
Head lights on new cars are really bright and look great for the driver. Because of this, it is nearly impossible to know while driving the car that one of them has stopped working. Everybody else on the road can tell though, and the police will pull you over regardless of the type of car.
Just as headlights can provide excellent visibility, TS7700 grids look great too. Host jobs love the new TS7770s because they are bigger, better, and faster. It’s easy to tell if a host attached VTS has a problem since the host jobs fail or alerts are sent. If a VTS in a remote location completely fails, then an alert will also be sent. But it is much more difficult to detect if it is simply not functioning as intended. Like car headlights, a high availability grid is capable of hiding a sick but not dead cluster.
In this blog we will look at various ways of monitoring a grid to determine if remote clusters are not receiving replication data and why not. IBM provides a whole set of detection monitoring for host attached clusters which are Sick but not Dead (SBND), but these are not discussed here.
What are ‘Sick But Not Dead’ Clusters?
The TS7770 combines the performance of disk-based operations with the capacity and scalability of physical tape to deliver high availability storage. Using virtualization, VTS clusters have replaced the older technology of physical tape drives and media.
Clusters are connected to form a grid which can automate movement of data from local to remote data centers. Data is replicated to multiple clusters to provide high availability and offset storage of business-critical data. Because of the complex nature of a grid, it can be time consuming to verify the availability of each cluster within the grid. Due to the redundancy in the grid, it may not be apparent for many days or weeks that the cluster is not functioning.
