
There are quite a few things that can go wrong with zoning and configuration in a SAN environment. Because of the redundancy built into SAN fabric design principles, most of the times zoning issues do not cause immediate issues.
Whether accidental or unintentional, sub-optimal zoning leads to configuration issue time bombs that usually choose to manifest themselves when there is some type of hardware failure that removes redundancy and exposes the configuration issue.
The focus on this blog is to show some examples of the types of common zoning issues and how to identify their signatures proactively so you can remove risk in your SAN infrastructure.
Issue #1: Orphaned Ports
Risk Level: Low
There are a couple different types of orphaned ports but for this example orphaned ports are defined as “ports that are members of a masking view (storage host entry) but there are no zones that support connectivity from the initiators to the target.” In a sense, you could call this type “orphaned masking views”.
In Figure 1 below you can see a masking view named 1492-2528_MV1. It is defined on an EMC storage array ending in 1492. However, in looking at all the zones in the environment there are no zones that support connectivity from the masking view initiators and the storage targets that are defined in the masking view.
This most often happens as hosts are migrated from one array to another or when hosts are decommissioned. It doesn’t really cause any issues but is most often something that needs to be cleaned up.
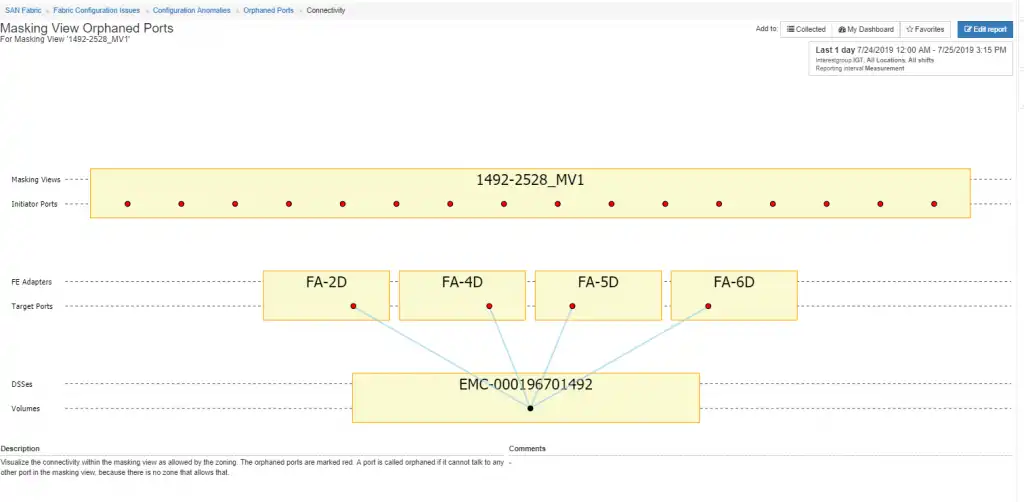
Figure 1: Orphaned Port
Issue #2: Asymmetrical Connectivity
Risk Level: Moderate to Severe
Another type of zoning issue that we often come across is what we call asymmetrical connectivity patterns through the SAN fabric stack. The SAN fabric stack consists of the host initiators, the connected switch ports that the hosts are connected to, the storage ports on the array and the switch ports that the storage ports are connected to.
If, at any layer, there is a different number of ports, it indicates asymmetry within the stack. There are a few reasons for this type of anomaly, and we will look at a couple of cases.
Case #1: Physical problem with one of the switch ports
In this case, one of the switch ports is either not functioning properly or has been placed in an unconfigured state by a storage administrator. Sometimes this is done as a short-term workaround until the issue is resolved, but often times these things get forgotten about. It’s one of those things where you say to yourself, “I don’t have time right now to really fix it, but I will get to it later”.
The following diagram demonstrates this type of issue. The problem is on DCX switch FBRS01_B20_K00B.
