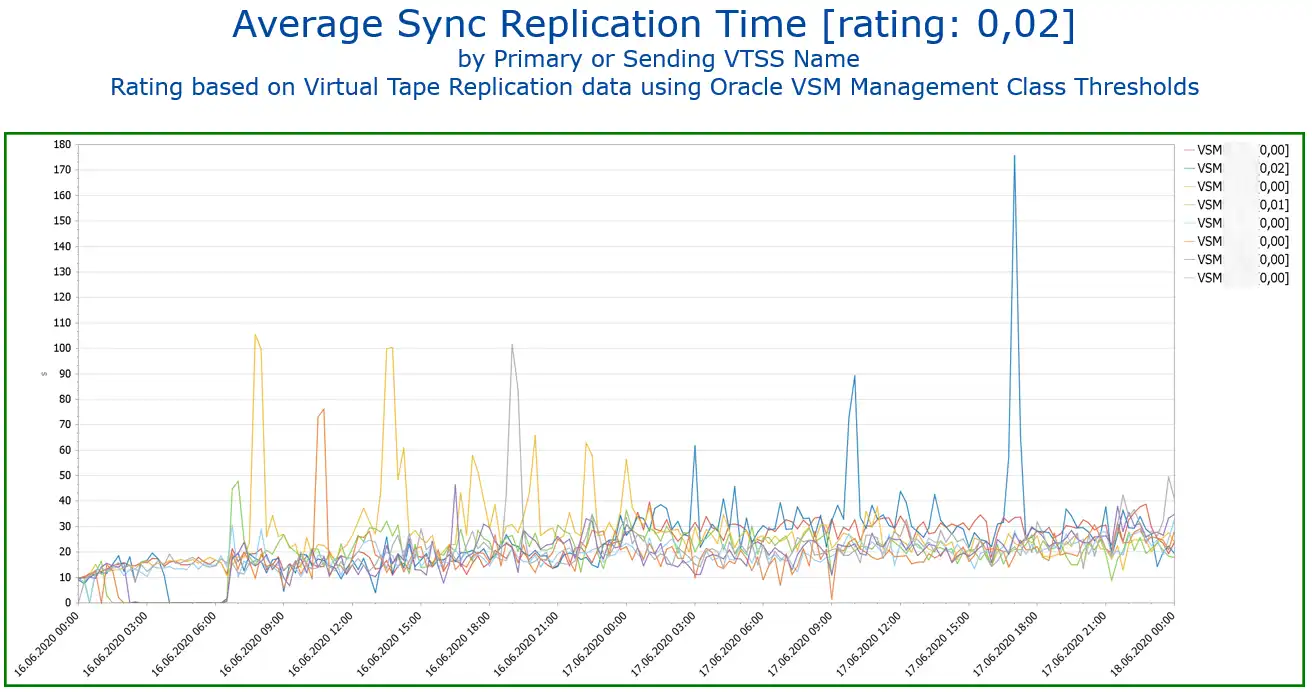
Other replication types can also be measured. Depending on the technology used, this can be different. The following example shows the measurement of the synchronous replication times in a VSM environment.
