
Your NetApp CIFS latency is through the roof and your users are banging on the door. You can either panic or try to figure out what’s going on in the system. Don’t worry. There are ways to avoid the panic attack and work through the root cause analysis.
As a storage engineer or analyst, it is important to understand the key workloads and perform regular comprehensive health assessment in your environment. This provides the advantage of knowing the heavy hitters in the environment and understanding how close your environment is to running out of resources.
If this sounds like too much work, that is because it is too much work to do it manually. Let’s take a look at an automated assessment of the different protocols on a NetApp cluster as shown in Figure 1.
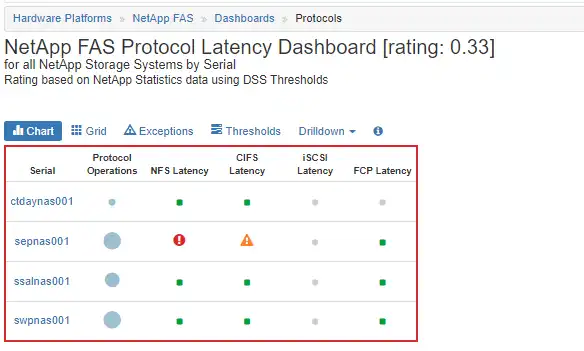
Figure 1: NetApp FAS Protocol Latency Dashboard
NetApp cluster sepnas001 has significant NFS latency as well as CIFS latency as indicated by the red exclamation bubble and the yellow warning icon. Let’s drill down to look at the key performance metrics over time as shown in Figure 2.
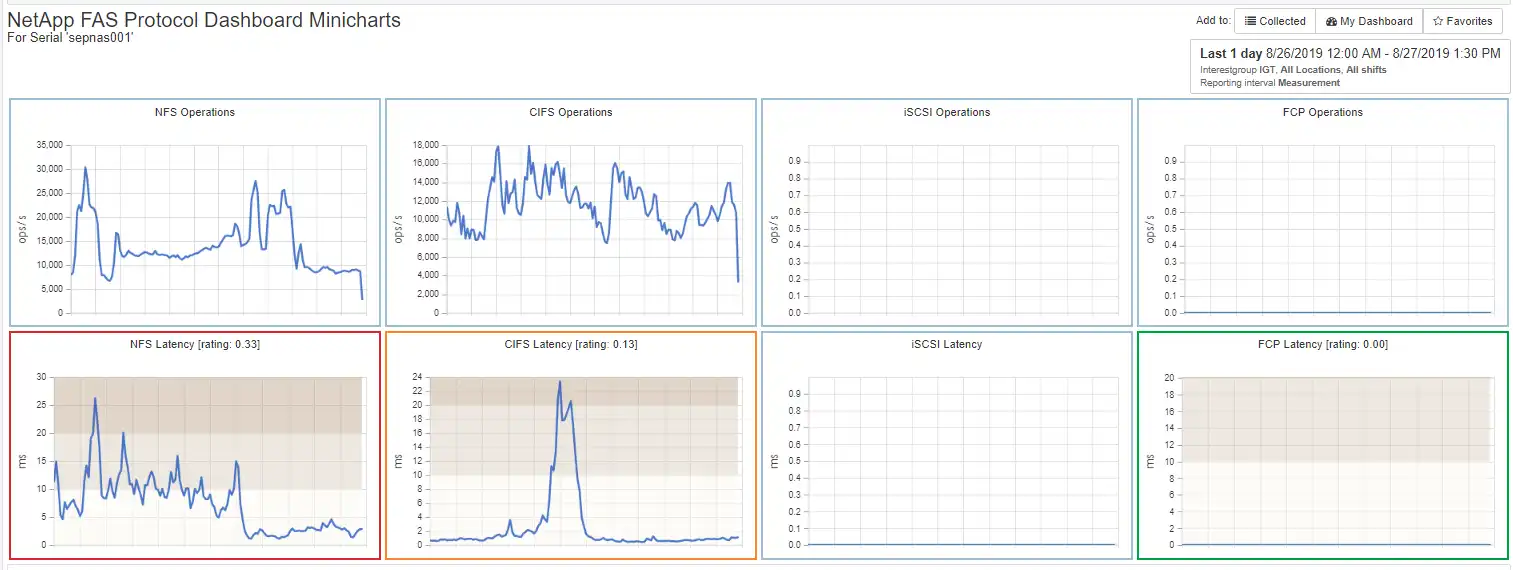
Figure 2: NetApp FAS Protocol Minicharts
The average CIFS latency peaks for several hours. By drilling down from the cluster CIFS latency to the CIFS latency by node we see that sepnas001-n2 is the only node affected by the CIFS latency increases as shown in Figure 3.