Individual VTS clusters only rarely fail, but they can stop performing their intended function. Remote clusters are there to receive data from the clusters in the production data center. If a remote VTS cluster is not able to receive data it has stopped performing its function.
This is what IBM calls Sick But Not Dead (SBND) Clusters.
Increasing Deferred Queue Age and Replication Backlog
Increasing Deferred Queue Age and Replication Backlog is the primary way to determine if remote clusters are not receiving data. Viewing Replication data from Receiving Clusters is a great way of detecting non-functioning clusters. IntelliMagic Vision groups these charts together into a multi-chart as seen below.

- Replication Backlog will increase as data is written to a local VTS and has not been replicated to this cluster.
- Average Deferred Queue Age will show how much time the delay in replication is.
- Inbound Total Copy Data Rate will show how fast data in coming to this cluster.
The amount of data and how long it takes to replicate will vary by site.
IntelliMagic thresholds can be set to allow normal processing to operate in the green. When thresholds are exceeded, data is taking too long to replicate. Depending upon how a site customizes their thresholds, it may take days to reach these thresholds as they are usually set well above normal operating values.
If there is Replication Backlog and the data rate is zero or lower than normal, then network links may need to be reviewed. If data rate is 0, the cluster may be unable to receive data, either because of cache utilization or VTS hardware problem.
Average CPU/Disk Utilization
Another indication of a Sick But Not Dead cluster is when either Average CPU or Disk Utilization is near 0 and stays there while Replication Backlog is increasing.
