
Back in 2011 I heard on the news about a flood in Thailand. I didn’t realize it, but that distant tragedy would have a huge impact on the infrastructure of the company I was working for at that time. What I didn’t realize was that at the time Thailand was the #2 producer of hard drives globally, and the flood would close factories and warehouses for weeks.
Enter Murphy’s Law…
During this period my team were retiring an array that was at the end of its service life as part of a months-long project. While it is normal for a storage array to have disk failures, we had a full-blown storm of failures that saw 11 nearline disks fail, with up to six failed disks at the same time.
As soon as the vendor was able to procure and replace a drive from a rapidly dwindling supply, another would fail on its heels because the extra I/O caused by disk rebuild activity was causing a domino effect that caused other disks in the tier to fail. Luckily, we were using a virtualized RAID 6 on our nearline tier, and none of the disks failed in such a manner that a single virtual RAID 6 set exceeded two failed elements.
Given the lengthy rebuild time of a 2TiB NL drive, my team and I had many sleepless nights until the array was healthy again, and we eventually weathered the storm. We were later told by the vendor that we had literally used all available suitable replacement drives in their supply chain for the southwestern US.
In Current News: Enter Global Supply Chain Disruptor
Besides having devastating effects on people’s personal lives, the coronavirus pandemic is a major global disruptor on many fronts, and supply chain is no exception. Its spread across the world, including Asian countries where most of the manufacturing takes place will particularly affect new HDD availability, but replacement SSDs could also have sparse availability.
This made me think not only about how to mitigate the risk posed by a lack of replacement disks but also the risk posed by supply chain disruptions in general.
Risk Mitigation for Supply Chain Disruptions
Talk to your vendors
Ask your account representative to verify that they will be capable of fulfilling those SLAs given the current situation.
If you have a maintenance agreement for your storage devices, there are typically guarantees for how many replacement parts they keep available both locally and regionally as well as SLAs for how quickly parts are to be replaced upon failure.
Ask your account representative to verify that they will be capable of fulfilling those SLAs given the current situation. Even if they will be unable to make a timely replacement, you’ll at least be aware the risk is there.
Where are you in your equipment’s life cycle?
Odds are most of the components in your storage array are original. This means that a good number of each type of disk have the same mean-time-to-failure and are thus likely to fail in bunches.
If a spinning disk tier routinely averages more IOPS than the manufacturer recommends, the service life of the disk will be decreased. This is a common problem with nearline disks. SSDs also wear over time.
Storage vendors provide information as to the number of failed cells or sectors that are present on a drive, allowing you to predict how many drives you have that are near failure. HPE 3PAR arrays, for instance, show the number of failed chunklets on a drive in the StoreServ Management Console (SSMC), and will proactively fail a drive when the 6th chunklet fails.
Monitoring how many drives are near failure and proactively replacing them before they fail can be a good strategy to prevent a disk failure storm. For example, if you have four NL disks that are at 5 failed chunklets, you could start proactively replacing them one at a time to prevent a storm of disk failures.
Have a look at the statistics for SFPs in your SAN switches to see if their light level is marginal, especially if your switches have few free ports or you don’t keep spare SFPs on-hand. SFP and fiber failures are usually presaged by alerts for increased CRC errors, invalid ordered sets, and signal failures. A good monitoring tool, such as IntelliMagic Vision, can make those errors apparent.
For example, Figure 1 below shows a switch port with a high number of invalid ordered set errors. Figure 2 shows a port with high invalid transmission word errors over time. Both indicate a need for further troubleshooting and likely a need for part replacement. If you think you are going to have supply chain issues, you may want to have them replaced.