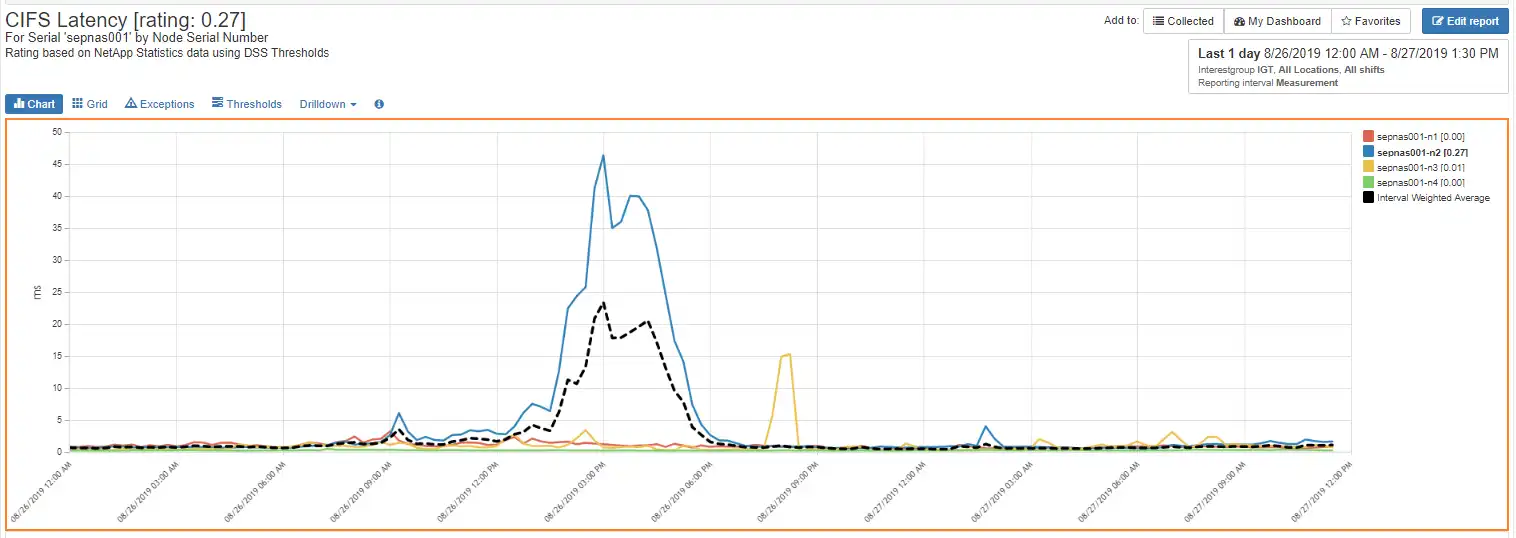
Figure 3: CIFS Latency by Node
Since there is weak correlation between the I/O operations and the latency we want to inspect the CPU and disk resources for sepnas001-n2 on the NetApp System in Figure 4 to see if there are resource constraints.
