
Time is Not Always on Your Side
In the 1960s the Rolling Stones had a hit song called “Time is On My Side”.
Don’t you wish it really was?
Too often in our jobs and personal life time seems to be the enemy. Too much to do and too little time is the mantra for the modern world.
Time is a Key IT Metric
If you work in IT, time is a key metric that we often must measure and track. How long did that job run? What is my I/O response time? How much time before I run out of capacity? How far behind is my asynchronous replication?
That last question can be critical, especially if you work for a financial company. There are frequently regulatory requirements on how far behind your replication can become without penalty. And in the event of a site switch due to a disaster or outage, do you want to explain why several high dollar value transactions are now lost?
Asynchronous Data Replication
Asynchronous data replication predicates that your DR site is always a bit behind your primary storage. Your target for how far behind you can be is called your Recovery Point Objective or RPO.
With current asynchronous replication technologies, RPO may be anywhere from a few seconds up to about a minute depending on various factors. Some replication methodologies such as IBM XRC are designed to minimize RPO, but the tradeoff is that applications may be slowed down if throughput exceeds the replication capability.
Most peer-to-peer replication methodologies such as IBM Global Mirror (GM) or EMC Symmetrix Remote Data Facility Asynchronous (SRDF/A) prioritize application performance over replication currency. But if replication falls too far behind or stops altogether, you need to find out about it quickly and know what should be done to fix it.
How Can I Manage Replication?
Recently, we helped an EMC SRDF/A user that was having problems with their session suspending. At the time of the incident, they were unfortunately not using IntelliMagic Vision but were curious how it would have helped them both see and respond to it if they did have IntelliMagic Vision.
They sent us the appropriate SMF data from the time frame when the problem occurred and asked for our analysis. We loaded one month of data into IntelliMagic Vision and here were our findings.
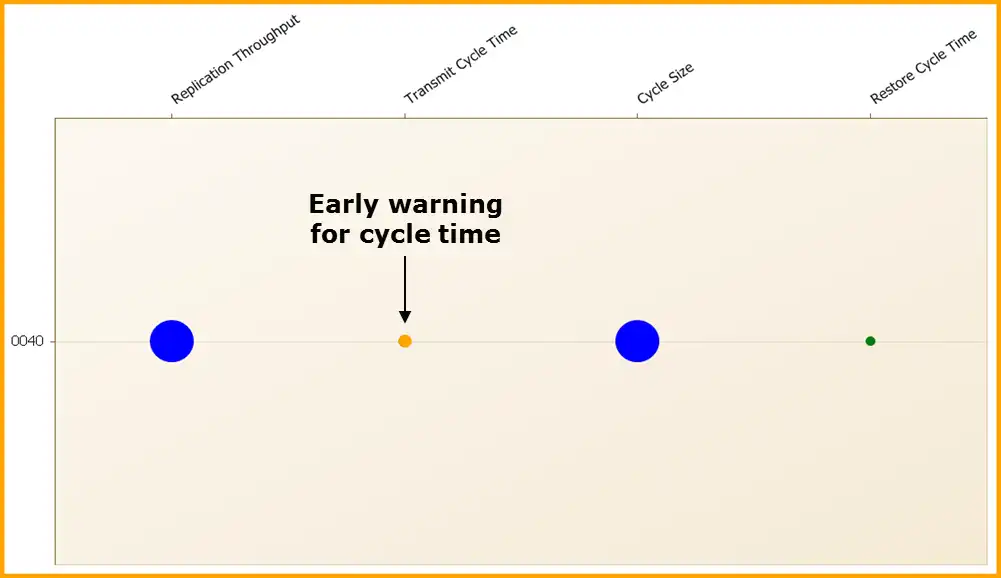
Looking at the SRDF/A dashboard in Figure 1, the first thing we noticed was that indeed IntelliMagic Vision predicted that there was an issue with the SRDF/A Transmit Cycle Time a full two days before the outage. If prompt action had been taken, perhaps the outage could have been avoided altogether.
What is the Trend?
Trends can tell you a lot about where things are going. Figure 2 shows the rating over time for the SRDF/A cycle size. Cycles size is an indicator of the amount of data that must be transferred to the remote site during a single SRDF/A cycle.
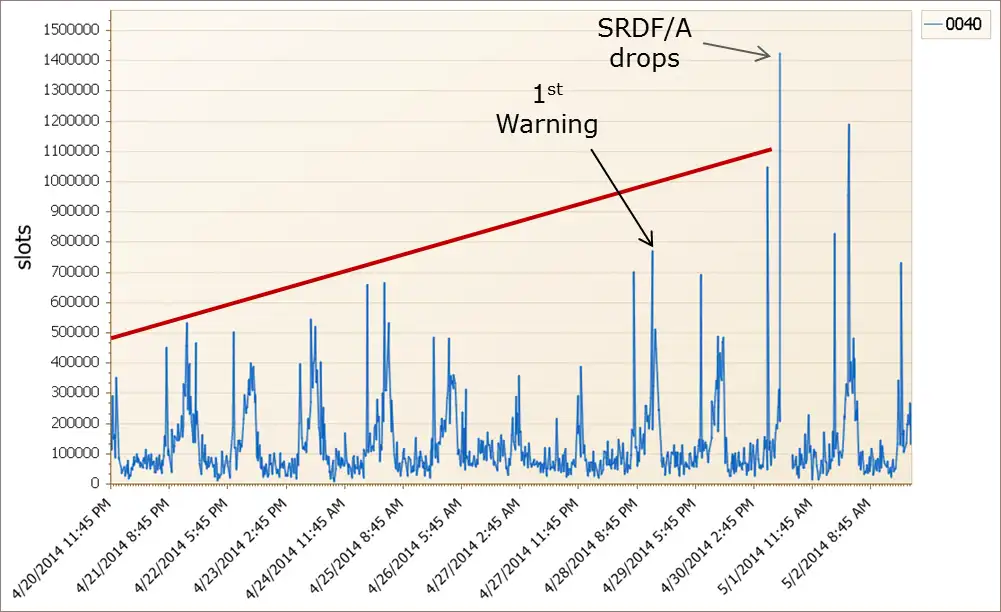
Figure 2 – Cycle Size Trend
You can see periodic spikes in the cycle size and those spikes were growing over time. Keeping an eye on this trend with IntelliMagic Vision would have provided an even earlier warning that something had changed.
