
With the recent release of “Alice Through the Looking Glass” (my wife is a huge Johnny Depp fan), it seems only appropriate to write on a subject epitomized by Alice’s famous words:
“What if I should fall right through the center of the earth … oh, and come out the other side, where people walk upside down?” (Lewis Carroll, Alice in Wonderland)
Mainframe Peak Utilization
Along with the vast majority of the mainframe community, I had long embraced the perspective that running mainframes at high levels of utilization was essential to operating in the most cost-effective manner.
Based on carefully constructed capacity forecasts, our established process involved implementing just-in-time upgrades designed to ensure peak utilization’s remained slightly below 90%.
MSU Consumption Spikes
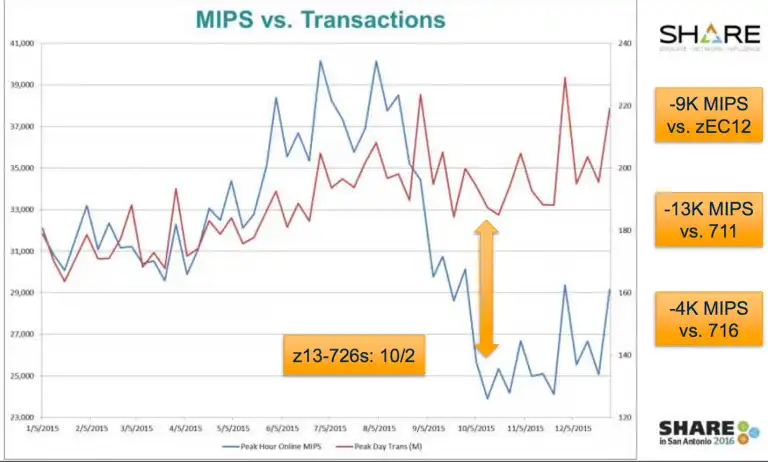
It turns out we’ve all been wrong. After implementing z13 processor upgrades and observing MSU consumption spike up sharply, I learned first-hand the dramatic impact processor cache utilization has on delivered capacity for z13 models.
When processor cache is optimized, our high-powered mainframe processors remain productive actively executing instructions, rather than unproductively burning cycles waiting for data and instructions to be staged into the Level 1 cache.
Increasing the amount of work executing on processors effectively dedicated to a single LPAR (“Vertical High CPs”) reduces the frequency of multiple LPARs with disparate workloads competing for the same processor cache, which is particularly detrimental to processor efficiency and throughput.
MLC Savings of Millions of Dollars
In my specific experience, operating at percent utilizations in the 30’s instead of the upper 80’s reduced MSU consumption by 30% (13,000 MIPS!), resulting in year-after-year Monthly License Charge (MLC) software savings of millions of dollars annually.
[You can download the presentation notes with more details on how this was accomplished here]. The economics of one-time hardware acquisitions creating “forevermore” annual software savings of this magnitude are readily apparent.
This experience ultimately turned all my concepts of mainframe capacity planning upside down, because processor cache operates far more effectively at lower utilization levels. Like Alice Through the Looking Glass, I’m now walking upside down with new insights!
Read my follow-up to this blog to learn how other mainframe sites have identified 7-figure annual MLC reduction savings.
How to use Processor Cache Optimization to Reduce z Systems Costs
Optimizing processor cache can significantly reduce CPU consumption, and thus z Systems software costs, for your workload on modern z Systems processors. This paper shows how you can identify areas for improvement and measure the results, using data from SMF 113 records.
This article's author
 Todd Havekost
Todd Havekost Share this blog
Related Resources
Why Am I Still Seeing zIIP Eligible Work?
zIIP-eligible CPU consumption that overflows onto general purpose CPs (GCPs) – known as “zIIP crossover” - is a key focal point for software cost savings. However, despite your meticulous efforts, it is possible that zIIP crossover work is still consuming GCP cycles unnecessarily.
Top ‘IntelliMagic zAcademy’ Webinars of 2023
View the top rated mainframe performance webinars of 2023 covering insights on the z16, overcoming skills gap challenges, understanding z/OS configuration, and more!
Mainframe Software Cost Savings Playbook
Learn how to effectively reduce mainframe costs and discover strategies for tracking IBM software licensing metrics to minimize expenses.
Book a Demo or Connect With an Expert
Discuss your technical or sales-related questions with our mainframe experts today