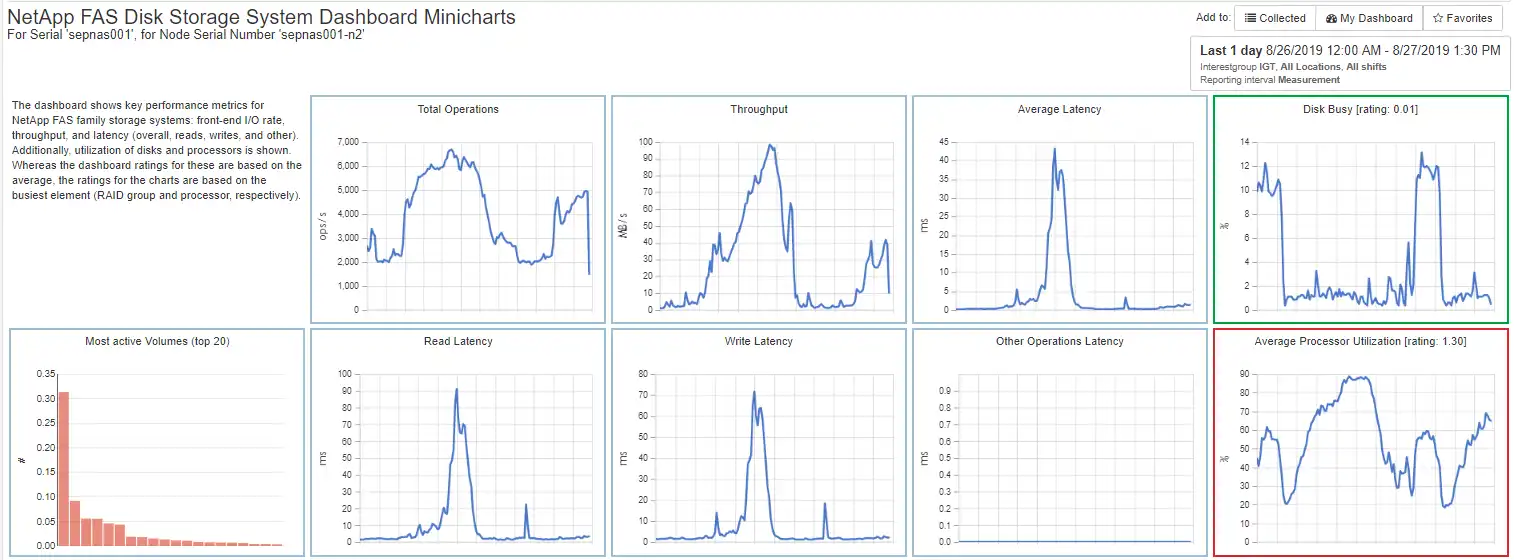
Figure 4: NetApp FAS Minicharts
As you can see in Figure 4, there is correlation between the average processor utilization and the increase in latency on sepnas001-n2. The constrained processor is leading to the increase in latency. When CPU utilization is greater than 70% on NetApp systems the latency tends to suffer noticeably.
When CPU utilization is greater than 70% on NetApp systems the latency tends to suffer noticeably.
Let’s drill down and see who is driving the load. In order to see who is driving the load we simply click on the throughput and drill down to the Flexvols as shown in Figure 5. The volume labeled ‘edwsal_matra’ appears to have significantly more throughput than any other volume.
