
The mainframe platform produces an incredibly rich set of metrics that exceeds any other. This measurement data can provide a tremendous learning opportunity, both for how various elements of the z/OS ecosystem operate in general, and specifically how those technologies are actually operating in one’s own environment.
For example, (e.g., PCIe cards supporting zEDC hardware compression), compared to others which show some level of variations (e.g., utilizations of cryptographic co-processor adapter cards).
Learning Value Applies to Both Ends of the Expertise Spectrum
This learning value applies across the entire spectrum of expertise. For novices who are either relatively new to the platform or who are exploring outside their areas of specialization, learning is accelerated through having easy access to SMF data.
To share a personal example as someone who until recently had minimal exposure to cryptography, having easy visibility into those metrics jump started my learning. I was quickly introduced to the wide variety of types of crypto operations, and found that sizable disparities may exist between the amounts of data being operated upon by various crypto operations.
Experts can also deepen their understanding through examining data. I recently attended sessions at the IBM TechU conference in Berlin that were presented by Martin Packer, an IBM performance specialist from the UK. He presented three very informative sessions that were all based on a single idea, namely, “see where the data leads us and what it teaches us.” He applied that to three different areas: DDF, Coupling Facility, and CPU performance at the individual CP level.
For both novices and experts, learning is greatly expedited by having easy visibility into SMF data, ideally with minimal effort expended to mine the data, so that all the time can be spent exploring, analyzing, and learning. And recapping an earlier point, no matter what our areas of specialization, it is likely that we are all novices in many other aspects of the z/OS infrastructure where we could quickly learn through easy visibility into SMF data.
Barriers to Unleashing the Learning Value of SMF Data
Unfortunately, there are significant barriers to unleashing the learning value of this SMF data. In our recent webinar, How to Learn (Almost Anything) From RMF & SMF Data, 92 mainframe performance professionals from across a broad spectrum of industries responded to a poll asking them to identify barriers to exploring and learning from SMF data they were currently experiencing. The results of this poll appear below.
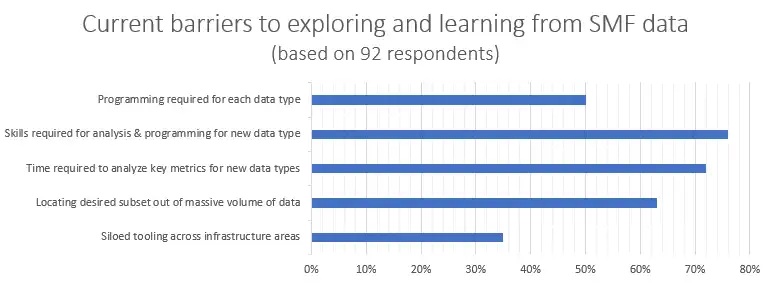
Current Barriers to Exploring and Learning from SMF Data – Poll Responses
- Programming required for each data type [50%]
- Skills required for analysis and programming for new data types [76%]
- Time required to analyze key metrics for new data types [72%]
- Locating desired subset out of massive volumes of data [63%]
- Siloed tooling across infrastructure areas [35%]
This poll confirmed that a majority of sites currently experience several significant obstacles to unlocking the vast learning potential of SMF data. Let’s examine each of these barriers.
Barrier 1: Programming Required for Each Unique Set of Metrics
Each infrastructure component has its own unique set of metrics, and legacy solutions typically require programming for each data type. This development effort is not simple, even with templates provided by tooling like MXG that helps deal with the complexity of record structures. A significant time investment is still required:
- To analyze the available metrics;
- To select the subset of metrics worthy of high-level focus;
- To identify ranges of acceptable values for those key metrics, outside of which further analysis is warranted;
- To develop reporting that supports lower-level analysis when that may be required.
Barriers 2 & 3: Time and Skills Required
Compounding this barrier of required programming, with today’s reduced staff sizes and increased workloads, it is becoming increasingly difficult for teams to devote the time required for this in-house development. And advanced skill sets are required to perform these analysis and programming tasks, skills which are becoming increasingly difficult to find with the pace of retirements of tenured staff currently occurring across the mainframe industry.
Evidence of the magnitude of these time and skills challenges is clearly seen by the prevalence of sites who have little or no reporting on technologies that have been introduced to the mainframe platform in recent years (e.g., zEDC hardware compression).
Barrier 4: Gaining Insights from Massive Volumes of Data
Additionally, the massive volumes of SMF data in areas like CICS transactions and Db2 accounting are often a big inhibitor to gaining insights from the data.
With a “haystack” made up of records containing 400 metrics for each of millions of CICS transactions, how do you uncover the proverbial “needle” of insight?
Trying to sift through gigabytes if not terabytes of SMF data produced daily at mainframe sites makes finding insights extremely difficult. It is clear this cannot be accomplished by analysts sifting through tabular data presented in large collections of static reports.
Barrier 5: Siloed Tooling Across Infrastructure Areas
A final barrier to learning across the z/OS infrastructure is the prevalence of siloed tooling with interfaces and formats unique to each area.
People who have specialized in a discipline for decades may develop skills to locate the values of key metrics in their own areas from static, tabular reports. But the learning curve for newer analysts as well as those seeking to explore and learn in areas outside their discipline is steep, because they must first learn how to generate and navigate the reporting tooling exclusive to that area.
To be continued…
We are just getting started with this subject. Imagine how much and how quickly you could learn if you could explore the metrics produced by technologies that are outside your previous areas of expertise leveraging a common intuitive user interface used across the entire mainframe platform (as opposed to the siloed tooling that is prevalent today).
Also, consider the insights you could rapidly gain about how your environment is actually operating if based on findings from the current view you could dynamically drill down into a subset of the data to focus your analysis. And if that line of analysis proved unfruitful, you could immediately begin investigating a different hypothesis by selecting another metric by which to drill into the data.
In future blogs in this series I will consider the types of capabilities that facilitate rapid learning from and effective analysis of SMF data, along with learning examples from metrics that are less well known or often receive less attention from in-house developed reporting.
This article's author
 Todd Havekost
Todd Havekost Share this blog
Related Resources
What's New with IntelliMagic Vision for z/OS? 2024.2
February 26, 2024 | This month we've introduced changes to the presentation of Db2, CICS, and MQ variables from rates to counts, updates to Key Processor Configuration, and the inclusion of new report sets for CICS Transaction Event Counts.
Expanding Role of Sub-Capacity Processors in Today's Mainframe Configurations | Cheryl Watson's Tuning Letter
In this reprint from Cheryl Watson’s Tuning Letter, Todd Havekost delves into the role of sub-capacity processors in mainframe upgrades, providing insights on transitioning to a more efficient CPC.
Why Am I Still Seeing zIIP Eligible Work?
zIIP-eligible CPU consumption that overflows onto general purpose CPs (GCPs) – known as “zIIP crossover” - is a key focal point for software cost savings. However, despite your meticulous efforts, it is possible that zIIP crossover work is still consuming GCP cycles unnecessarily.
Book a Demo or Connect With an Expert
Discuss your technical or sales-related questions with our mainframe experts today