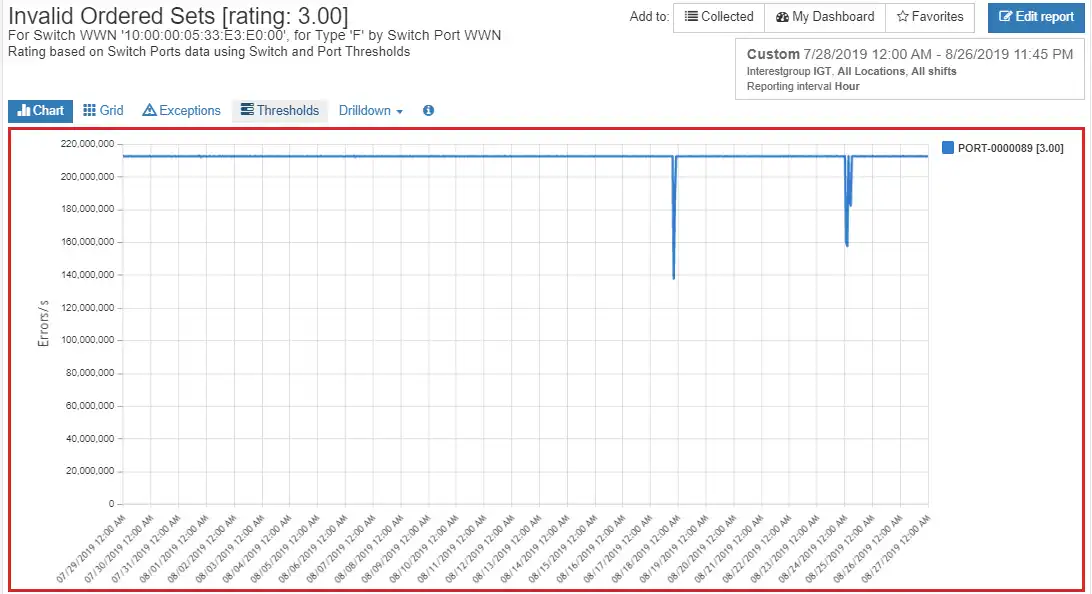
Figure 1: Switch port with high invalid ordered set errors
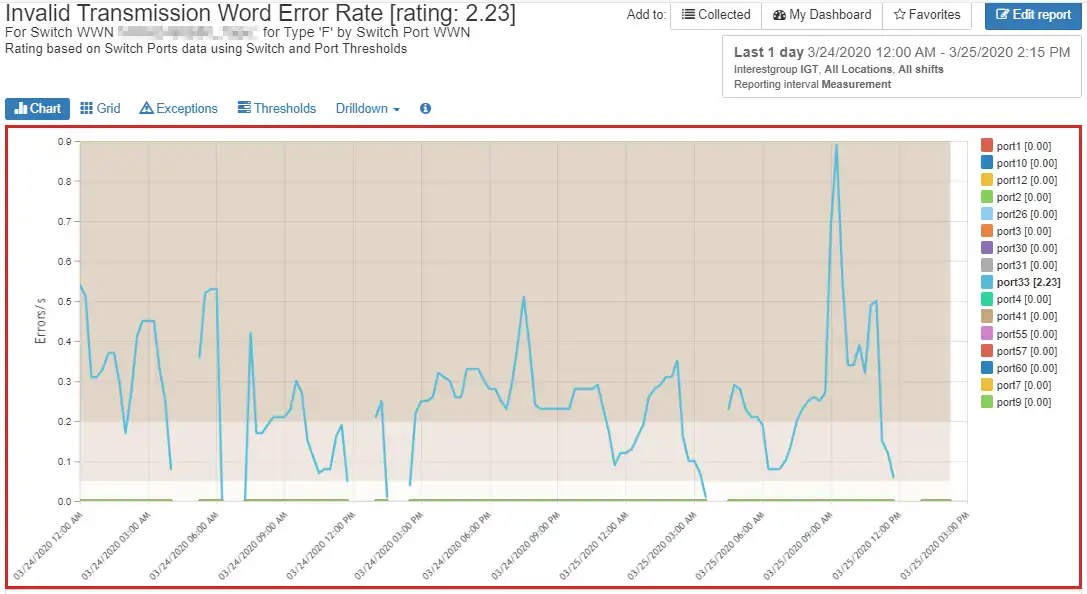
Figure 2: Switch port with high invalid transmission word errors
If your vendor allows it, and you have the budget and space, it’s never a bad idea to have spare disks, fiber, and SFPs on the shelf, just in case.
Check your redundancy
“It’s a given that hardware will fail, usually at the worst time.”
Redundancy is key to any disaster preparedness plan. It’s a given that hardware will fail, usually at the worst time. Enterprise class storage systems are engineered with a ton of redundancy, but if you don’t configure to take advantage of it you put your company’s data at risk.
Check that your hosts are connected, zoned and masked such that they will remain online if a key component (array node/HBA/port, switch blade/port, server HBA/Port) fails.
For example, the ESX host in Figure 3 below has a single point of connectivity with its datastores. Loss of connectivity caused by either the host HBA port or the switch port will cause a complete storage outage on the host.
