
Almost all new storage offerings these days offer some level of support for Non-volatile Memory Express (NVMe). The purpose of this blog is to help the reader understand NVMe and prepare them for successful adoption of this powerful technology. It is an exciting paradigm shift that will be in the datacenter for the foreseeable future.
Background of Non-Volatile Memory Express (NVMe)
The basis of most of today’s storage protocols, including Fibre Channel, is the SCSI standard, which was established in the 1980’s. Although the SCSI command set has been updated multiple times since, it is still too sluggish for today’s high density and high capacity all flash and hybrid flash arrays.
Prior to the advent of SSDs, the bottleneck of the storage solution was the spinning disk. The latency incurred due to the rotational speed of the platter and the seek time of the heads was the limiting factor.
With the advent of flash drives, the bottleneck has moved to the data path. NVMe is the heir apparent to SCSI-based protocols. The NVMe standard defines both an interface and a protocol that was designed to take full advantage of the speed offered by solid state drives.
NVMe Interface
NVMe uses the PCI Express (PCIe) standard, which defines a high-speed serial bus for support of internal drives. It improves on previous bus standards by featuring:
- Lower I/O pin count
- Smaller physical footprint
- More detailed error detection and reporting
- Native hot swap capability
- Lower latency due to improved drivers, increased number of queues and commands in a queue
- Improved bandwidth by taking advantage of PCIe interfaces
- Lower CPU overhead when handling I/O
- Better usage of the capabilities of multi-core processors
NVMe Protocol
NVMe was originally released to take full advantage of flash capabilities and provides a significant advantage over both SATA and SAS interfaces locally.
Data is transferred in parallel between the processor and the NVMe controller via as many as 65535 queues and as many as 65535 commands per queue. By comparison, legacy buses, like SCSI, support from 8 to 32 commands per LUN and 512 commands per port.
These limits were adequate for spinning disks but are a limiting factor when supporting flash drives. NVMe queues are designed so the I/O commands and responses operate on the same processor core to take advantage of the parallel processing capabilities of multi-core processors. This allows each application or thread to have its own queue, minimizing performance impacts.
NVMe eliminates wasteful SCSI and ATA overhead by having all commands the same size and located in the same position within the transmitted frame. Figure 1 illustrates the local connectivity for NVMe drives.
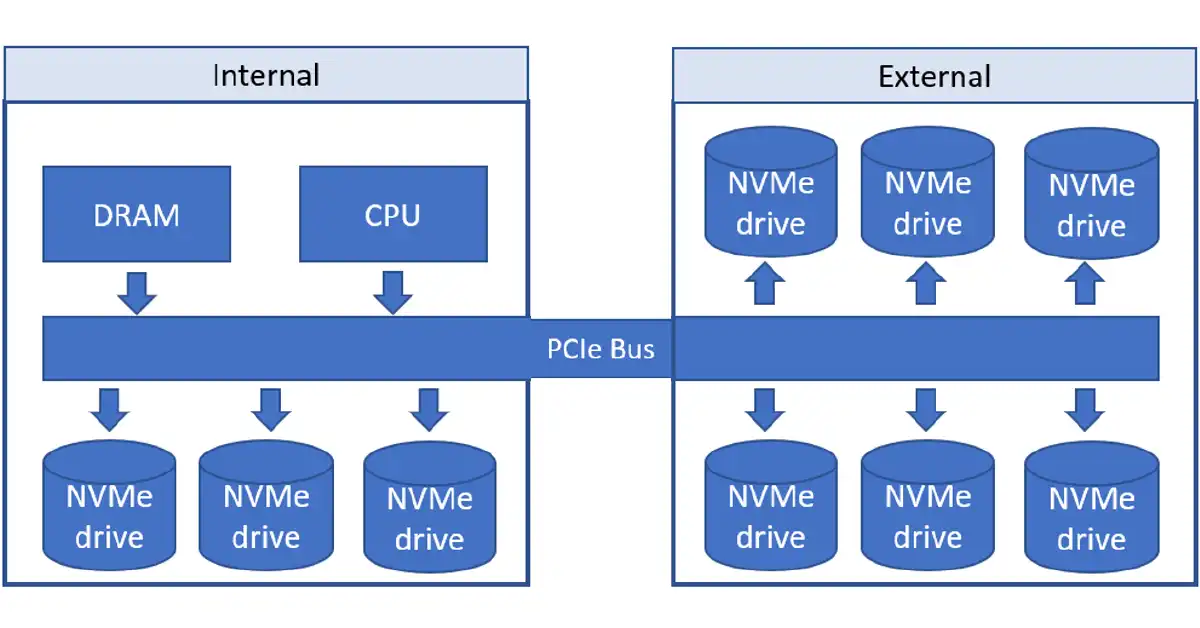
Figure 1 – Local NVMe connections
As of this blogs publish date, NVMe is supported by all major operating systems, including Windows 8.1, Windows Server 2012R2, RHEL 7.x, FreeBSD, Solaris S11.2, VMware ESX 6.5, and later updates for these operating systems. One should always check the compatibility matrices for all equipment prior to deployment to ensure end-to-end compatibility.