Controlling the Limits
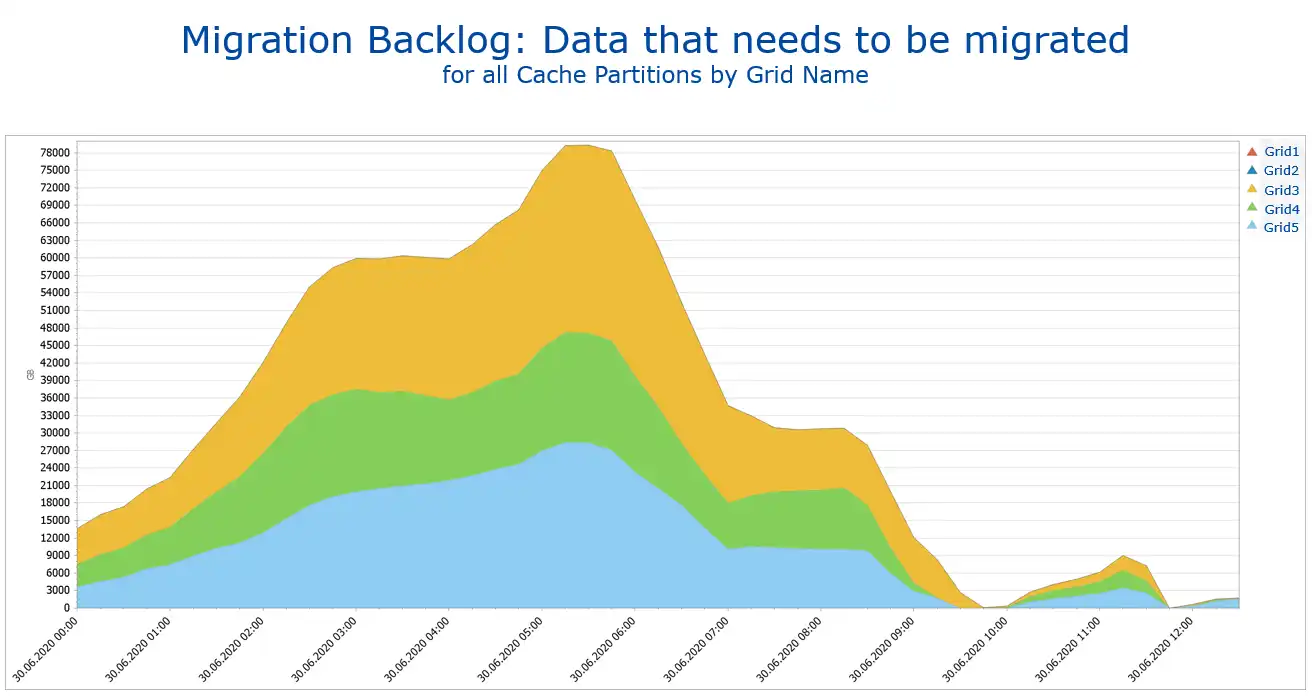
In an IBM TS7700 license for cache enablement, host throughput increments and premigration queue length exist. To understand if these limits are reached, different metrics need to be monitored.
This example shows the migration backlog which shows how much data is waiting in the premigration queue and may trigger throttling.
Host View of Tape Usage
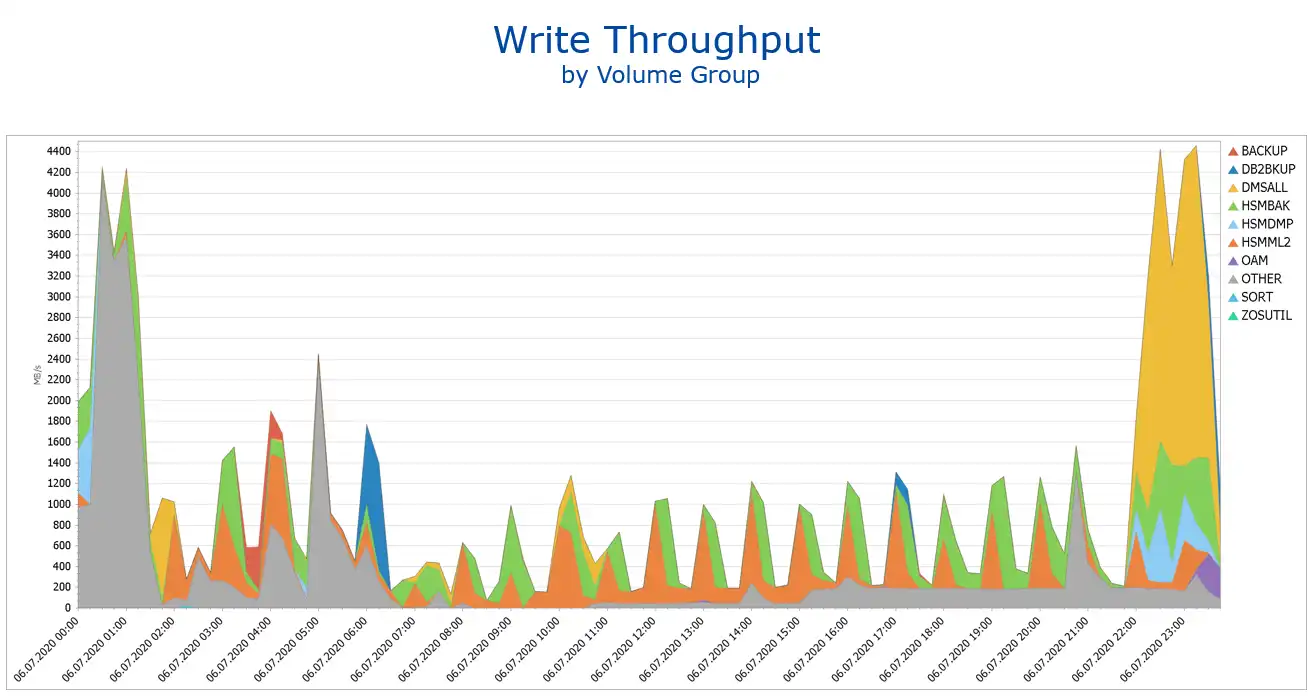
The virtual tape information (e.g. BVIR for the TS7700 family or SMF User record from Oracle HSC) provides information from the hardware view. That means there is no information on which applications use the tape environment and to what extent. The Host view provides this information by application, so the number of mounts, read/write throughput, compression and much more information can be seen.
