
In my previous blog, we examined the key architectural differences between the IBM SVC and the EMC Vplex. We also discussed the key performance metrics. In this blog we will examine a single use case where the director utilization and front-end write response times are higher than desired, and we will look at what server is driving the load.
Since there are many components to be monitored, it is helpful to have a consolidated view of the key components and their health. Figure 1: Vplex Director Dashboard, an IntelliMagic Vision dashboard, shows this consolidated health view of Vplex key components.
The Vplex systems in question have significant performance issues. We will examine the issues on cluster-1 in this blog.
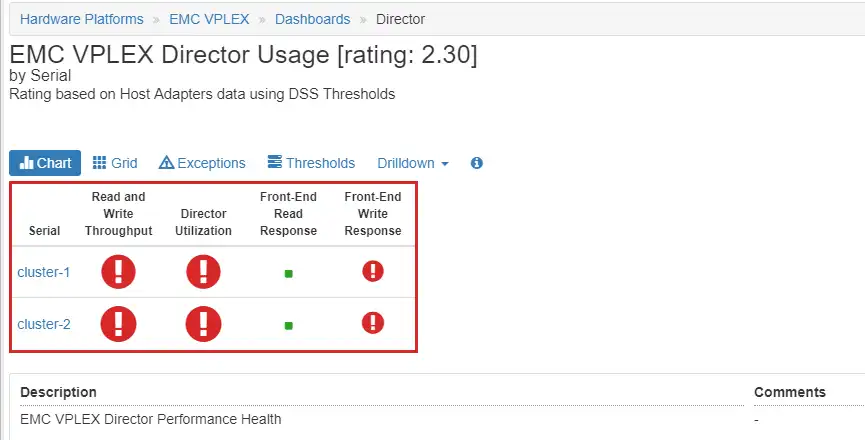
Figure 1: Vplex Director Dashboard
As you can see, the Director Utilization and the Read and Write Throughput have large red icons. This indicates that best practice compliance levels have been exceeded due to the high utilization during most of the