
Software is the primary component in today’s world that drives mainframe expenses, and software expense correlates to CPU consumption in almost all license models. In this blog series, I cover several areas where possible CPU reduction (and thus mainframe cost savings) can be achieved. In the first blog, I covered Processor Cache optimization opportunities. In this blog, part 2 of Infrastructure Opportunities for CPU reduction, I will cover several additional Infrastructure opportunities:
- Moving work outside the monthly peak R4HA interval
- Reducing zIIP overflow
- Reducing XCF message volumes
- Leveraging Db2 memory to reduce I/Os
As discussed in the previous blog, optimization opportunities commonly found in the infrastructure often have two significant advantages over opportunities applicable to individual address spaces or applications:
- They can benefit all work or at least a significant portion of work across the system.
- They can often be implemented by infrastructure teams without requiring involvement of application teams, which understandably often have different priorities.
In the ideal situation, you can get IT-wide buy-in and commitment to succeed in identifying and implementing CPU reduction opportunities. But even if you don’t have that, you can still implement many of these infrastructure changes.
1) Move Work Outside Monthly Peak R4HA Interval
In addition to sites operating primarily under a monthly peak rolling 4-hour average (R4HA) interval license model, it is common for companies that have adopted consumption-based models to still have some software that is managed with peak R4HA terms. So many readers may find the potential of moving work outside the monthly peak interval to be a cost-saving opportunity worth investigating, particularly when those peak intervals occur at predictable times during the month.
Some sites have prime shift peaks set by online workloads, often on a particular day of the week. In other cases, monthly peaks occur during the night shift and are driven by batch, often at month-end. Opportunities for savings from workload shifting can arise when predictable monthly peaks combine with a sizable delta between that peak and typical activity levels (as shown in Figure 1).
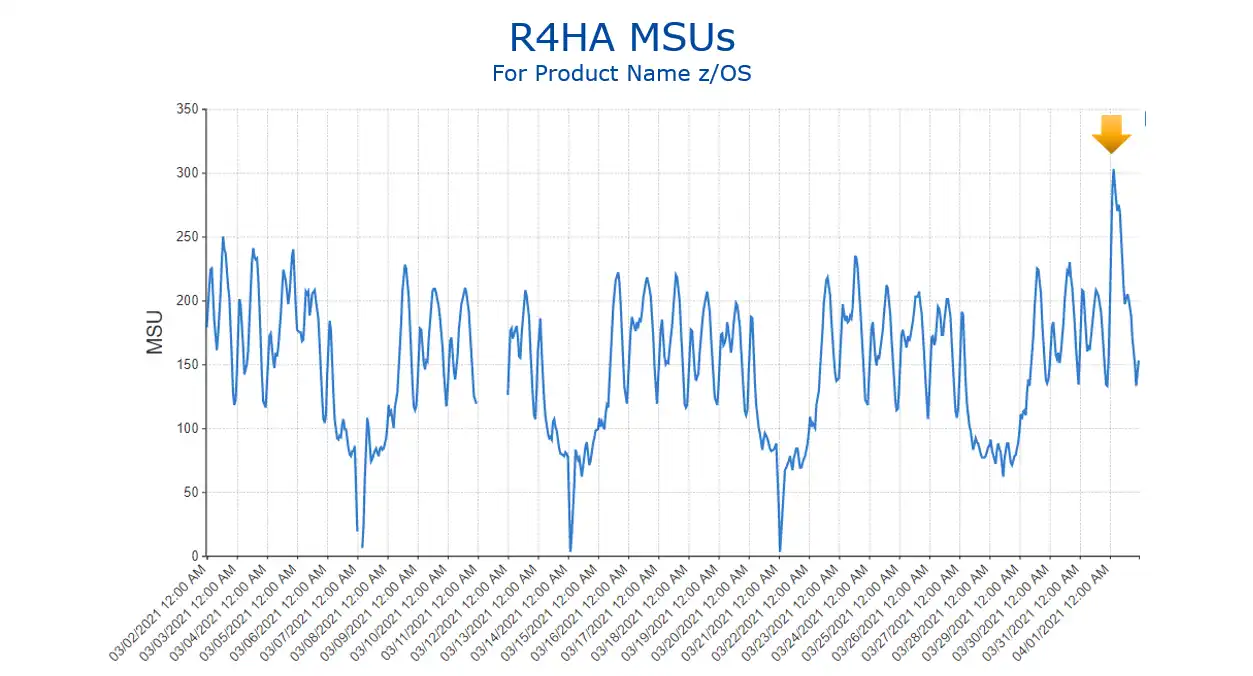
Figure 1: R4HA MSUs
Started Task Maintenance Activities
One common opportunity for time shifting arises from regularly scheduled started task maintenance activities such as those performed by HSM or job schedulers.