It is normal for CPU and Disk activity to be low during a period of no tape activity, but if the cluster utilization stays near 0 when data is awaiting replication to this cluster, then it should be investigated.
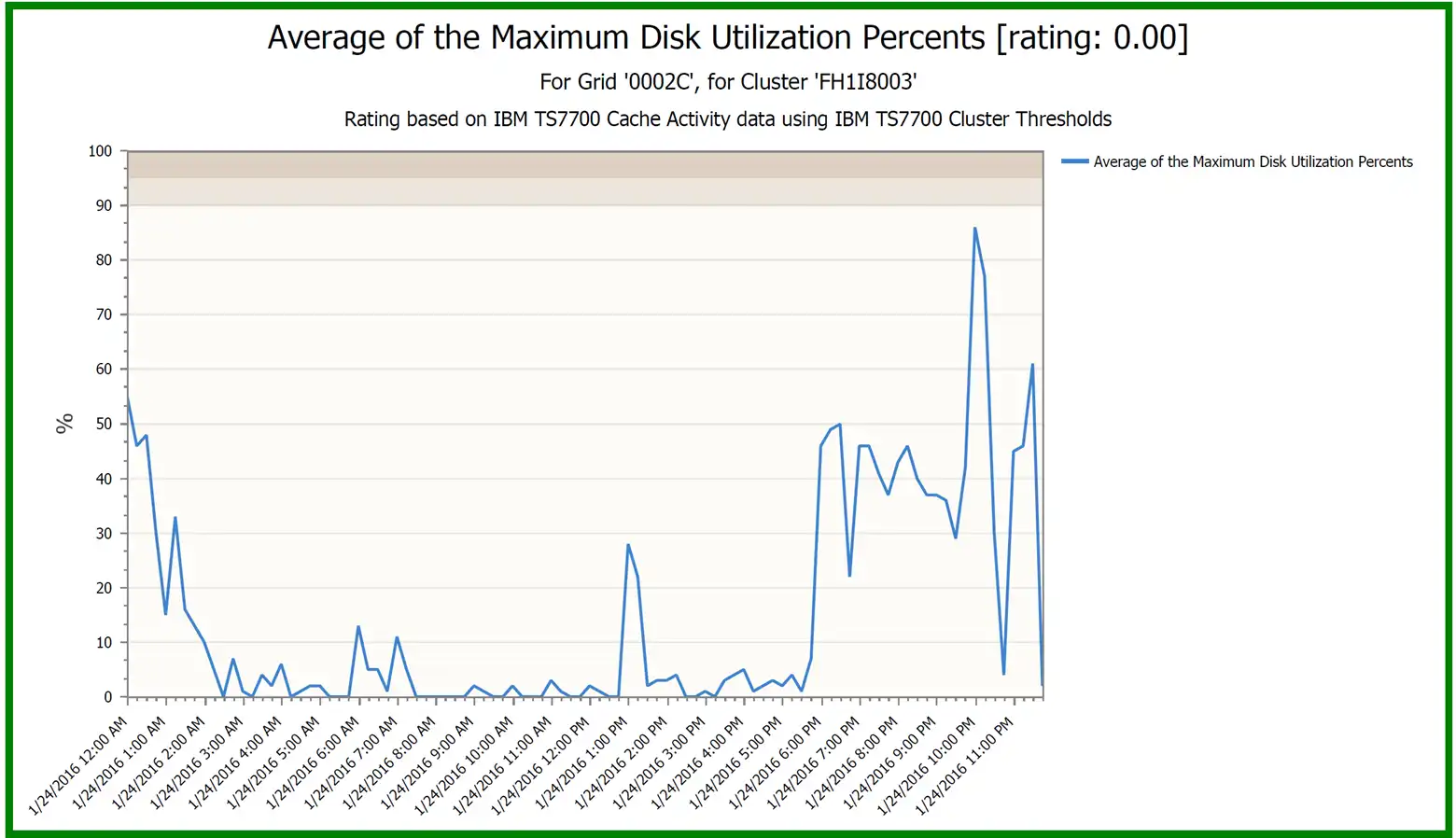
This chart shows normal activity, but for SNBD clusters, this could drop to near zero activity during periods of heavy workload because the cluster is unable to receive data.
VTS Cache Utilization
VTS Cache Utilization can be an indication as to why the cluster in a remote location is unable to receive data. Obviously if the utilization reaches 100%, there is no space for data. If the cluster has back-end tape, the library, drives, and media should be investigated to ensure they are operational. If there is no back-end tape, then the investigation moves on to why too much data has been retained in the cluster.
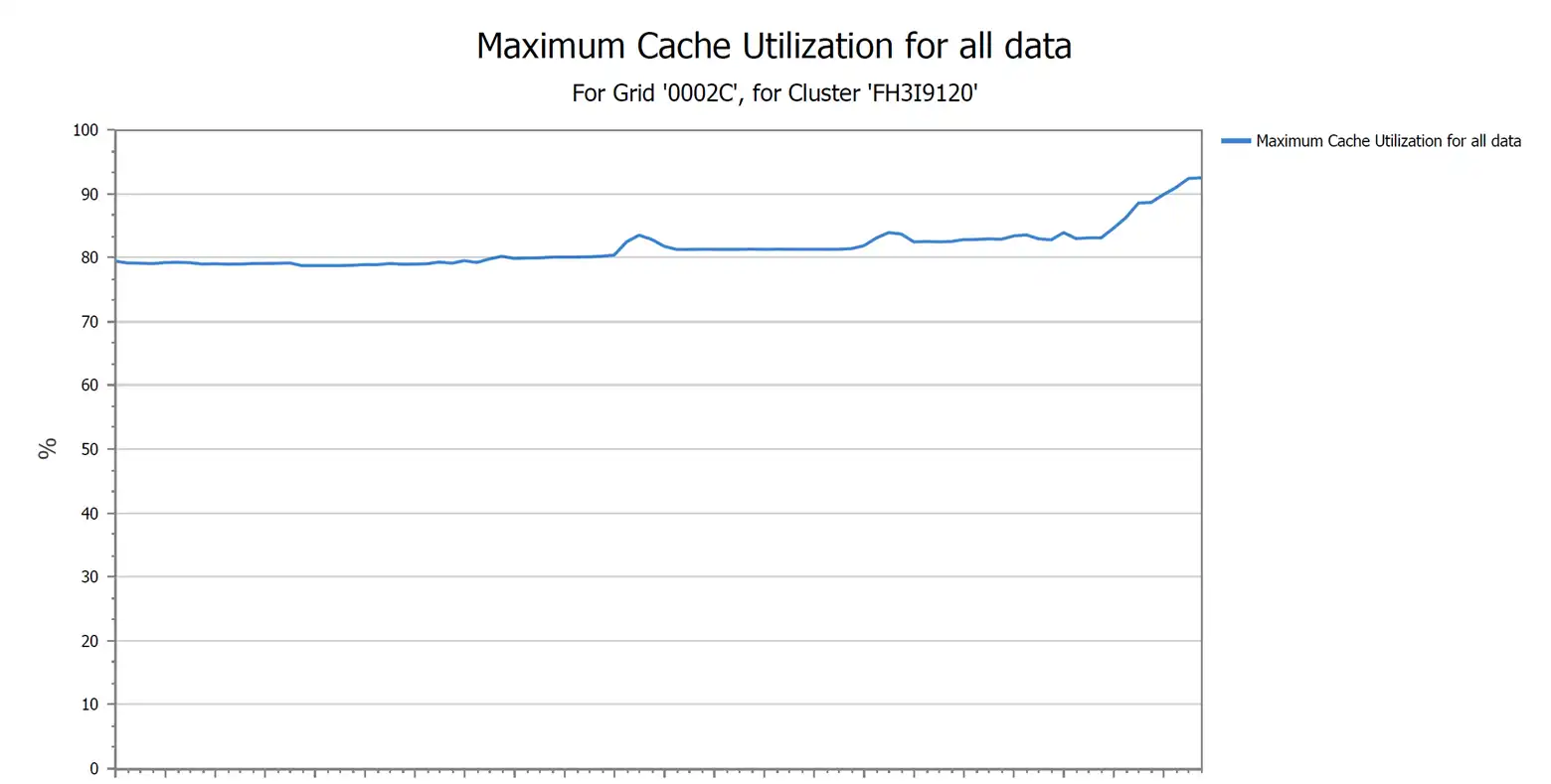
If the above chart reaches 100% utilization no data can be written to the VTS.
Possible reasons for cache full conditions
- Growth has used up excess capacity
- I.E. Not enough space in cache or data is not migrating to physical tape
- Erroneous growth caused by host datasets or GDGs which should have expired
- Accidental or non-calculated host data sets kept too long
- Flash Copy Cache is in use
- DR testing is still actively using disk cache
- Back-end tape is not pre-migrating volumes
- Volumes on disk cache cannot be removed if they have not pre-migrated.
- TS7700 management classes updated to keep volume copies on more clusters
- Accidental or non-calculated data copies
Compressed Data In Use
One way to determine if growth is the culprit for high cache utilization is to review the host Tape Management Catalog analyzing active virtual volumes.