IntelliMagic Vision provides the ability to see the most common applications “out of the box,” but also the possibility to customize this for user needs. This example shows the Host throughput.
AIOps via SaaS Delivery
Advantages to adopting a cloud model include rapid implementation (no lead time to install and setup the product locally), minimal setup (only for transmitting SMF data), offloading staff resources required to deal with SMF processing issues or to install product maintenance, and easy access to IntelliMagic consulting services to supplement local skills.
Monitor All Cache Flows in a TS7700 Cluster
Cache bandwidth in a TS7700 is one of the most important keys for performance. If the cache bandwidth is exhausted, that may impact job runtimes and also the RPO for disaster recovery locations.
IntelliMagic Vision provides insights into which activities are consuming this resource over time. This information gives the input for tuning measurements, e.g. changes to premigration behavior or deferred copy parameters.
Recovery Point Objective Monitoring – Replication Backlog
A lot of customers have a third datacenter in a remote location today. Due to performance reasons the data in this location is usually not synchronously replicated. So it is essential to understand how much data is not replicated at a certain point in time.
The chart below shows the so-called replication backlog, which means the amount of data not yet replicated.
RPO Monitoring – Average Deferred Queue Age
The second question the customer worries about is how many minutes or hours the replication of the data is behind data creation. IntelliMagic Vision answers this question as well.
The waiting time until the copies are processed is too long. This triggers an exception warning to indicate that this should be investigated.
Local Replication Times
Other replication types can also be measured. Depending on the technology used, this can be different. The following example shows the measurement of the synchronous replication times in a VSM environment.
Controlling the Limits
In an IBM TS7700 license for cache enablement, host throughput increments and premigration queue length exist. To understand if these limits are reached, different metrics need to be monitored.
This example shows the migration backlog which shows how much data is waiting in the premigration queue and may trigger throttling.
Host View of Tape Usage
The virtual tape information (e.g. BVIR for the TS7700 family or SMF User record from Oracle HSC) provides information from the hardware view. That means there is no information on which applications use the tape environment and to what extent. The Host view provides this information by application, so the number of mounts, read/write throughput, compression and much more information can be seen.
IntelliMagic Vision provides the ability to see the most common applications “out of the box,” but also the possibility to customize this for user needs. This example shows the Host throughput.
AIOps via SaaS Delivery
Advantages to adopting a cloud model include rapid implementation (no lead time to install and setup the product locally), minimal setup (only for transmitting SMF data), offloading staff resources required to deal with SMF processing issues or to install product maintenance, and easy access to IntelliMagic consulting services to supplement local skills.
End-to-End Infrastructure Analytics for z/OS Performance and Capacity Planning
zSystems Performance Management
Optimize z/OS Mainframe Systems Management with Availability Intelligence
Benefits
Optimize z/OS Systems performance management using AI-driven analytics to proactively monitor and manage your z/OS environment, prevent disruptions, reduce costs, and preserve the reliability and availability that mainframes are known for.
