 Joe Hyde -
Joe Hyde -
Black Friday is one of the busiest transaction days of the year, and it often seems like an easy payday for most participating companies. But have you ever wondered what performance preparations must be made to accommodate the overly inflated volume of credit card transactions?
A large global bank was struggling because their latest version of a credit card swipe application was failing at high volume load testing. In preparations for Black Friday they needed the application to handle a much higher number of credit card swipes, but periodically their credit card transactions were timing out.
When we became involved they had spent weeks on the issue, thousands of man-hours and had incurred significant financial penalties because of the delays. They had spent the past two weeks on day-long conference calls with over 100 people on the phone (often forcing some off the line so others could join) all pointing fingers at one another. The performance team, application team, storage team, and the vendor all blamed one another for the timeouts.
You see, the delays had a significant revenue impact to their business as any credit card approval that timed out had to be sent over a competitor’s exchange, incurring significant fees. After the two weeks of conference calls proved to be unsuccessful in determining the root cause of the problem, they called us in. We took a deep dive into some of the key storage metrics and were able to provide the key insight in determining root cause of the timeouts in a few days of research and additional data acquisition.
Parallel Access Volume Evolution
The cause of the delays was related to queuing that happened in the mainframe I/O subsystem as evidenced by increases in IOSQ time. The I/O architecture has evolved over the past twenty years to minimize this wait time. I/O concurrency at the volume level has been enhanced through a number of features using parallel access volumes or PAVs for short.
The evolution of PAVs included the following steps:
- It began with static PAVs: a predefined number of aliases.
- This was quickly followed by dynamic PAVs, that moved from one volume to another based on load.
- Next came HyperPAVs: PAVs shared among volumes within a logical control unit “as needed”.
- And now we have SuperPAVs, where PAVs are shared among volumes across sets of logical control units (called alias management groups).
More Aliases are Not Always the Answer
Even with the architectural improvements to reduce IOSQ time, delays can still occur. Below is an IntelliMagic Vision stacked bar chart of I/O response time components for a DB2 storage group.
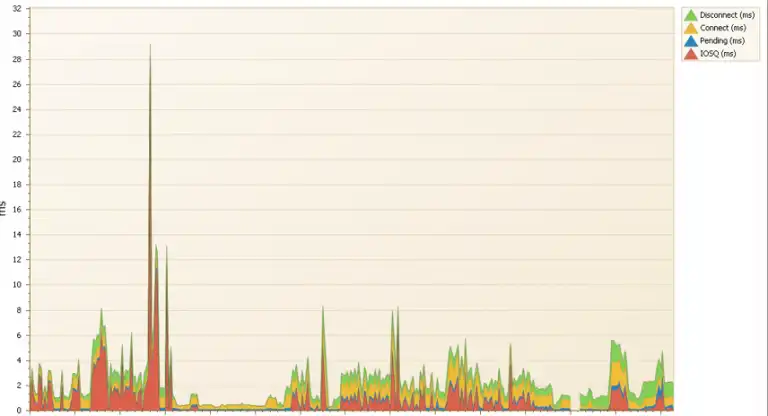
The chart covers a period of four days. The majority of I/O response time is IOSQ time. Although SuperPAV could not be deployed, the configuration was changed to increase the HyperPAV aliases from 32 to 96 to alleviate the high I/O response time. Unfortunately, this increase had almost no effect on the I/O delay.
The maximum I/O rate during this time was roughly 25 thousand I/Os per second and the total throughput was well under 1 gigabyte per second. The disk storage system was not under duress, on average, during this time but IOSQ delay and poor performance persisted.
Using GTF Trace for Finer Granularity
At that point a more granular approach to the data analysis was needed. Instead of looking at averages over the RMF interval of 15 minutes, a GTF I/O Summary Trace was collected so we could examine the behavior of the I/Os at event level granularity. (For a more in-depth discussion on GTF analysis see my previous blog, IBM z/OS’s Microscope – GTF)
The GTF trace analysis showed that the I/O arrival pattern to the DB2 volumes was quite “bursty”. Although reads I/Os had a fairly steady arrival pattern throughout the trace period, write I/Os arrived in “batches” with long periods with little write activity. The bursty write behavior swamped the physical (and logical) resources of the disk storage system.
After consulting with the vendor (IBM DB2 software) they suggested a change to the Castout behavior of the DB2 group buffer pool to spread the write activity out over time. Below is the before and after effect of this change.
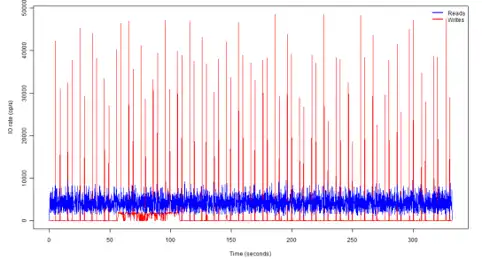
Before
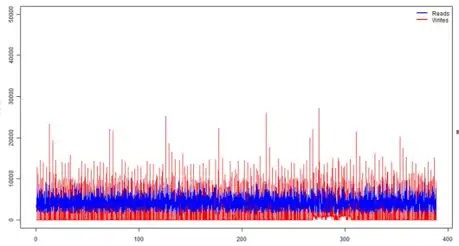
After
The blue represents the read I/Os executed every 0.1 second and red shows the writes executed every 0.1 second.
Credit Card Transaction Timeout Resolved
After the DB2 group buffer change the IOSQ time was drastically reduced, resulting in almost no credit card transaction timeouts. This saved the business millions of dollars, and the hundred-people jumping on conference calls could finally go back to work.
IntelliMagic Vision was used to identify the increase in IOSQ that correlated to the credit card transaction timeouts and then we used GTF I/O Summary Traces to help identify the root cause of the queuing and subsequent timeouts.
Feel free to contact us with any questions or to get a more comprehensive view of the interaction of your applications and storage.
This article's author
 Joe Hyde
Joe Hyde Share this blog
Related Resources
IntelliMagic Vision Support for Hitachi VSP SMF Records from Mainframe Analytics Recorder
Learn how to gain insight into the health of the Hitachi Virtual Storage Platforms VSP 5000 series and VSP F/G1x00 storage systems using the SMF records created by the Hitachi Mainframe Analytics Recorder.
From Taped Walls to Your PC: z/OS Configuration Made Simple with Topology | IntelliMagic zAcademy
In this webinar, we explore a technique that integrates diverse data sources from z/OS, presenting them in a clear, concise, and interactive visual format.
Banco do Brasil Ensures Availability for Billions of Daily Transactions with IntelliMagic Vision
Discover how Banco do Brasil enhanced its performance and capacity management with IntelliMagic Vision, proactively avoiding disruptions and improving cross-team collaboration.
Book a Demo or Connect With an Expert
Discuss your technical or sales-related questions with our mainframe experts today