Using NVMe within the server locally doesn’t scale at the datacenter level, so NVMe over Fabrics (NVMeoF) was released for Fibre Channel in 2014 and subsequently for a number of other transport protocols:
- Fibre Channel – FC-NVMe
- TCP – NVMe/TCP
- RDMA – using either RoCE for converged Ethernet or iWARP for traditional Ethernet
- InfiniBand – NVMe over InfiniBand
NVMeoF requires:
- A reliable, credit-based flow control and delivery mechanism – Native to Fibre Channel, InfiniBand and PCI Express transports
- An NVMe-optimized client – the client software should be able to send and receive native NVMe commands directly to and from the fabric without the use of a translation layer, such as SCSI.
- A low latency fabric that imposes no more than 10 microseconds of end to end latency
- Reduced latency and CPU utilization adapters or interface cards. These adapters should be able to register direct memory regions so that the data to be transferred can be passed directly to the hardware fabric adapter. This is supported with Gen6 HBAs, particularly with Brocade, Emulex, and QLogic/Cavium HBAs.
- Multi-host support – the fabric should be able to support multiple hosts actively sending and receiving commands at the same time.
- Multi-port support – the host servers and storage systems should be able to support multiple ports
- Multi-path support – The fabric should be able to support multiple simultaneous paths between any NVMe host initiator and NVMe target.
NVMe over Fibre Channel (FC-NVMe)
The remainder of this blog will concentrate on NVMe over Fibre Channel (FC-NVMe).
Since the Fibre Channel Protocol (FCP) and iSCSI are really SCSI over FCP and SCSI over Ethernet, respectively, they inherit the innate sluggishness of the SCSI protocol. The Fibre Channel transport, however, can transport multiple higher-level protocols at the same time, such as FCP, FICON, and FC-NVMe (the specific frame type used by NVMeoF).
This means that FC-NVMe can be used on the same switch as your existing FCP or FICON traffic. Most FC-NVMe HBAs support both FC and NVMe-FC, allowing support of legacy FC equipment. In order to make use of FC-NVMe, the host must have an FCP/ FC-NVMe HBA.
Figure 2 illustrates a typical NVMe-capable host’s connectivity to external data.
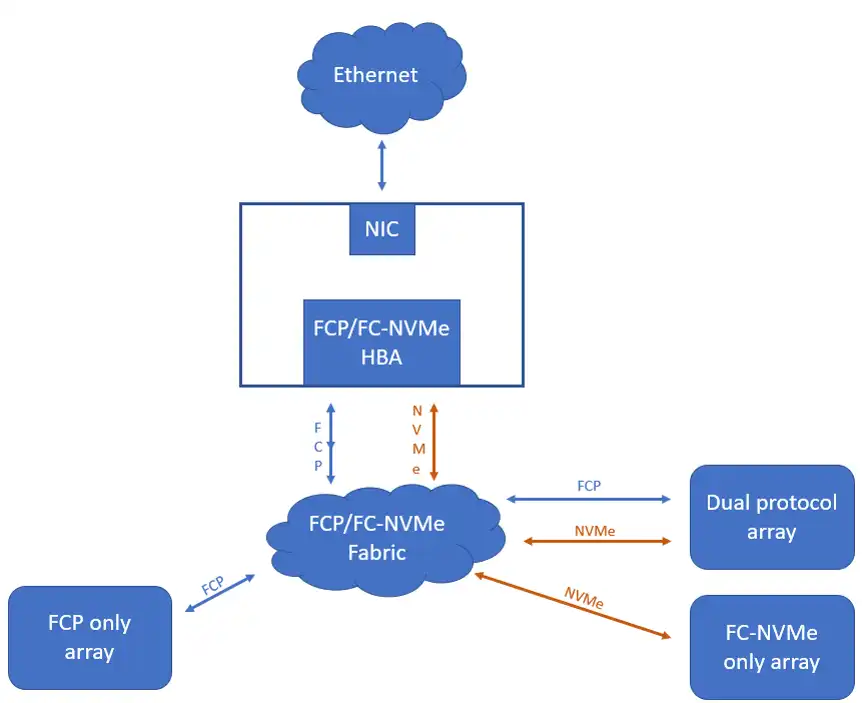
Figure 2 – Connectivity to FC fabric
Although SCSI and NVMe use different stacks, there are some similarities. SCSI uses the logical unit number (LUN) to identify different volumes within a single storage target wherein each volume has a LUN number. NVMe uses the namespace to accomplish that functionality. An NVMe namespace ID is a set of logical block addresses (LBAs) to map a volume to an addressable unit.