period. The Director Front-End Write Response Time is also red. Drilling down to the time charts we can see these key metrics over time as shown in Figure 2: Director Time Charts.
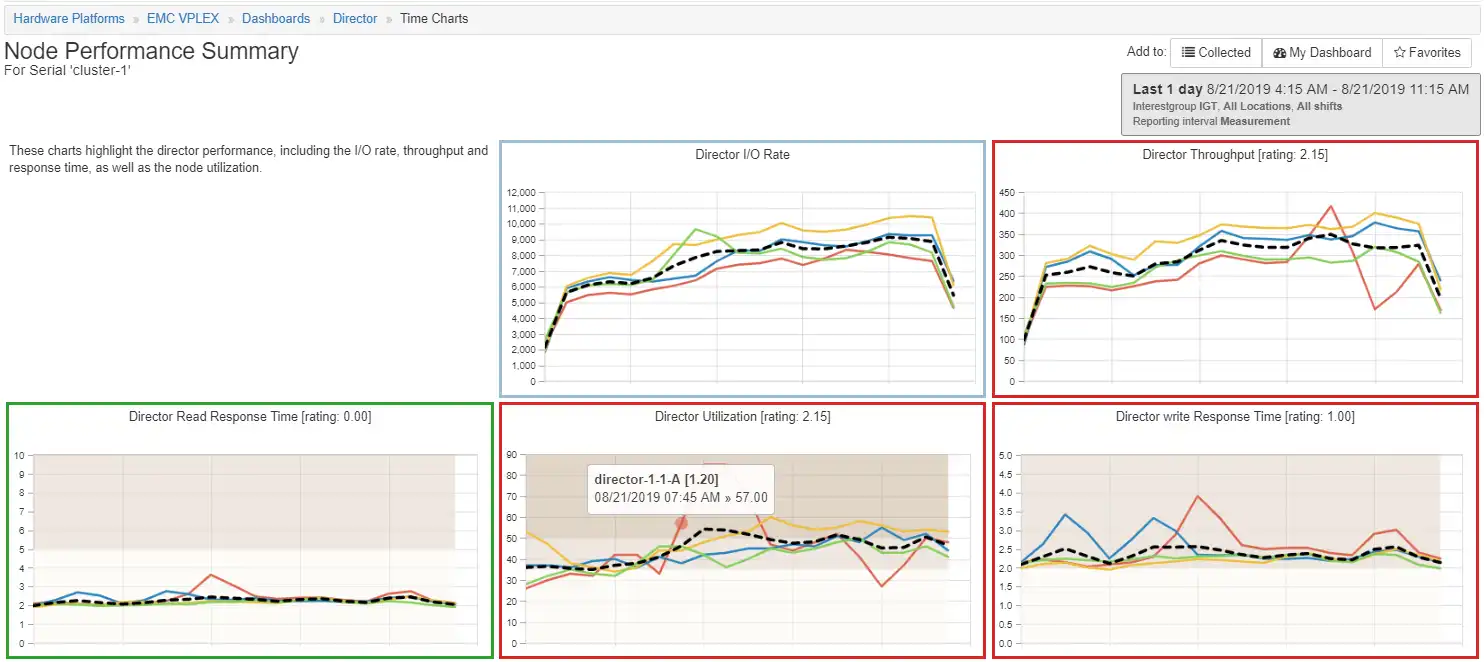
Figure 2: Director Time Charts
The Director Write Response Time and Director Utilization have a significant peak occurring at 8:00 AM on director-1-1-A. Drilling down to the port write response time we see that there are only three ports active on director-1-1-A and they all have a spike in response time at 8:00 AM.
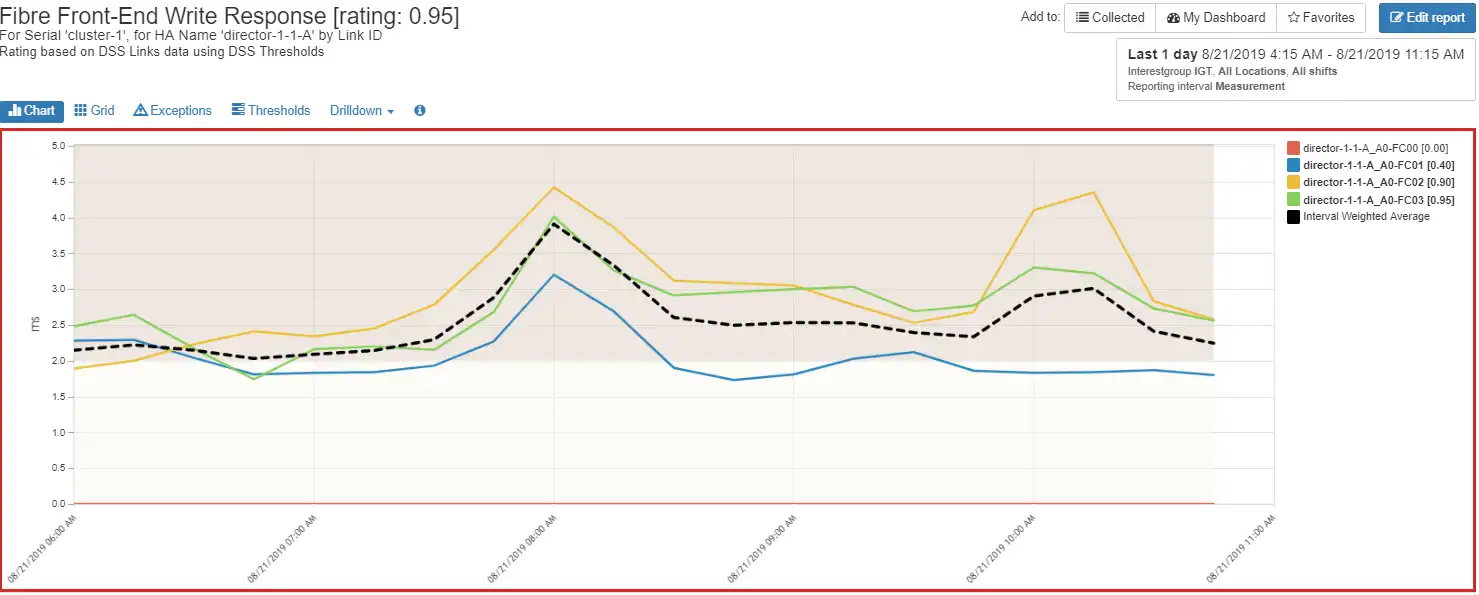
Figure 3: Director Port Write Response Time
Since there was no response time for one of the ports it is a good idea to look at the port activity to see if there is any port activity on that port. By modifying the chart to show throughput we can see there is no activity on port director-1-1-A_A0-FC00 as shown in Figure 4: Port Throughput. We also see that there is a spike in throughput on ports director-1-1-A_A0-FC01 and director-1-1-A_A0-FC02.