What is the Source?
There were two primary VMAX disk storage systems (DSS) in the SRDF/A session. Were the spikes in data throughput coming from one of the VMAX systems or were they both contributing equally? Figure 3 below shows that the replication activity is coming primarily from one VMAX (EMC000002). In fact, the session dropped right after a big spike in writes from that DSS. We have found the culprit!
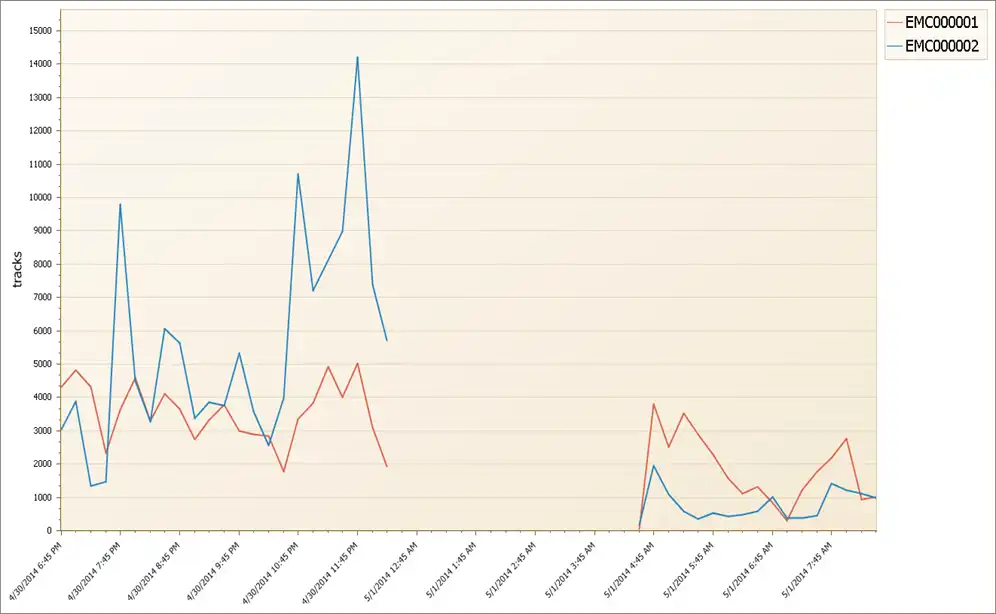
Figure 3 – HA Writes by DSS Name
Why is this Happening?
We looked at the “Write Pending High-Water Mark” over time and found that whenever it exceeded 1.4 million slots, the session dropped. The large spike in write activity would consume too much cache on the primary DSS. Once it hit the threshold, the VMAX caused SRDF/A to suspend.
What is the Solution?
One possible solution is implementing delta set expansion. This is an SRDF/A feature that puts replication data on disk if too many slots are consumed in cache. However, this may lengthen your RPO and perhaps is not the preferred solution.
A better fix is to simply rebalance the two VMAX DSS’s. Using IntelliMagic Vision, it was found that most of the imbalance was due to a single storage group. By changing the allocations of that storage group, the suspends were easily eliminated.
Is it Time to Improve Your Availability Intelligence?
If you would like the intelligence needed to avoid outages like this, consider IntelliMagic Vision. With IntelliMagic Vision you truly will be singing “Time is on my side, yes, it is”!
This article's author
 Lee LaFrese
Lee LaFrese Share this blog
Related Resources
What’s New with IBM DS8900F?
Release 9.1 for the DS8900F storage array contains numerous product improvements that should be interesting and useful to any shop that has DS8900F installed or is considering it.
Banco do Brasil Ensures Availability for Billions of Daily Transactions with IntelliMagic Vision
Discover how Banco do Brasil enhanced its performance and capacity management with IntelliMagic Vision, proactively avoiding disruptions and improving cross-team collaboration.
IntelliMagic Vision Support for Hitachi VSP SMF Records from Mainframe Analytics Recorder
Learn how to gain insight into the health of the Hitachi Virtual Storage Platforms VSP 5000 series and VSP F/G1x00 storage systems using the SMF records created by the Hitachi Mainframe Analytics Recorder.
Book a Demo or Connect With an Expert
Discuss your technical or sales-related questions with our mainframe experts today