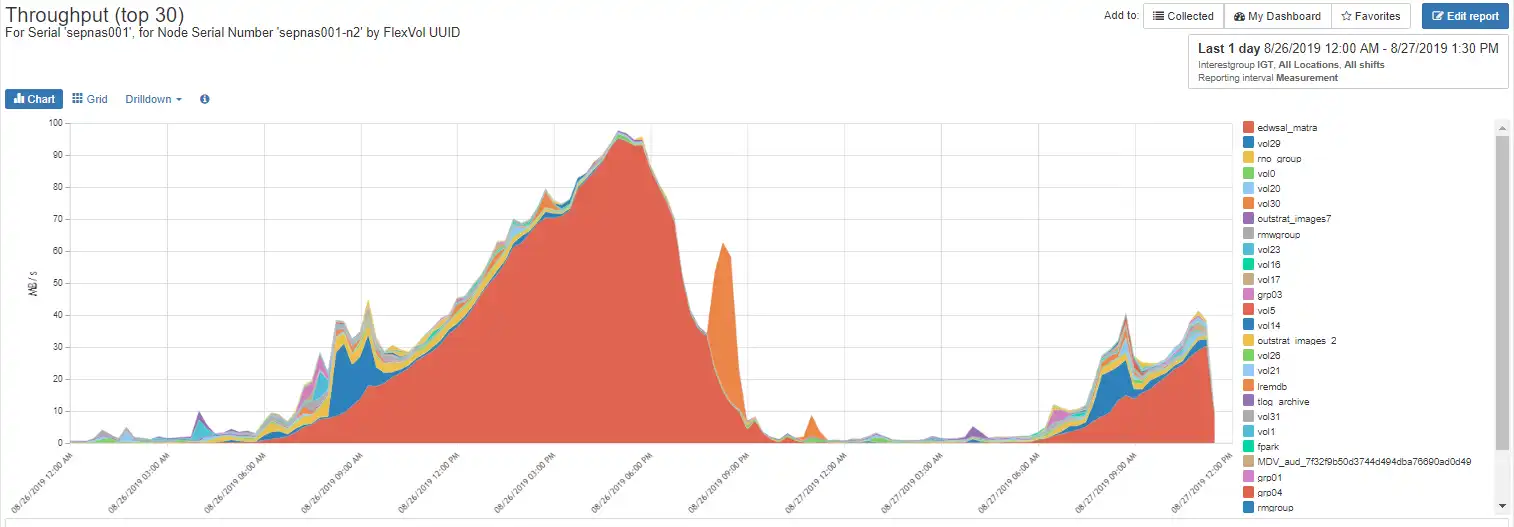
Figure 5: Throughput by Flexvols
By clicking on identify on the volume we can observe which vFiler the volume is associated with as shown in Figure 6. The vFiler is vs38_wingroupep1.

Figure 6: Flexvol identify
You can issue the following command from the advanced privilege level to identify the source IP of the host driving the load:
Cluster-1::*>Statistics top client show
Once you know the IP address of the host driving the load you can relate it to the server name (nslookup). From the server name you will need to work with the application owners to understand if the workload is normal or unexpected.
Summary of Findings
In this short blog we looked at a NetApp c-mode system that was identified as having high CIFS and NFS latency. We made the following observations:
- CIFS and NFS latency are high on sepnas001-n2
- CPU utilization is high on sepnas001-n2 during the period where high latency is observed
- The workload is primarily associated with vs38_wingroupep1 and volume ‘edwsal_matra’
Don’t Panic – Get IntelliMagic
IntelliMagic Vision provides intelligent dashboards that highlight potential issues or constraints in your storage infrastructure. If you want to quickly identify the source of issues on your NetApp systems or perform proactive performance health assessments, IntelliMagic Vision facilitates highly intuitive and interactive analysis of your c-mode systems
This article's author
 Brett Allison
Brett Allison Share this blog
Related Resources
Factors That Affect NetApp Performance: NetApp Performance Management 102
This blog covers the factors affecting NetApp performance and how to remediate them if necessary.
NetApp Performance Management 101: Key Metrics and Baseline Performance
Learn about NetApp key metrics and how to use them to understand and troubleshoot host performance issues.
Improve Collaboration and Reporting with a Single View for Multi-Vendor Storage Performance
Learn how utilizing a single pane of glass for multi-vendor storage reporting and analysis improves not only the effectiveness of your reporting, but also the collaboration amongst team members and departments.
Request a Free Trial or Schedule a Demo Today
Discuss your technical or sales-related questions with our availability experts today