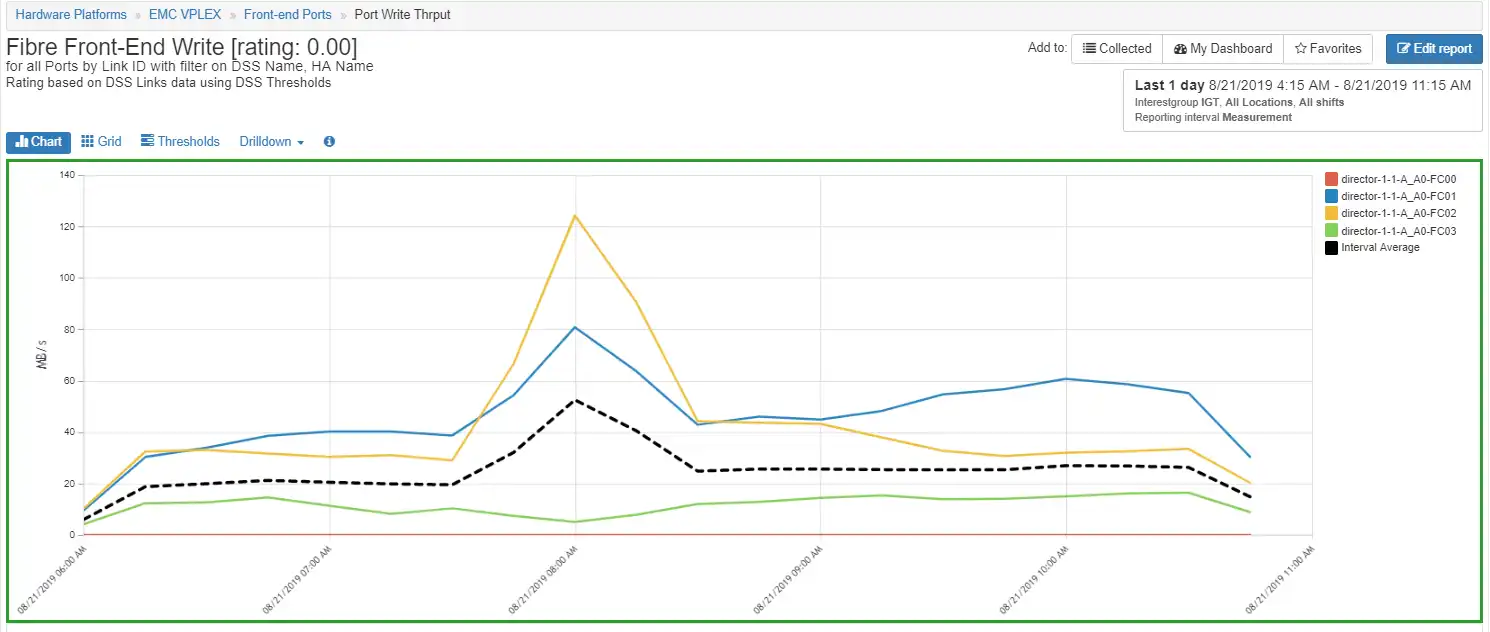
Figure 4: Port Throughput
The port throughput is not very high. These ports are rated at 16 Gbps and operating at a negotiated rate of 8 Gbps and running at a peak of less than 20% of bandwidth. They are not constrained.