Explore z/OS Systems Performance Analytics
Db2 Performance Management
Prevent Availability Risks and Optimize Db2 Performance
Benefits
The volume and complexity of Db2 Statistics data and Db2 Accounting data creates a major challenge for analysts who want to derive value from the rich metrics available.
Easy visibility into key Db2 metrics through SMF records is crucial to proactively prevent availability risks and to effectively manage and optimize performance.
Explore Db2 Performance Analytics
Easy visibility into key Db2 metrics through SMF records is crucial to proactively prevent availability risks and to effectively manage and optimize performance.
CICS Performance Management
Monitor and Profile CICS Transactions and Regions with IntelliMagic Vision
Benefits
CICS SMF Transaction data is a rich source of performance insights, but its volume can make analysis challenging using traditional approaches that rely on static reports. Proactive assessment of key Statistics metrics across all regions is essential to identify potential risks to availability.
IntelliMagic Vision enables performance analysts to manage and optimize their z/OS CICS transactions more effectively and efficiently, as well as proactively assess the health of their CICS regions.
Explore CICS Performance Analytics
IntelliMagic Vision enables performance analysts to manage and optimize their z/OS CICS transactions more effectively and efficiently, as well as proactively assess the health of their CICS regions.
Virtual Tape Performance Management
Proactively Manage Virtual and Physical Tape Environments
Benefits
With tape virtualization, tape storage became easier and more economical, but at the same time, more difficult to understand which changes or hardware upgrades are the best choices. With tape libraries being shared across multiple z/OS images, the full picture can only be obtained by aggregating workload and tape hardware information from all z/OS LPARs.
IntelliMagic Vision enables performance analysts to manage and optimize their z/OS Virtual Tape environments more effectively and efficiently.
Explore Tape Performance Analytics
IntelliMagic Vision enables performance analysts to manage and optimize their z/OS Virtual Tape environments more effectively and efficiently.
Disk & Replication Performance Management
Automatically Detect Disk Performance Risks & Quickly Resolve Issues
Benefits
As Disk speeds and throughputs have increased, z/OS applications have come to rely on fast and consistent storage performance. To respond quickly to unexpected disk and replication issues, it is essential that you have insight into the health of the various components in your storage environment.
IntelliMagic Vision enables performance analysts to manage and optimize their z/OS Disk and Replication environment more effectively and efficiently.
Explore Disk Performance Analytics
IntelliMagic Vision enables performance analysts to manage and optimize their z/OS Disk and Replication environment more effectively and efficiently.
MQ Performance Management
Optimize and Analyze MQ Activity and Performance
Benefits
MQ is widely used across z/OS environments, but sites often find it challenging to derive the valuable performance insights potentially available from MQ SMF Statistics and Accounting data due to limitations in existing reporting and available tooling.
IntelliMagic Vision enables performance analysts to manage and optimize their z/OS MQ configurations and activity more effectively and efficiently, as well as proactively assess the health of their queue managers.
Explore MQ Performance Analytics
IntelliMagic Vision enables performance analysts to manage and optimize their z/OS MQ configurations and activity more effectively and efficiently, as well as proactively assess the health of their queue managers.
z/OS Network Performance Management
Automatically Monitor Mainframe Network Security and Protect Your Data
Benefits
TCP/IP is the core of the communication for the z/OS mainframe, both for traffic into and out of the mainframe and internal communication among z/OS images and processor complexes. Proper management is necessary to secure and protect system availability.
IntelliMagic Vision automatically generates GUI-based, interactive, IBM best-practice compliant rated reports that proactively identify areas that indicate potential upcoming risk to TCP/IP health, performance, and security.
Explore z/OS Network Performance Analytics
IntelliMagic Vision automatically generates GUI-based, interactive, IBM best-practice compliant rated reports that proactively identify areas that indicate potential upcoming risk to TCP/IP health, performance, and security.
z/OS Connect: Modern Mainframe API Environment
Optimizing Mainframe API Monitoring for Improved Resource Management
Benefits
IntelliMagic Vision enhances mainframe API monitoring and profiling, providing crucial visibility to address issues at the API or service level, ultimately aiding performance analysts in better resource planning and management reporting.