The time band chart in Figure 2 captures one such scenario, with a narrow range of CPU on the 10th and 90th percentile days for the selected month indicating a highly repeatable daily surge in CPU consumed at the 1300 hour present by the job scheduler. If this hour commonly falls in the monthly peak 4-hour interval, rescheduling that daily maintenance represents a potential savings opportunity.
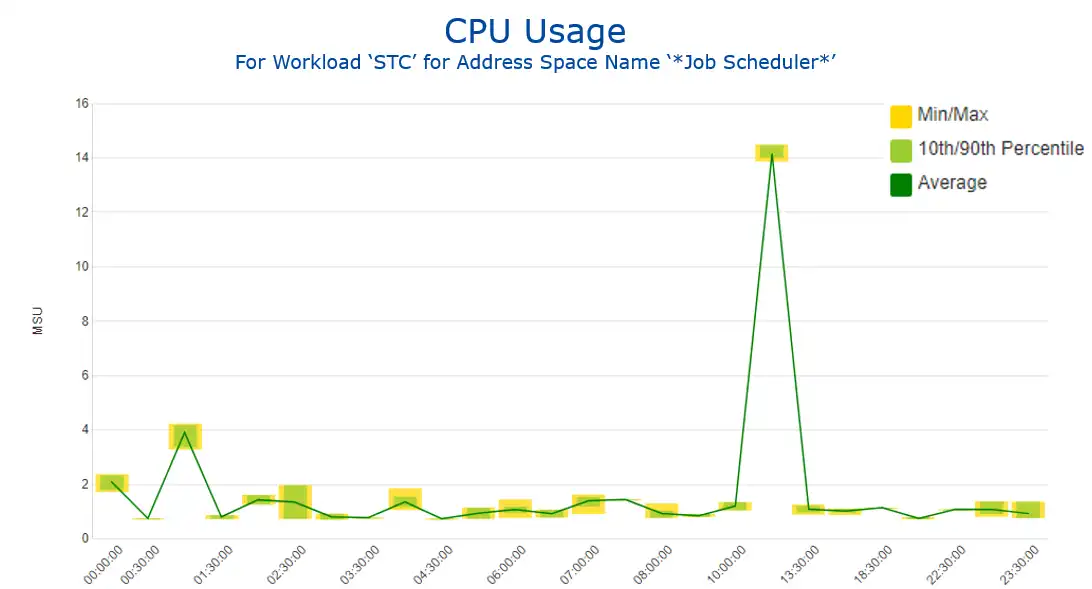
Figure 2: CPU Usage – Job Scheduler
Batch During Online Peaks
In contrast to online transaction-oriented workloads that must be serviced immediately, batch workloads often have some flexibility in terms of when they execute or at least the CPU intensity they receive.
For sites with online monthly peaks, this can lead to opportunities to examine batch executing during those online hours. Since batch typically executes in service classes with lower WLM importance levels (e.g., 4, 5, Discretionary), the view shown in Figure 3 can help quantify the size of the potential opportunity.