Re-cap so far:
We have learned the following:
- There is a performance issue on director 1-1-A at 8:00 AM. The response time increases are most likely a result of high director utilization. We do not know why the director utilization is so high relative to the throughput. The next logical action is to investigate what is causing the increase in the load.
- We have identified that a port is not active on the director 1-1-A. This should be investigated further but is beyond the scope of this blog.
Identifying the Host Culprit
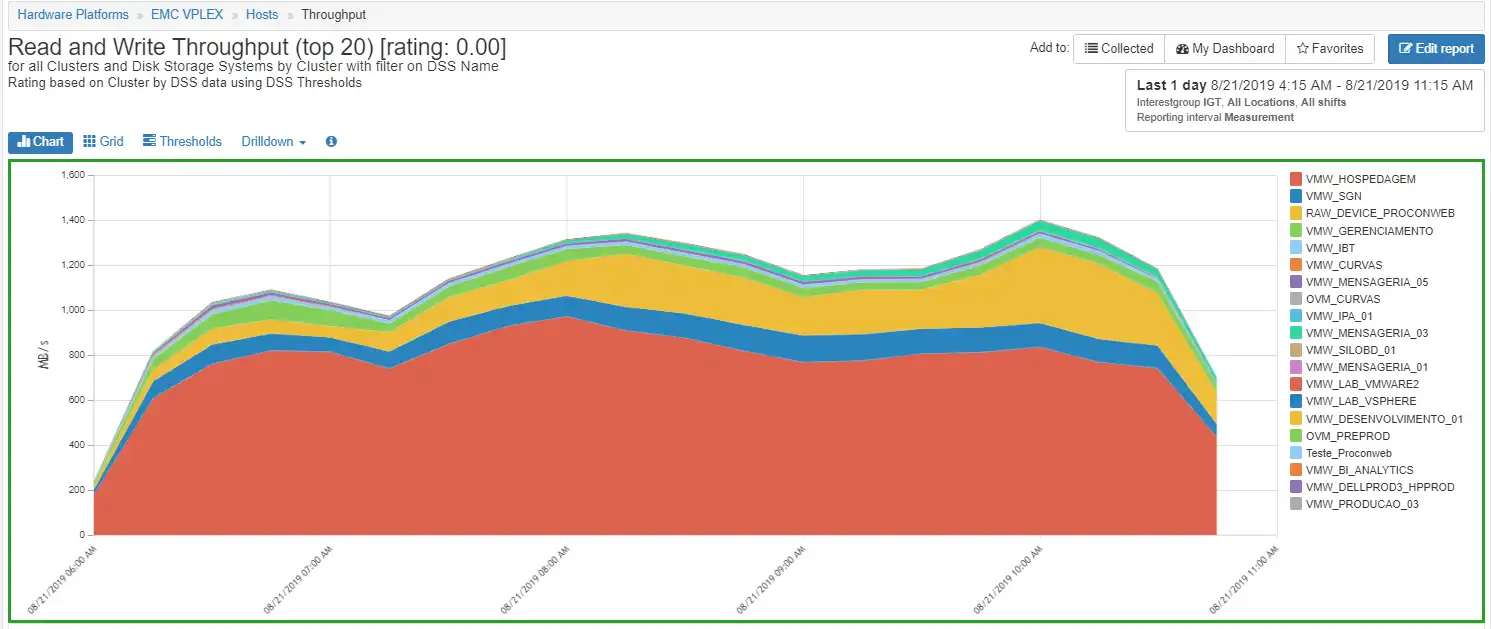
Figure 5: Host Throughput
It becomes easier to see the increase in throughput when you look at the volume throughput by drilling down on the cluster VMW_HOSPEDAGEM as shown in Figure 6: Volume Throughput. The volume VMW_IBM_HOSP_dvol110 has the biggest spike. The next step is to see which ESX VMware system and ESX host this is associated with and look at its port configuration.