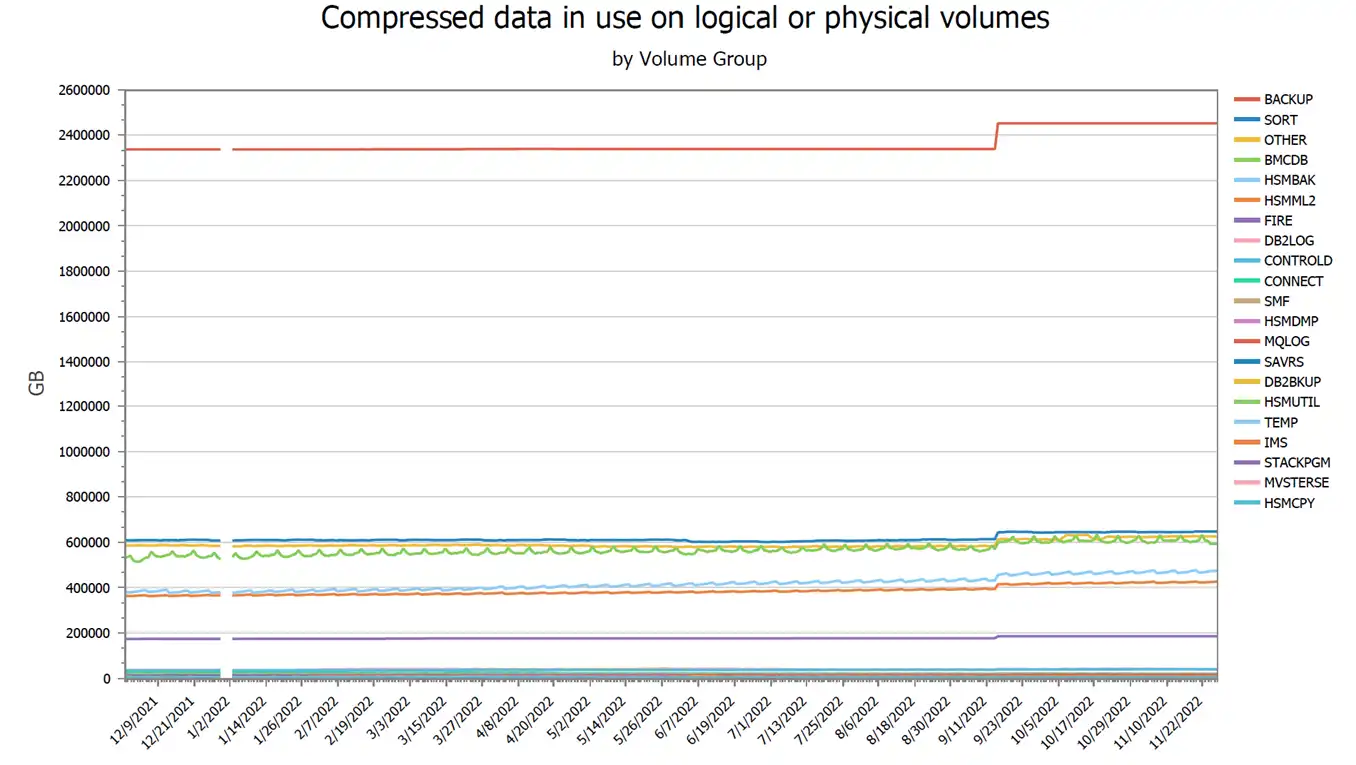
The IntelliMagic Vision Tape Volumes report set has many reports summarizing tape volume activity by volume group. If a volume group has increasing used GB, then more data is retained within the tape grid. This view of a year of data can help spot trends and isolate the problem.
Drilldowns to storage groups, system, job and program level or a combination can be done quickly and easily.
All Data Flows In and Out of the VTS’s Cache
This report is a complete view of data movement within a cluster. If a tape attached cluster is not writing to the tape pool, then the back-end tape system can be investigated.
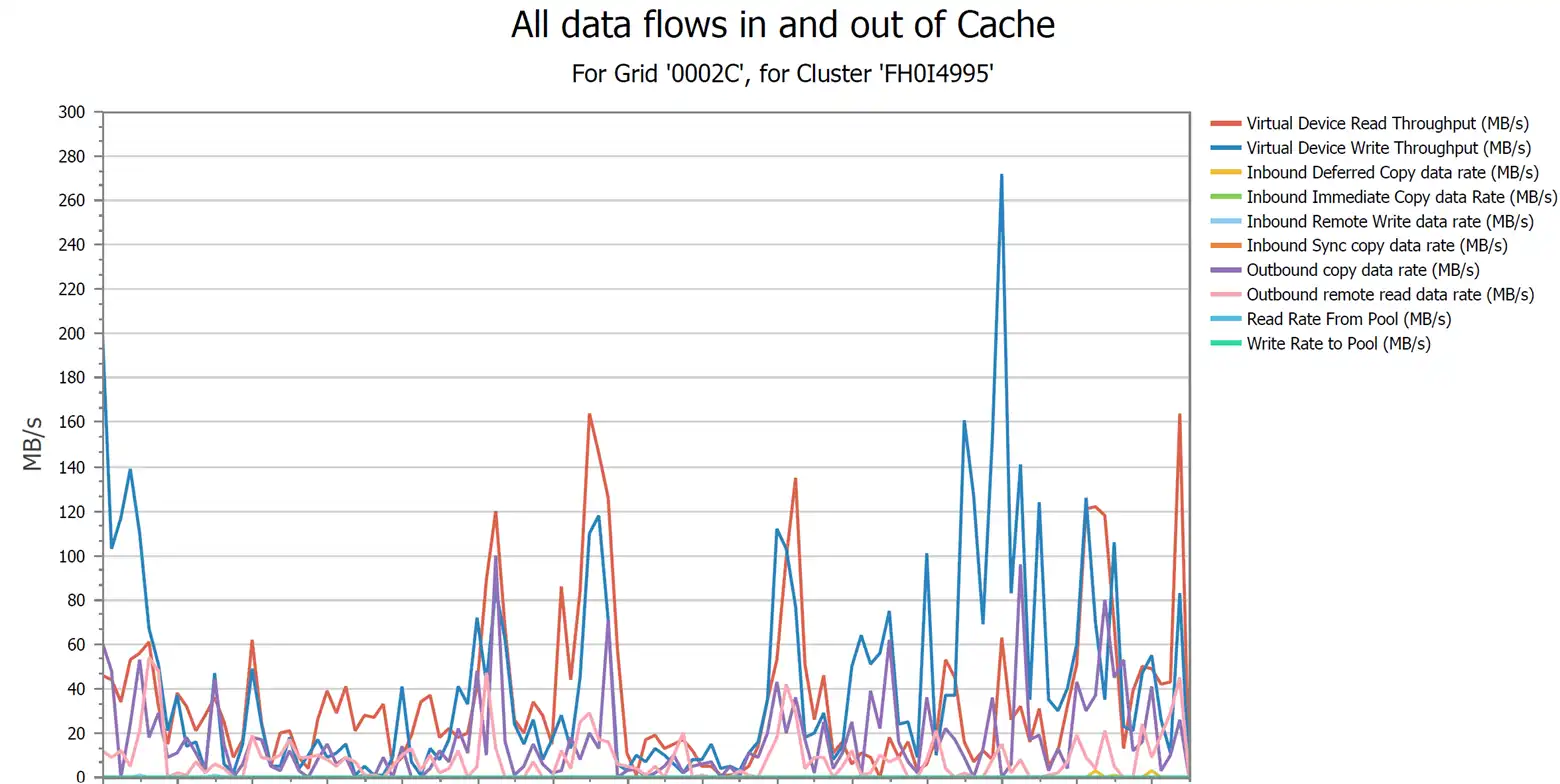
For host attached clusters, Virtual Device Write Throughput shows data actively being written to the cluster. Outbound copy data rate shows data being replicated to other clusters in the grid. Inbound copy data rate shows data being replicated to this cluster. Write Rate to Pool shows data that is being pre-migrated. Various configuration parameters can influence data movement within the grid, but for a healthy grid, data should be flowing as your configuration allows.
Review These Essential Remote Clusters Performance Reports to Find SBND Clusters
It is always a good idea to check your headlights by doing a walk around your vehicle before stepping into the driver’s seat where that broken headlight isn’t even noticeable. Just as it is a good idea to review remote clusters replication performance reports and not just rely on the VTS heartbeat indicating basic communications.