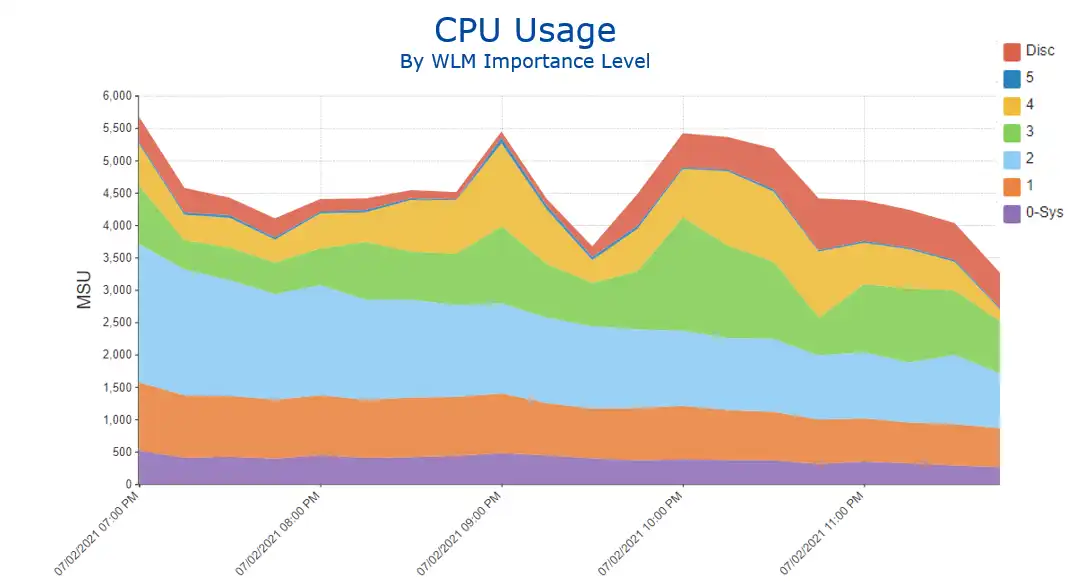
Figure 3: CPU Usage by WLM Importance Level
Peaks During Month-End Batch Processing
For sites with monthly peaks occurring during month-end processing at night, analysis at the address space level will usually be required to identify jobs that could be candidates for being scheduled outside that peak interval.
Figure 4 represents one such view, initially filtered by address spaces executing in service classes classified as discretionary to WLM.
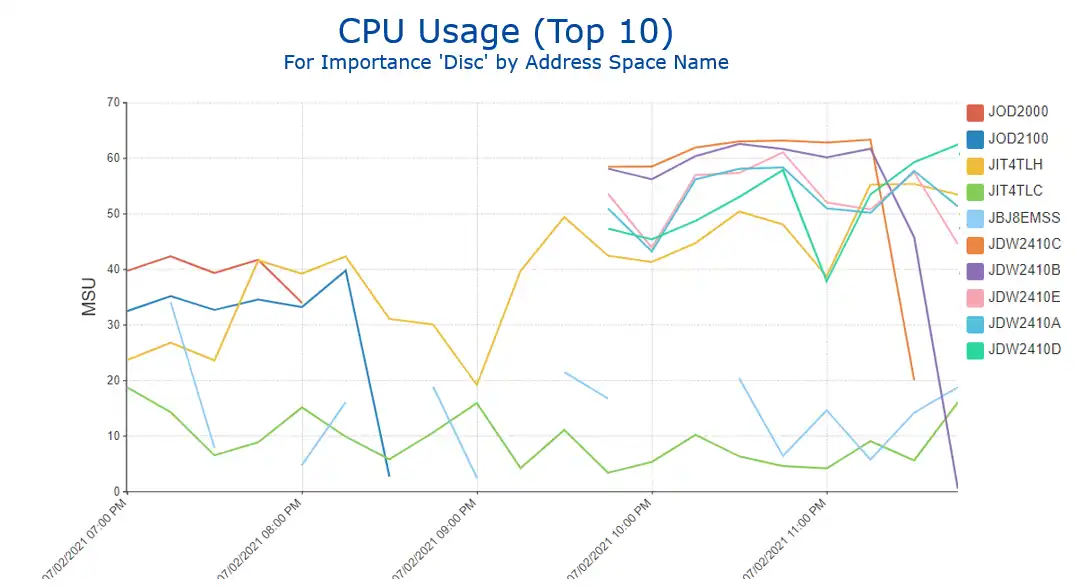
Figure 4: CPU Usage (Top 10) – WLM Importance Level of Discretionary
2) Reduce zIIP Overflow
Another infrastructure-driven area that can help achieve cost savings is reducing zIIP-eligible CPU that overflows onto general purpose CPs (GCPs) where it is chargeable for software expense.
As with other potential opportunities, an initial step is to quantify the size of the opportunity. The monthly view of zIIP overflow consumption MSUs by workload shown in Figure 5 indicates that the Db2 workload (in yellow) is the primary driver of the overflow, with an amount varying between 15K to 35K consumption MSUs per month.