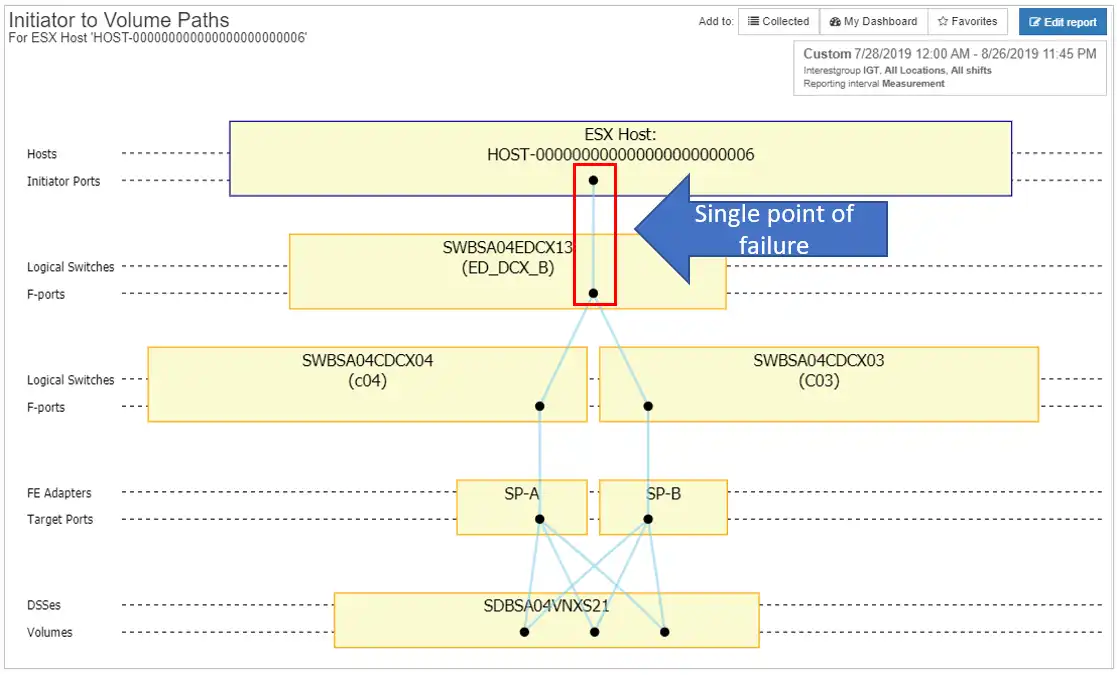
Figure 3: Switch port with single connection to storage
Are your inter-switch and inter-site links configured such that they can survive the loss of one of the interconnecting fibers? An ISL trunk comprised of 5 x 8G links that runs at 90% capacity would not be able to handle the load if one of the links in the trunk should fail.
Evaluate your backups
Finally, have a look at your backup strategy. If you should have a multiple failure event that causes data loss, make sure that your mission critical data is backed up and stored offsite and/or replicated to another site or device and that you have well-documented recovery plans in place.
Don’t Overlook Supply Chain Disruptions in Your Disaster Recovery Plan
Supply chain disruptions may be an overlooked part of your disaster recovery plan. It’s easy to assume that replacement parts will just be there.
Take a fresh look at your DR plan to make sure that you’re as prepared as you can be. It may make your company’s data safer and save you some sleepless nights when there is already enough to worry about.
This article's author
 Tim Chilton
Tim Chilton Share this blog
Related Resources
Should There Be a Sub-Capacity Processor Model in Your Future? | IntelliMagic zAcademy
In this webinar, you'll learn about the shift towards processor cache efficiency and its impact on capacity planning, alongside success stories and insights from industry experts.
A Mainframe Roundtable: The SYSPROGS | IntelliMagic zAcademy
Discover the vital role of SYSPROGs in the mainframe world. Join industry experts in a concise webinar for insights and strategies in system programming.
Expanding Role of Sub-Capacity Processors in Today's Mainframe Configurations | Cheryl Watson's Tuning Letter
In this reprint from Cheryl Watson’s Tuning Letter, Todd Havekost delves into the role of sub-capacity processors in mainframe upgrades, providing insights on transitioning to a more efficient CPC.
Request a Free Trial or Schedule a Demo Today
Discuss your technical or sales-related questions with our availability experts today