
Did you know you could be at risk of a performance meltdown while you still have plenty of front-end bandwidth?
An imbalanced front-end can cripple the performance of your IBM SVC system. An imbalanced front-end is another way of saying that too much workload is handled by too few ports. This leads to buffer credit shortages, increases in latency, and low throughput. It is very easy to create imbalances within an IBM SVC system’s front-end, and it can be fairly difficult to see it happening without the proper tools. To be fair, this also happens on other vendor’s hardware but that is a topic for another day.
The IBM SVC virtualizes heterogeneous back-end block storage. It scales from one to four I/O groups, each supporting up to 2048 volumes. Each node contains between four and eight ports. Best practice dictates that each host shall utilize two Host Bus Adapters (HBAs) for failover. Each of the host’s HBAs should be zoned to each node within an I/O group, across at least two paths per node, on alternating fabrics as demonstrated in Figure 1. This provides redundancy on fabric links, nodes, and node ports.
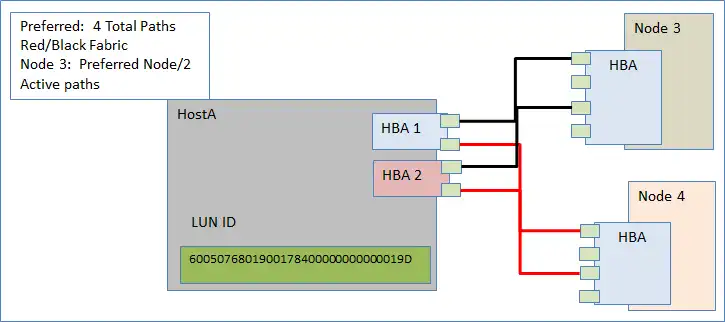
Figure 1: IBM SVC block storage
Within the I/O group, each host’s volumes are assigned a preferred node from a load balancing perspective in a round-robin fashion. Not all host multi-pathing software honors the preferred node. This is discussed in more detail below. The purpose of this “spreading of the volumes” is to provide a rough mechanism for balancing the load across the nodes and ports within an I/O group, a node, and the node’s ports.
While this is not groundbreaking news, I continue to see very intelligent people running production environments with significant imbalances on the front-end and limited visibility into the state of the imbalance, the reasons why it got there, the best corrective actions, and the processes for avoiding it in the future.
Follow the steps below and see how IntelliMagic Vision can identify the issues and help you avoid them in the future.
Step 1: Identify Front-end Imbalance
With IntelliMagic Vision we use balance charts to get visibility into I/O Group, Node, and Port imbalances as shown in Figure 2:
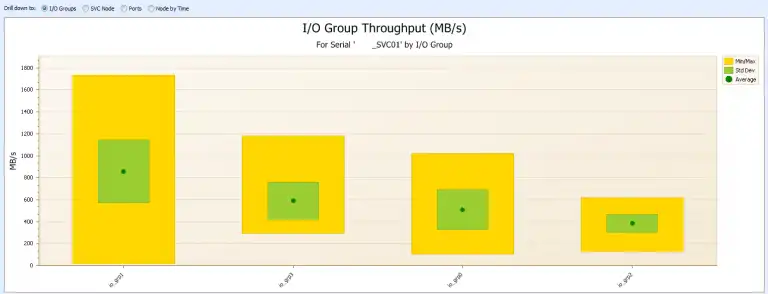
Figure 2 shows an imbalance between the I/O groups. IO_GRP1 carries the majority of the workload. Once you have identified such an imbalance at the I/O group level you can drill down to the Nodes and see if there is an imbalance at the node level as shown in Figure 3:
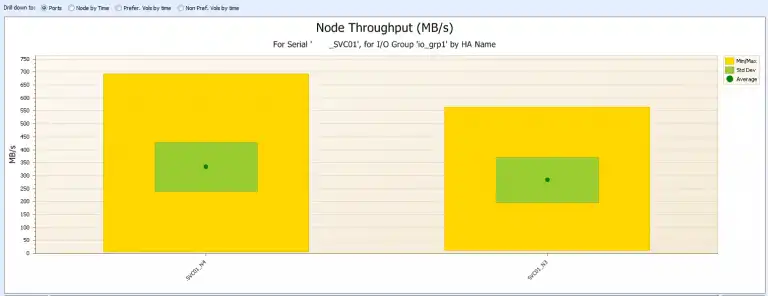
SVC01_N4 has a slightly higher workload than SVC01_N3 but this slight imbalance may still be acceptable. Still, it is wise to drill down even further to see if the port workloads are properly balanced, as shown in Figure 4:
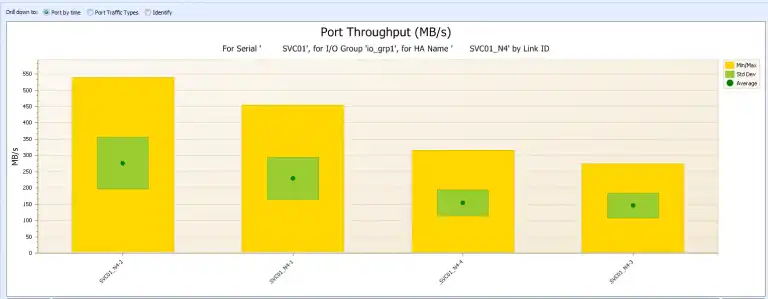
Port SVC01_N4-2 has an average of 276 MB/sec while SVC01_N4-3 has an average of only 143 MB/sec. Clearly there is an imbalance in the way the workload is distributed. Why is such an imbalance problematic? This is because it limits the amount of work that the entire cluster can do to the most constrained component, in this case port SVC01_N4-2.
Step 2: Identify how the imbalance occurred.
An imbalance can happen for several reasons:
- A host is honoring the preferred node setting but the host’s workload is imbalanced across its volumes. This is typical in a database environment where you have some LUNs dedicated to some highly active data tables, others dedicated to temp space, and yet others for logs. This will result in a workload that is not evenly balanced across the LUNs; weakening the effectiveness of the round-robin algorithm.
- Improper zoning can result in all requests from one host coming through a single node within an I/O group.
- Improperly configured host multi-pathing software can result in a situation where all access requests occur on a single path.
Step 3: Identify the best corrective action
The best action will follow logically from the root cause identified in Step 2:
- If this is an imbalance due to workload differences, modify the preferred node setting for individual volumes to redistribute the workload across the nodes more evenly. This is a non-disruptive change.
- If the imbalance is due to improper zoning, fix the zoning to spread the I/O workload across both nodes within an I/O group such that the overall load is balanced.
- If the imbalance is due to improperly configured multi-pathing software, optimize the multi-pathing software to honor the preferred node setting which gives the admin the control to do the balancing. In the case of VMWare use round-robin which distributes the I/Os across the available paths. A round-robin access scheme may be less desirable than using a preferred path to each volume, but it surely is much better than the serious performance issues caused by an imbalanced front-end.
Step 4: Be pro-active and avoid future imbalances
- Review balance charts on at least a weekly basis in order to have a firm grasp on your current workload balance.
- When adding new hosts to an environment follow the same process each time:
- Review performance loads across the I/O groups
- Leverage to the least utilized I/O group
- Assess new hosts as part of recurring baseline review in order to ensure continued balance in the environment.
In addition to the steps above, recent enhancements in both hardware and software allow for the SVC ports to be dedicated to specific uses such as:
- Host to SVC traffic
- SVC to back-end storage traffic
- Replication traffic
This provides you with further options when distributing workloads across the available resources. In general, we advise to dedicate replication traffic to specific ports. I discuss how to choose the best replication technology in this blog.
In conclusion: while imbalances are common, balancing the front-end is important and not excessively difficult.
This article's author
 Brett Allison
Brett Allison Related Resources
Noisy Neighbors: Discovering Trouble-makers in a VMware Environment
Just a few bad LUNs in an SVC all flash storage pool have a profound effect on the I/O experience of the entire IBM Spectrum Virtualize (SVC) environment.
Improve Collaboration and Reporting with a Single View for Multi-Vendor Storage Performance
Learn how utilizing a single pane of glass for multi-vendor storage reporting and analysis improves not only the effectiveness of your reporting, but also the collaboration amongst team members and departments.
A Single View for Managing Multi-Vendor SAN Infrastructure
Managing a SAN environment with a mix of storage vendors is always challenging because you have to rely on multiple tools to keep storage devices and systems functioning like they should.
Request a Free Trial or Schedule a Demo Today
Discuss your technical or sales-related questions with our availability experts today