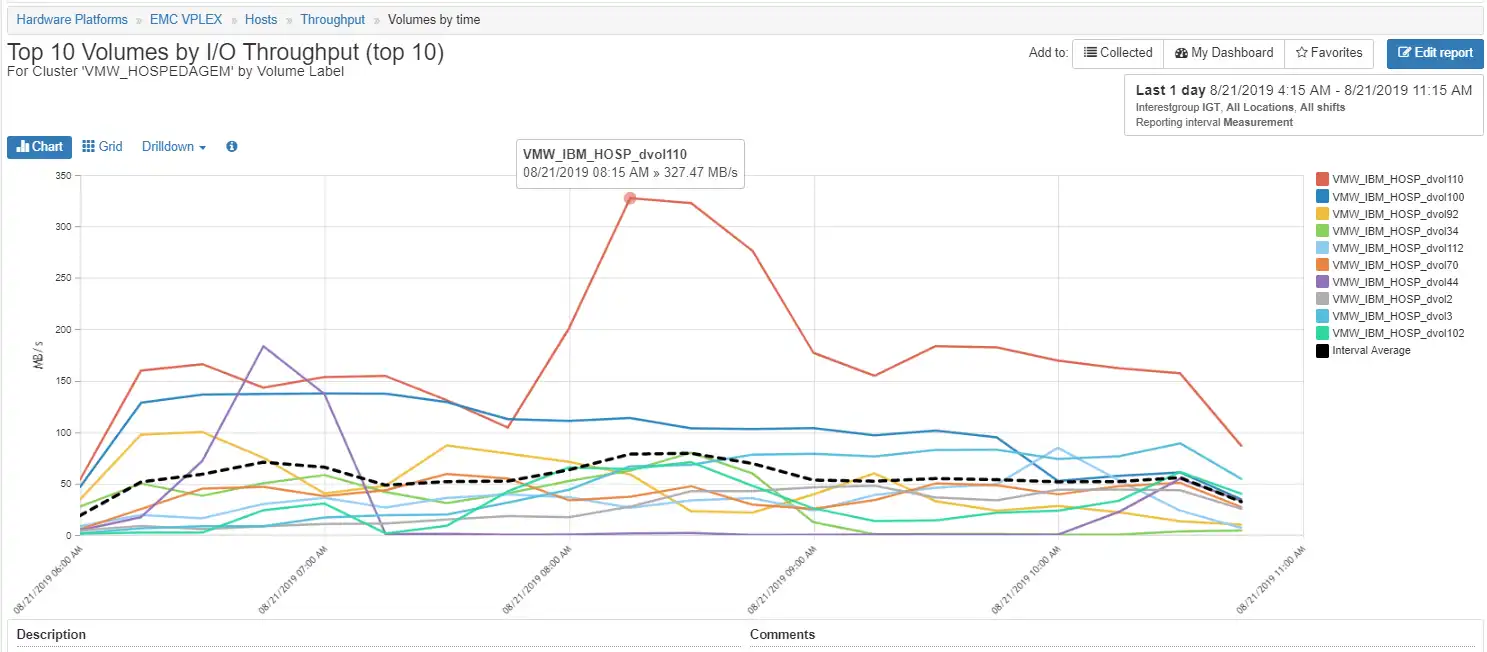
Figure 6: Volume Throughput
At this point we know that the increase is coming from host/masking view VMW_HOSPEDAGEM but we don’t really know exactly which ESX host, as the host name VMW_HOSPEDAGEM represents the entire cluster.