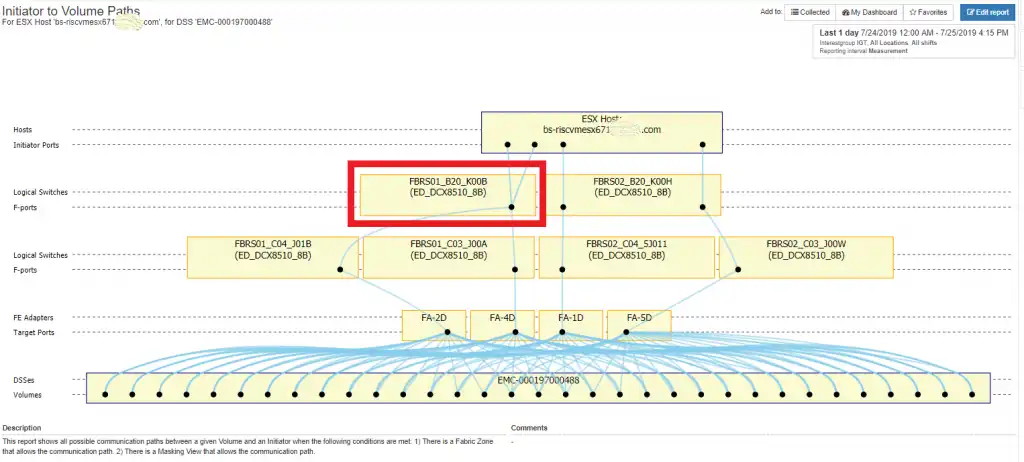
Figure 2: Physical Port Issue
DCX switch FBRS01_B20_K00B only has one port, slot10 port3, connected to the host, whereas the sister DCX switch on the other fabric has two ports, slot10 port3 and slot 11 port3. Investigation of slot11 port3 on DCX switch FBRS01_B20_K00B reveals that it is classified as port type ‘G’. This port needs to be fixed in order to restore all four paths from the host to the storage array.
Case #2: Fewer initiator ports than target ports
This can happen when you have two single port HBAs instead of four single port HBAs or two dual port HBAs on the host. This is most often the case on older server hardware or development hardware. It might be the result of a planned or unplanned implementation.
In either case it represents a difference between the capabilities of the host and the storage ports. In reality, the storage is usually over-subscribed in the sense that most storage ports have multiple hosts connected, but it will usually create imbalances in the traffic as I will demonstrate in the next figure.
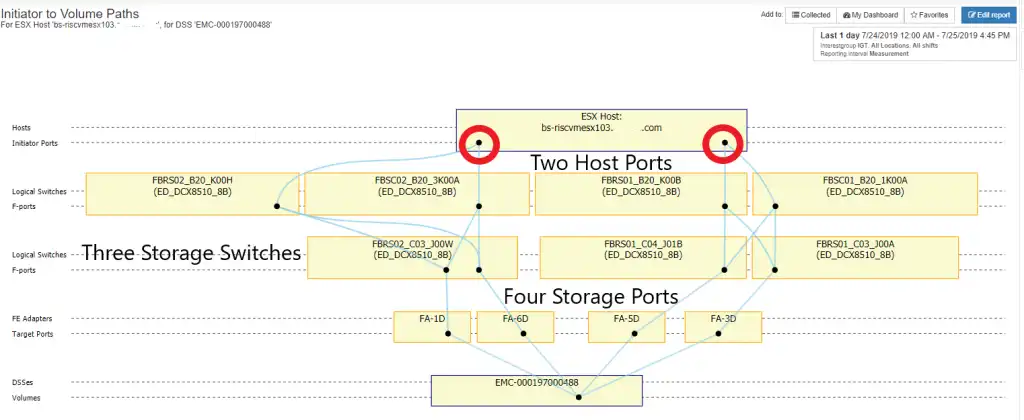
Figure 3: Fewer Host Ports
The above configuration in conjunction with host multi-pathing behavior has led to imbalances in the throughput of the switch ports connected to the host. Figure 4 displays the activity across the switch ports connected to the VMware ESX host. You can see that some of the ports are busier than others.