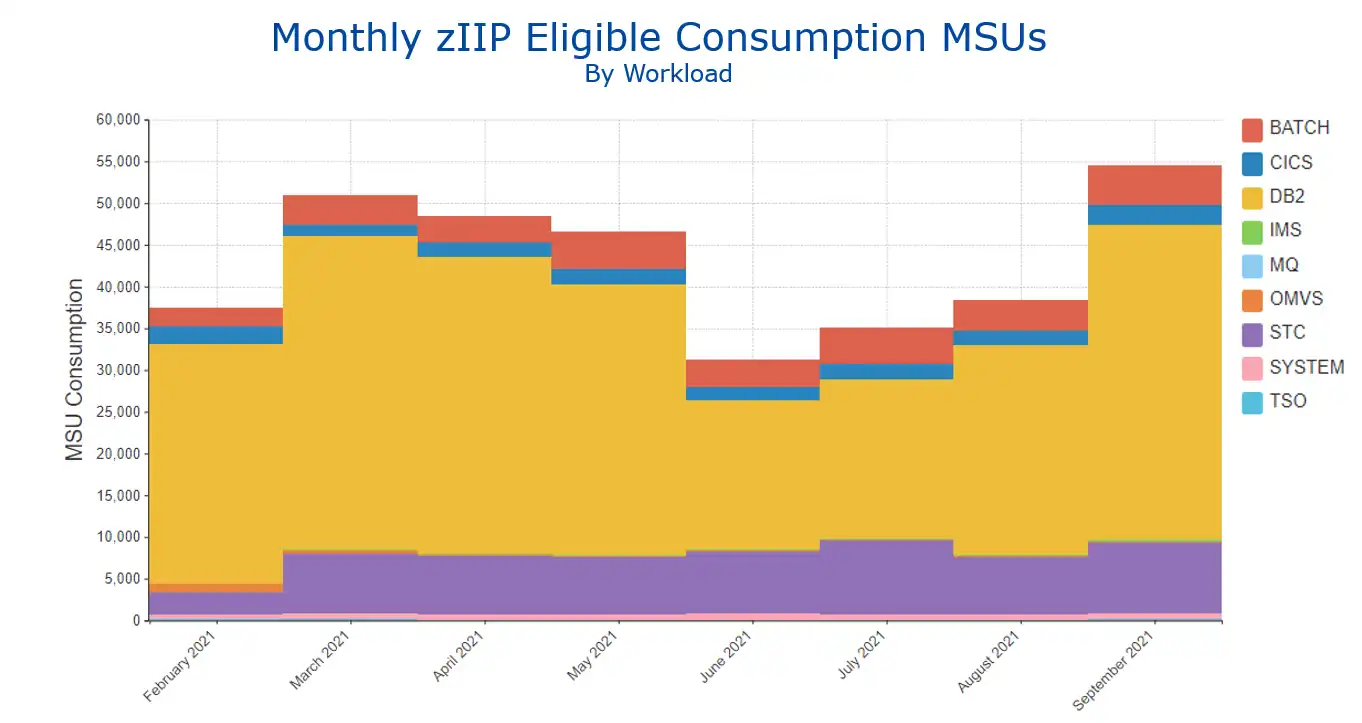
Figure 5: Monthly zIIP Eligible Consumption MSUs by Workload
Assuming that is worth pursuing as a percentage of overall consumption, analysis would continue by drilling into the details that Db2 workload. In this scenario, the overflow work is coming almost entirely from a single service class which consists of DDF work.
At that point, analysis would likely proceed by moving over into Db2 Accounting (SMF 101) data and viewing the DDF zIIP overflow CPU by Authorization ID (a common way to analyze DDF work in Db2). That view (Figure 6) shows five auth IDs that are responsible for almost all the spillover work, and also shows a very consistent pattern of big spikes around midnight each day.