To identify the VM, we look at the VMware performance for datastore with the name VMW_IBM_HOSP_dvol110 as shown in Figure 7: VMware Disk Performance Summary. This chart shows the activity for all the VMs on this datastore. There are several VMs but only one has any significant activity and its name is pxl0dirag001.
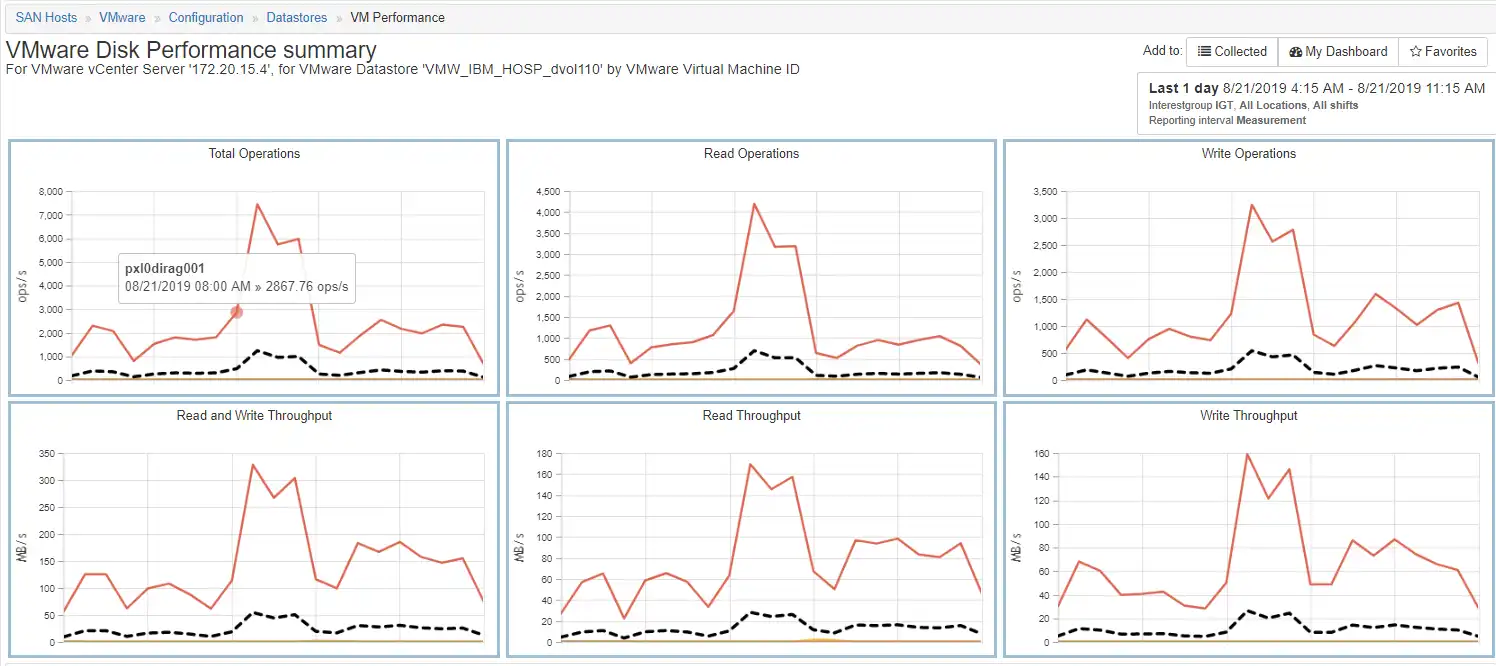
Figure 7: VMware Disk Performance Summary
We can see how it connects by clicking on the current host and selecting the VM to volume drill down which shows us the topology mapping.
This host seems to be configured correctly and the zoning shows four initiators and four target ports, one going to each director in cluster-1. The workload is balanced evenly across the four initiator ports and the target port on director-1-1-A is director-1-1-A_A0-FC01 which was one of the busiest ports as identified previously.