Putting this data into IntelliMagic Vision allows for potential problem indicators to become as clear as the road is when using two headlights. Putting these reports on a dashboard is a simple and easy way to monitor the health of all your VTSs. The below video covers how to review these key metrics and demonstrates how they may appear in a custom dashboard.

Using IntelliMagic Vision for TS7700 Performance Analysis
IntelliMagic Vision for TS7700 automatically compares the hardware views (via BVIR data) with the workload metrics, providing you with insight into how the standalone or gridded hardware is handling the work and replication between boxes.
This article's author
 Merle Sadler
Merle Sadler Share this blog
You May Also Be Interested In
Are My Remote Clusters Receiving Replication?
Review these key reports when troubleshooting remote cluster issues or trying to determine if your remote clusters are receiving replication.
TS7700 Synchronous Mode Copy Benefits
Compared to a reduced RPO, a lesser-known benefit to using Synchronous Mode is a more efficient cache flow and therefore a more efficient utilization of the disk cache.
How to Make the Best of IBM’s TS7700 Virtual Tape Solution | IntelliMagic zAcademy
Watch this webinar if you’ve ever experienced frustrating performance issues or just want to ensure your TS7700 environment is optimized per best practices.
Book a Demo or Connect With an Expert
Discuss your technical or sales-related questions with our mainframe experts today