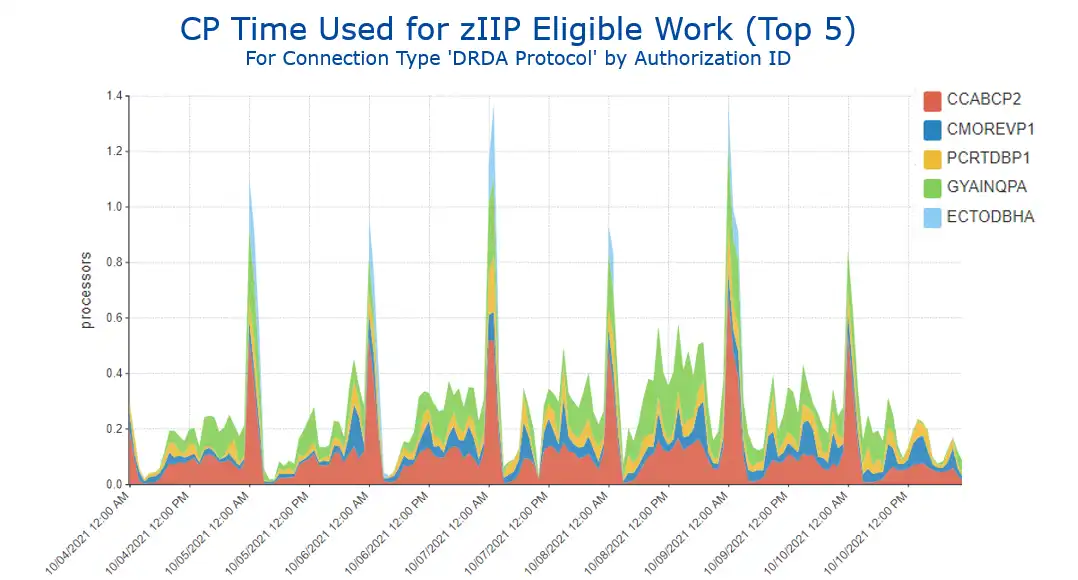
Figure 6: CP Time Used for zIIP Eligible Work (Top 5) by Authorization ID
That raises the question as to whether this spillover is because the zIIP CPs are very busy or is due to a very spikey arrival rate. A view of zIIP utilization (not shown) indicates the zIIPs are not overly busy, so that points to arrival rate as the driver of this spillover.
One approach for further analysis within Db2 would be to examine the rate of getpages, a key measure of Db2 activity. Viewing that data for the DDF workload (Figure 7) shows a huge spike (over 2 million per second) every day at midnight for the top auth ID (in red), validating that the spillover from zIIPs to GCP is indeed due to an extremely spikey arrival rate
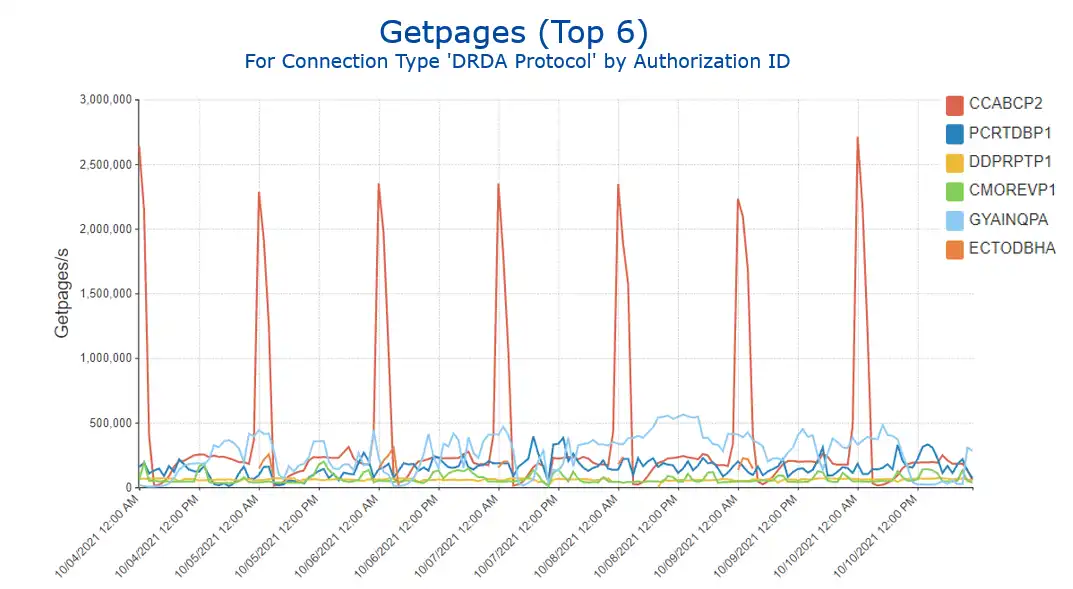
Figure 7: Getpages by Authorization ID
So if you are in a consumption-based software license model, or in a peak R4HA model with monthly peaks that include midnight, you would want to explore if the work driven by that auth ID could afford to wait the few milliseconds until a zIIP CP would likely become available. If so, you could reduce this spillover by assigning this work to a WLM service class defined with ZIIPHONORPRIORITY=NO.