Migration to FC-NVMe
There are multiple things to consider when adopting FC-NVMe to ensure a successful migration:
- Ensure your existing fabric supports FC-NVMe. Every switch in the path must support the protocol or communication will fail. Support for FC-NVMe typically requires Gen5 (16Gbps) or Gen6 (32Gbps) switches.
- Minimize the number of hops between the host and the NVMe-based storage. Each hop increases the latency between host and storage. Best practice is to avoid ISLs and ICLs. With no ISLs or ICLs, one can expect very little latency introduced due to FC-NVMe, and one can expect sub-millisecond response times.
- Make sure your host HBA support FC-NVMe. Typically, Gen6 HBAs are required.
- Storage arrays must support FC-NVMe frame types. NVMeoF uses both FCP and FC-NVMe frame types.
As always, one should check vendor support matrices as part of the planning phase of implementation.
One can compare the adoption of NVMeoF to that of IPv6 in that migration to NVMeoF is typically done in a phased approach. In the end state, there are usually remnants of the legacy protocol. Since most HBAs that support FC-NVMe also have legacy FC support, it’s easy to initially migrate just the workloads that require the speed of FC-NVMe, while leaving legacy FC volumes in place.
Before implementing FC-NVMe into production, one should do a limited rollout in a test environment first. At a high level, one should do the following in a test environment:
- Discuss and document who owns the data path. Since NVMe essentially eliminates network performance issues, a single team should own and maintain the entire path, including the storage device and the network. This will facilitate timely resolution of issues.
- Make sure that your team is properly trained prior to the transition.
- Consider vendor support at all phases of the migration. Ask them about their NVMeoF testing and best practices.
- Refresh any necessary management tools for FC-NVMe.
- Set up a single server with an internal drive, a single switch, and a single FC-NVMe enabled array. Explore the HBA and storage array configuration options.
- Configure a volume for host use on the FC-NVMe array.
- Copy a file from the internal drive to the NVMe volume and back.
- Run your preferred performance testing application, such as IOmeter, to benchmark both your internal drive and your NVMe volume.
- Add a second path and experiment with it to familiarize yourself with the HBA multipathing options.
- Migrate a volume or two from SCSI to NVMe (LUN to namespace ID) to familiarize yourself with the process, then place a workload on the volume.
- Baseline any applications before migrating to NVMe volumes in order to document what is normal.
When it’s time to cut over to production:
- Make sure your production management tools have been refreshed for FC-NVMe.
- Be sure to properly socialize the migration with management and peers so that all understand what is about to occur.
- Document the transition so that any step of the migration can be easily rolled back.
Plan, Prepare, then Execute
Adoption of NVMe technology doesn’t need to be painful. With the proper preparation and a scaled and well documented rollout, you will be able to enable your enterprise with blinding speed storage with a minimum of unscheduled downtime.
This article's author
 Tim Chilton
Tim Chilton Share this blog
Related Resources
How to Detect and Resolve “State in Doubt” Errors
IntelliMagic Vision helps reduce the visibility gaps and improves availability by providing deep insights, practical drill downs and specialized domain knowledge for your SAN environment.
Finding Hidden Time Bombs in Your VMware Connectivity
Seeing real end-to-end risks from the VMware guest through the SAN fabric to the Storage LUN is difficult, leading to many SAN Connectivity issues.
Platform-Specific Views: Vendor Neutral SAN Monitoring Part 2
Each distributed system platform has unique nuances. It's important for a solution to be capable of getting the detailed performance data capable of supporting vendor-specific architectures.
Request a Free Trial or Schedule a Demo Today
Discuss your technical or sales-related questions with our availability experts today