Explore z/OS Connect Analytics
See Why IntelliMagic is Trusted by Some of the World’s Largest Mainframe Sites
Proactively Manage Virtual and Physical Tape Environments
With tape virtualization, tape storage became easier and more economical, but at the same time, more difficult to understand which changes or hardware upgrades are the best choices. With tape libraries being shared across multiple z/OS images, the full picture can only be obtained by aggregating workload and tape hardware information from all z/OS LPARs.
IntelliMagic Vision automatically generates GUI-based, interactive, rated reports that proactively identify areas that indicate potential upcoming risk to Virtual Tape health and performance.
With IntelliMagic Vision you can:
- avoid tape performance outages
- make wise tape hardware investments
- optimize tape usage
IntelliMagic Vision can be used in z/OS tape environments with virtual tape libraries – including disk-only virtual tape – and with traditional physical tape libraries, and offers out-of-the-box visibility and seamless navigation to manage every component of your z/OS infrastructure under a single solution.
Book a Demo or Connect With an Expert
Discuss your technical or sales-related questions with our mainframe experts today
Solutions for your Problems
Elevate IT Team Impact
Empower new staff and experts. Replace antiquated reporting with automated, intelligent analytics.
Benefits
Artificial Intelligence using built-in expert knowledge and statistics assesses and rates key metrics as good versus bad from a performance or efficiency perspective for the analyst.
Force multiplier - Invite AI to the team to help both new and expert team members in a tight job market.
Cloud Delivery - Immediate access with no maintenance needed.
Force multiplier - Invite AI to the team to help both new and expert team members in a tight job market.
Cloud Delivery - Immediate access with no maintenance needed.
Optimize & Reduce Costs Safely
Save money without compromising service levels or availability.
Benefits
Reduce cost with superior visibility into drivers of cost such as inefficient CPU utilization, configuration and priority issues, imbalance of workloads across hardware resources, consolidation opportunities, etc.
Reduce hardware spend without negative impact on service levels.
Avoid the costs of service delivery problems without both human cost and application unavailability cost.
Reduce hardware spend without negative impact on service levels.
Avoid the costs of service delivery problems without both human cost and application unavailability cost.
Prevent Performance Problems
Predict and Prevent many IT issues without incurring typical false positive and false negative issues.
Benefits
Automatically quantify risks in the z/OS infrastructure for peak workloads or configuration issues prior to production impact being felt by application end-users. Go beyond KPI to KRI (Key Risk Indicators) root cause monitoring.
Continuous Health Assessment of application and infrastructure stress; assesses millions of metrics using context-specific expert knowledge and statistical techniques.
Continuous Health Assessment of application and infrastructure stress; assesses millions of metrics using context-specific expert knowledge and statistical techniques.
Resolve Issues Quickly
Accelerate Mean Time To Resolution for unpredictable problems with AI-augmented diagnosis.
Benefits
Rapidly identify where problems are occurring with infrastructure wide exception (anomaly) tables, intelligent navigation through the data from big picture to extremely granular levels, automated compare of time periods, and more.
See and understand what applications are affected, what part of the infrastructure, what time frames, and get clues as to probable cause.
See and understand what applications are affected, what part of the infrastructure, what time frames, and get clues as to probable cause.
Flexible Deployment and Monitoring

In the Cloud
Cloud based deployment can be accessed from everywhere in the world and is easy to share with colleagues

Services & Support
Take advantage of IntelliMagic's experienced performance experts for standalone custom services or daily monitoring

On Premise
Install the software on premise and use it offline for total control of your installation
Supported Tape Systems
IntelliMagic Vision supports native and virtual z/OS attached tape from many different vendors:
- IBM TS7770, IBM TS7760, IBM TS7740, IBM TS7720
- EMC DLm
- Oracle StorageTek VSM
- IBM VTF Mainframe
- Oracle StorageTek Physical Tape Solutions
- Luminex Mainframe Virtual Tape Solutions
All major tape management software catalogs are supported: CA1, RMM, TLMS, Control-T, and Zara.
The virtual tape library statistics are supported for all models of IBM TS7700 family using BVIR activity records and for Oracle StorageTek virtual tape. For EMC DLm and IBM VTF Mainframe support for the native SMF data is available.
Continue Learning with These Resources
Brochures and Datasheets
Connect With an Expert
Discuss your technical or sales-related questions with our mainframe experts today