3) Reduce XCF Message Volumes
As sysplexes have evolved, the amount of communication and sharing across the systems has increased dramatically. This intra-sysplex communication is facilitated by two key components, the Coupling Facility (CF) that maintains shared control information (e.g., database locks), and XCF (Cross-System Coupling Facility) that facilitates point-to-point communication by sending messages to other members of an application group. CF metrics are relatively well known, but XCF metrics (from RMF 74.2 records) have typically received less visibility.
XCF is exceptionally good at reliably delivering messages at high volumes. I have seen volumes far exceeding one million messages per second. But it so good at its job that it is often ignored.
The problem with that is that sending and receiving high volumes of messages drives CPU, both for XCFAS and the address spaces processing the messages. So system configuration decisions that generate unnecessarily high XCF message volumes can waste a significant amount of CPU.
The reader is referred to my blog “Leveraging XCF Message Activity for CPU Efficiency: Integrated Visibility into SMF Data” for more information on identifying XCF groups driving large message volumes that represent potential CPU savings opportunities.
4) Leverage Memory to Reduce I/Os – Db2 Use of Large Frames
One underlying driver of numerous CPU reduction opportunities across infrastructure areas is leveraging memory to reduce I/Os, since memory accesses are far more CPU efficient (not to mention far faster) than the many operations required to perform I/Os.
As the biggest mainstream exploiter of large quantities of central storage, Db2 may represent your biggest potential source of CPU reduction opportunities from trading memory for I/Os.
Buffer Pool Tuning
Db2 buffer pool tuning typically represents the biggest opportunity for large scale memory deployment. Db2 industry experts present various buffer pool tuning methodologies, which utilize various criteria for identifying buffer pools which are top candidates to receive more memory, including Total Read I/O Rate, Page Residency Time, and Random BP Getpage Hit Ratio.
For more information on buffer pool tuning, see my “z/OS Memory and Db2 – A Match Made in Heaven” blog.
Using Large Frames to Back Buffer Pools with High Getpage Rates
But there is another incremental memory-related CPU opportunity with Db2 that goes beyond pool sizes. It involves using fixed large 1MB or 2GB frames to back buffer pools with high getpage rates. This can save CPU because large page frames make translations of virtual storage to real storage addresses more CPU efficient, reducing the CPU cost of accessing pages that are cached in the buffer pool.
IBM indicates measurable savings can be achieved when large frames are used to back buffer pools with getpage rates exceeding 1000 per second.
When a Db2 buffer pool is defined to be page-fixed and z/OS has 1MB fixed frames available, that buffer pool will be backed with 1MB large frames, resulting in CPU savings from more efficient address translations. A view like Figure 8 can be used to identify buffer pools with the highest getpage activity in a data sharing group and thus top candidates to leverage available large frames if available.
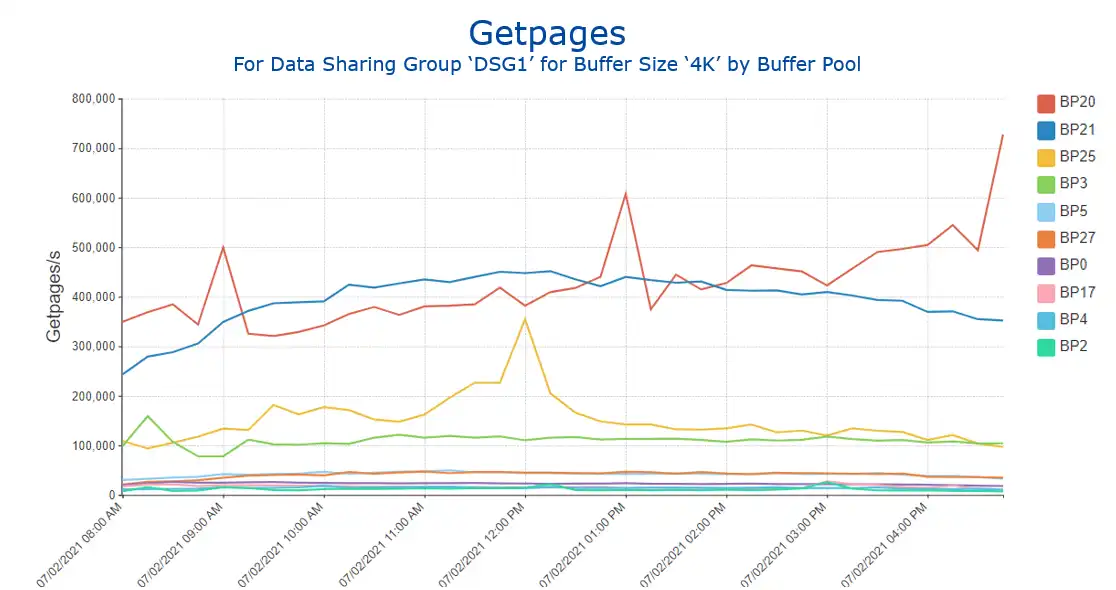
Figure 8: Getpages for 4K Buffer Pools for selected Data Sharing Group
In z/OS 2.3 IBM made significant enhancements to the flexibility with which z/OS manages large frames. The big enhancement that relates directly to this subject is that the 1MB LFAREA (large frame area) is now managed dynamically by z/OS, up to the size specified in IEASYSxx Parmlib member.
