
Choosing the wrong IBM Spectrum Virtualize (SVC / Storwize V7000) replication technology can put your entire availability strategy at risk.
For most customers, there seems to be a bit of a mystery in how replication works. On the surface, it is simple. Data is written to a primary copy and either synchronously or asynchronously copied to a secondary location with the expectation that a loss of data at the primary site would result in minimal data loss and a very minimal recovery effort.
Business Requirements for Data Replication Technology
There are several types of replication, and each type has its nuances. Each of these technologies should be evaluated in light of the following business requirements:
1) Recovery Point Objective (RPO): This is the amount of data loss expressed in time units (typically minutes) that you will lose should there be a failover to the secondary site.
- How much does it cost per minute of data that is lost? This should be estimated based on the types of data that might be lost, the amount of each type of data lost, and the probability of the loss.
2) Recovery Time Objective (RTO): This is the amount of time it takes to get back up and running as expressed in minutes.
- How much does it cost per minute for your business to be down? (See Toolkit: Downtime Cost Calculator for Data Center Disaster Recovery Planning for additional information)
3) How much does network bandwidth cost? This varies greatly by location.
4) What are the distances required between primary and secondary locations as prescribed by your Disaster Recovery plan? As an example, the SEC (Securities and Exchange Commission) suggests 200 miles (322 km) for financial institutions.
5) How much data do you need to replicate? You first need to decide which data needs to be replicated. Then you need to baseline the amount of peak writes /sec (expressed in Mbps) that occurs within the selected replication sets.
IBM Spectrum Virtualize Copy Services Options
After developing your Disaster Recovery (DR) requirements, you need to decide the best technology solution that maps to your requirements and your budget. Fortunately, Spectrum Virtualize offers several types of replication options:
Metro Mirror (MM)
Metro Mirror (MM) for synchronous metropolitan distances ensuring writes to primary and secondary storage are committed prior to the acknowledgment of host write completion. Use this only when the distance is short, the bandwidth is high, and understand that any congestion on fabric directly impacts the front-end write response time. The obvious advantage with synchronous mirroring is that your secondary site is always in sync with your primary site, so the Recovery Point Objective (RPO) is seconds vs. minutes.
Global Mirror (GM)
Global Mirror (GM) uses asynchronous copy services and is better for low bandwidth situations. Mild and occasional WAN congestion could not impact front-end write response times to the primary site copies. However, the secondary copy will be up to five minutes out of synch with the primary copy. This means that should the primary site experience a failure; the secondary copy may not contain all of the changes that occurred at the primary site.
Global Mirror with Change Volumes (GMwCV)
Global Mirror with Change Volumes (GMwCV) is essentially a continuous Flashcopy that asynchronously updates a remote copy. It completely isolates the primary from WAN issues but takes up significant disk capacity and cache resources locally and also leads to a remote copy that is an hour or more out of synch with your local copy depending on how you configure the cycle time.
(Stretched Cluster Volume Mirroring)
Stretched Cluster Volume Mirroring could also be considered a replication option within Spectrum Virtualize families. In this case, a Spectrum Virtualize cluster has nodes located at two locations allowing real-time copies to be spread across two locations. The RPO and RTO of Stretched Cluster Volume Mirroring is near 0 for each. The only drawback is that for this to be an effective solution you would need high-speed fibre optic connectivity and distance would need to be less than 100 km.
IBM 3-Site Replication
In the IBM 3-Site replication the data is replicated synchronously from site 1 to site 2. Both sites are in separate failure domains but are located within the boundaries of supported Metro Mirror configurations. Site 1 behaves as the master site (Master) and site 2 behaves as the auxiliary site (AuxNear). Site 3 (AuxFar) can be located in a geographically remote location from site 2. Data is replicated between either site 1 or site 2 to site 3 asynchronously using Global Mirror. This technology requires additional software to manage the copy services. The IBM marketing folks have really outdone themselves on the naming of the additional required software, “Orchestrator”. All actions are performed on consistency groups which contain volumes in relationships. It’s worth mentioning that this three-site replication can be implemented in two different topologies:
- Classic with Active Site (Master) and AuxNear as Standby site with AuxFar being the remote location. Each site operates as an independent cluster.
- HyperSwap topology: Three independent sites with two independent clusters. The highly available production cluster is configured as a Stretched Cluster with the DR site being located at the third Far location.
For more details on this technology please refer to the IBM redbook sg248504.
FlashCopy (FC)
FlashCopy is a point in time technology. Think of it more like backup software than replication services. Replication services are designed to provide high availability for two copies of data where as FlashCopy is primarily used as point in time copies of volumes. It’s kind of like taking a picture and it allows you to take multiple pictures. Similar to the concept of many frames from a movie. With IBM Spectrum Virtualize multiple target volumes can undergo a FlashCopy for the same source volume. Source and target volumes can be thin-provisioned to save space. Reverse FlashCopy allows the target volumes to be the restore points for the source volume without breaking the relationship. Most customers use this functionality to create restoration points for quick application and database restore.
Transparent Cloud Tiering (TCT)
Transparent Cloud Tiering provides a cost effective way to provide off-site backups using public cloud vendors (in particular IBM Cloud). TCT leverages FlashCopy technology to provide full and incremental snapshots of volumes. Snapshots are compressed and encrypted prior to sending them to the cloud where they are stored as object storage. Reverse functions allow you to restore the objects.