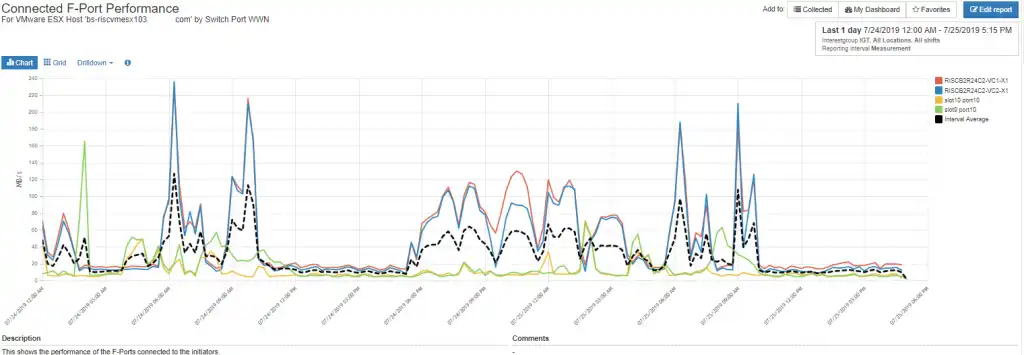
Figure 4: Imbalanced Port Throughput
Case #3: ESX Host Initiator Port down
This one is pretty straight forward. When you have a port down / offline on a host it can be because there is a problem with the port on the host, or there is no zoning that allows the initiator port to connect through the fabric. Figure 5 shows this case:
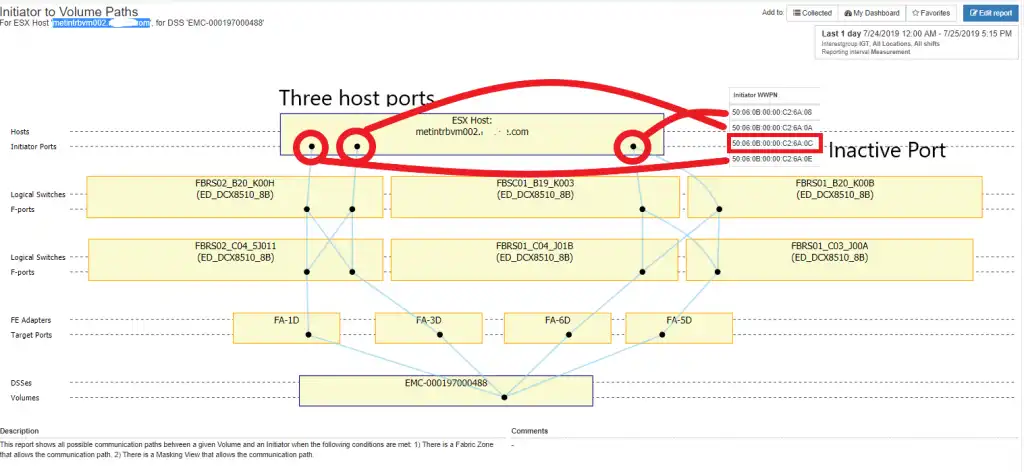
Figure 5: Initiator Port Down
I checked the zones and all the initiators were good. The port is just not online.