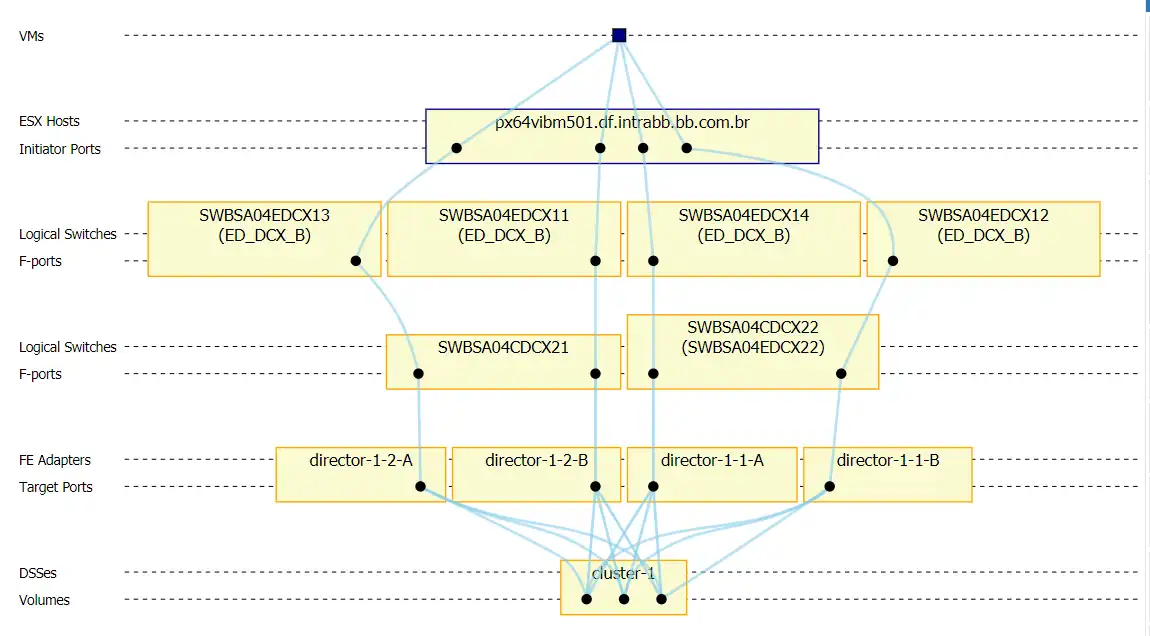
Figure 8: VM Topology Mapping
In Summary
In this we blog examined a particular performance issue on a Vplex system, specifically, we examined a director that had high write response time and high director CPU utilization. We then drilled down to the host that was driving the load and identified the busy volume. After that we used IntelliMagic Vision to identify the VMs on the datastore in question and examined the topology mapping to ensure that there were no configuration or performance imbalances.
Sometimes the work of a performance analyst results in a smoking gun and sometimes it just ends in a cloud of smoke. This was one of those cases where there was a lot of smoke and you have to draw logical conclusions.
Based on the available measurements, it appears that the EMC VPLEX director utilization does not scale well with its available port bandwidth. Likely, the Director utilization is influenced by other factors such as the performance of the back-end storage and replication which were not analyzed in this blog.
This article's author
 Brett Allison
Brett Allison Share this blog
Related Resources
How to Manage Performance in Dell EMC VPLEX Environments
Managing performance in a virtualized storage environment can be tricky. See how you can manage performance not only on the front-end Vplex, but its back-end arrays.
Improve Collaboration and Reporting with a Single View for Multi-Vendor Storage Performance
Learn how utilizing a single pane of glass for multi-vendor storage reporting and analysis improves not only the effectiveness of your reporting, but also the collaboration amongst team members and departments.
A Single View for Managing Multi-Vendor SAN Infrastructure
Managing a SAN environment with a mix of storage vendors is always challenging because you have to rely on multiple tools to keep storage devices and systems functioning like they should.
Request a Free Trial or Schedule a Demo Today
Discuss your technical or sales-related questions with our availability experts today