The following table summarizes the criteria that should be used when deciding the appropriate replication technology. I did not include FC or FC with TCT as they are not really replication focused technologies. I also did not include 3-site as it is constrained by the limitations of the technologies below that it relies on:
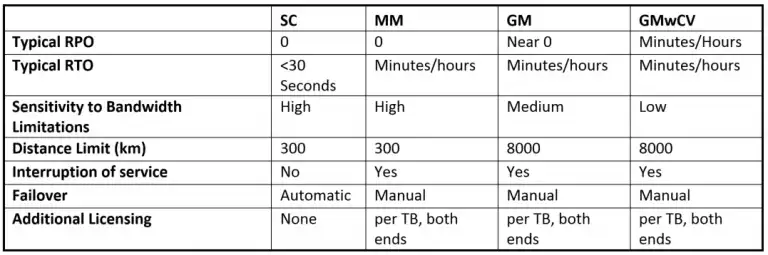
After selecting your replication technology, you need to determine the bandwidth requirements. IntelliMagic Vision translates your write data/sec to assist with creating a baseline of your network Peak Mbits/sec as demonstrated in the figure below:
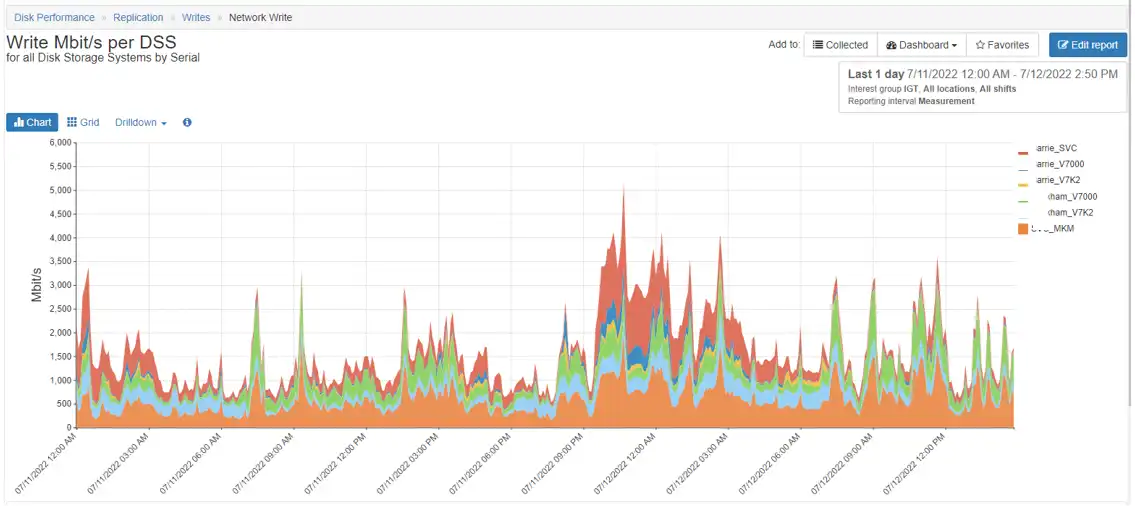
In reviewing the chart above, we can see that we will need a minimum of 6,000 Mbit/sec to handle the peak workload. You should probably factor in some amount of growth. Furthermore, depending on whether you select a synchronous or asynchronous solution you can determine whether you need to plan for an additional buffer or whether you could get away with purchasing a little less than your maximum peak bandwidth.
You should also consider adding sufficient bandwidth for the synchronization activity that will happen from time to time. If your maximum synchronization bandwidth is 50 MBps, then you should plan for 50 MBps/sec of additional bandwidth. Thus, your total Bandwidth Required could be expressed as:
Bandwidth Required = Baseline Peak Mbit/sec + Anticipated New Growth Mbit/sec + Buffer for Unexpected Peaks (20% for MM) + Synch Bandwidth
Using the example above:
MM Bandwidth required = 6,000 + 1,200 (growth) + 1,200 (buffer) + 400 (50MBps*8)(Synch bandwidth) = 8,800 Mbit/sec. If compression was not taken into account you would need to divide by the appropriate compression ratio.
GM Bandwidth required = 6,000 + 1,200 (growth) + 400 (Synch bandwidth) = 7,600 Mbit/sec. If compression was not taken into account you would need to divide by the appropriate compression ratio.
Note: For additional information, please see the IBM Redbooks related to IBM Spectrum Virtualize.
What replication technology did you choose? In the next installment of this blog, we will discuss performance monitoring and analysis of Spectrum Virtualize replication technologies.
Read part 2 of this blog: How to Diagnose IBM Spectrum Virtualize (SVC/Storwize V7000) Replication Performance Issues
(This blog was originally published in 2016. It was updated in 2022)
Start Your Trial of IntelliMagic Vision Today
Whether you’re in the early stages of product research, evaluating competitive solutions, or trying to solve a problem, we’re happy to help you get the information you need to move forward with your IT initiatives.
This article's author
 Brett Allison
Brett Allison Share this blog
Related
Noisy Neighbors: Discovering Trouble-makers in a VMware Environment
Just a few bad LUNs in an SVC all flash storage pool have a profound effect on the I/O experience of the entire IBM Spectrum Virtualize (SVC) environment.
How to Diagnose IBM Spectrum Virtualize Replication Performance Issues
This blog outlines how you can monitor and diagnose IBM Spectrum Virtualize performance issues that may be caused by replication.
Improve Collaboration and Reporting with a Single View for Multi-Vendor Storage Performance
Learn how utilizing a single pane of glass for multi-vendor storage reporting and analysis improves not only the effectiveness of your reporting, but also the collaboration amongst team members and departments.
Request a Free Trial or Schedule a Demo Today
Discuss your technical or sales-related questions with our availability experts today