Case 4: Single switch
This is also a pretty straightforward signature. It is the case where there is only a single switch in the path. This clearly violates the dual fabric design principle that is bedrock to good SAN design. It is shown in the Figure 6:
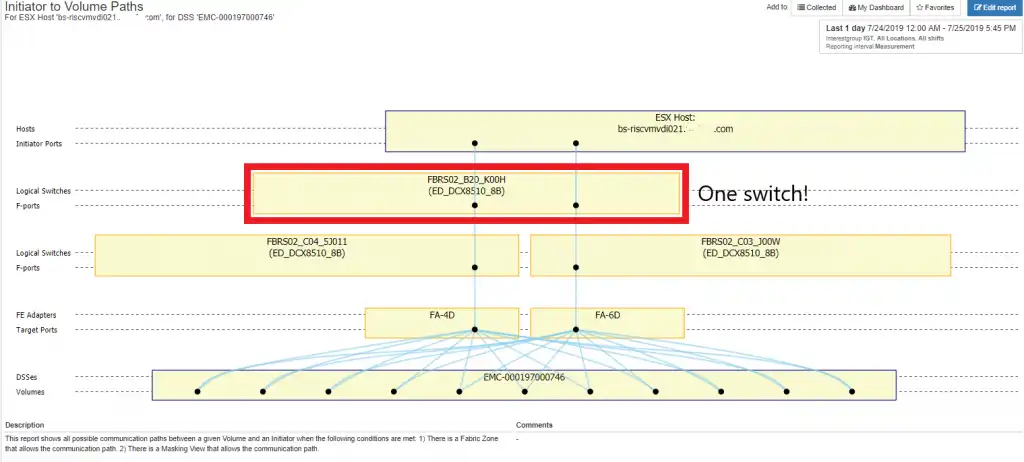
Figure 6: Single Switch
Case #5: Single Link ESX Host
In this case there is only a single path through the fabric to the storage volume. This is an obvious thing to observe in a topology map and represents significant risk:
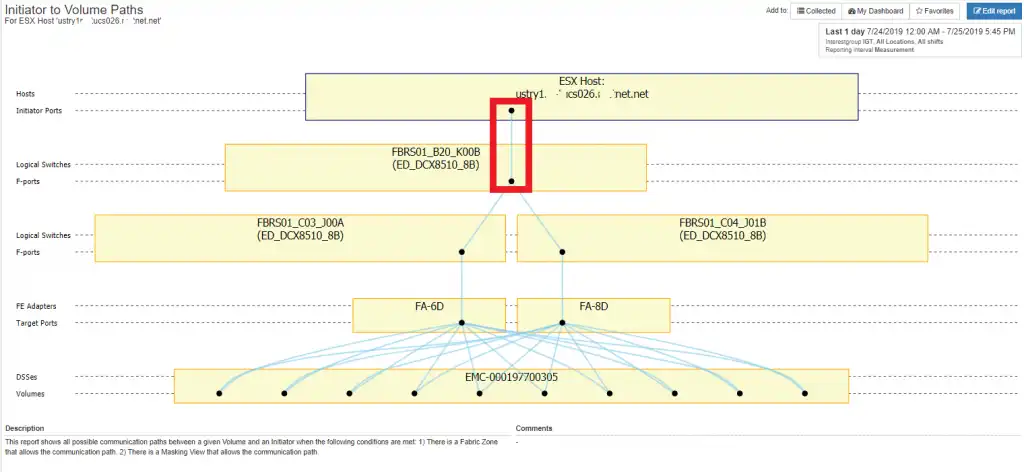
Figure 7: Single Link ESX Host
Comprehensive SAN Configuration Audit
When is the last time you performed a comprehensive audit to look for anomaly signatures in your environment?
Whether you’re an experienced SAN expert or a newbie, it is likely that it has been some time since you have been able to audit the entire environment. If you’re interested in identifying if you have any hidden configuration bombs in your environment, please let us know and we will be happy to highlight them.
This article's author
 Brett Allison
Brett Allison Share this blog
Related Resources
Improve Collaboration and Reporting with a Single View for Multi-Vendor Storage Performance
Learn how utilizing a single pane of glass for multi-vendor storage reporting and analysis improves not only the effectiveness of your reporting, but also the collaboration amongst team members and departments.
A Single View for Managing Multi-Vendor SAN Infrastructure
Managing a SAN environment with a mix of storage vendors is always challenging because you have to rely on multiple tools to keep storage devices and systems functioning like they should.
Cleaning up the SAN Fabric: Getting Your House in Order Part Two
Cleaning up SAN fabric zones and storage array masking views are often a forgotten part of good storage hygiene. Although unused zones and masking views may seem harmless, they pose an availability risk to your environment on multiple fronts.
Request a Free Trial or Schedule a Demo Today
Discuss your technical or sales-related questions with our availability experts today