That storage is no longer reserved and set aside at IPL time as it was prior to 2.3. Thus, it can be allocated with some headroom and grown into as buffer pool sizes increase, which is particularly helpful since the LFAREA upper limit definition can only be changed with an IPL.
Since the LFAREA parameter can only be changed with an IPL, it needs to be managed carefully. It is a Goldilocks parameter; you want it to be “just right.” Too high can cause shortages of regular 4K pages for the rest of the system, likely seen initially in demand paging rate and possibly more severe symptoms. Too low and Db2 fails to gain the CPU efficiencies that large frames could provide.
The RMF metrics for managing fixed 1MB frames in the LFAREA are not complicated, but Db2 and z/OS teams will want to have good visibility into them. Figure 9 provides a view that brings together key metrics for a z/OS system.
- Total central storage allocated to the LPAR (in yellow)
- Size of the LFAREA (green)
- Fixed 1MB frames in use (red)
- Fixed 1MB frames available (blue)

Figure 9: Total Storage and 1MB Fixed Frames
So in this example, if some Db2 buffer pools have higher getpage rates and could make good use of additional 1MB frames, capacity exists without requiring an IPL.
Finding Mainframe Cost Savings Through Infrastructure-Wide Opportunities
CPU reduction is the primary means of attaining mainframe cost savings, and effective analysis is essential in identifying and evaluating potential CPU reduction opportunities. The first two blogs in this series have explained several items on this “menu” of common infrastructure-related CPU optimization opportunities.

Figure 10: Infrastructure Opportunities
Future iterations of this blog will present other avenues for potential savings applicable to specific address spaces. Many items on both lists may not represent opportunities in your environment for one reason or another. But I expect you will find several items worth exploring as potentially applicable which may lead to substantive CPU savings and with it reduced mainframe expense.
Combining great visibility into top CPU consumers and top drivers of CPU growth along with awareness of common opportunities for achieving efficiencies positions you for success as you focus your scarce staff resources on the most promising opportunities.
Ways to Achieve Mainframe Cost Savings
This webinar is designed to expand your awareness of ways sites have reduced CPU and expenses so that you can identify ones potentially applicable in your environment.
This article's author
 Todd Havekost
Todd Havekost Share this blog
You May Also Be Interested In:
Why Am I Still Seeing zIIP Eligible Work?
zIIP-eligible CPU consumption that overflows onto general purpose CPs (GCPs) – known as “zIIP crossover” - is a key focal point for software cost savings. However, despite your meticulous efforts, it is possible that zIIP crossover work is still consuming GCP cycles unnecessarily.
Top ‘IntelliMagic zAcademy’ Webinars of 2023
View the top rated mainframe performance webinars of 2023 covering insights on the z16, overcoming skills gap challenges, understanding z/OS configuration, and more!
Mainframe Software Cost Savings Playbook
Learn how to effectively reduce mainframe costs and discover strategies for tracking IBM software licensing metrics to minimize expenses.
Book a Demo or Connect With an Expert
Discuss your technical or sales-related questions with our mainframe experts today