Organizations that have implemented mature, proactive and predictive Performance Management processes for managing their infrastructure have a much higher level of availability and significantly fewer fires to fight. They also spend less money because the visibility and predictability allows them to maintain more effective storage configurations.
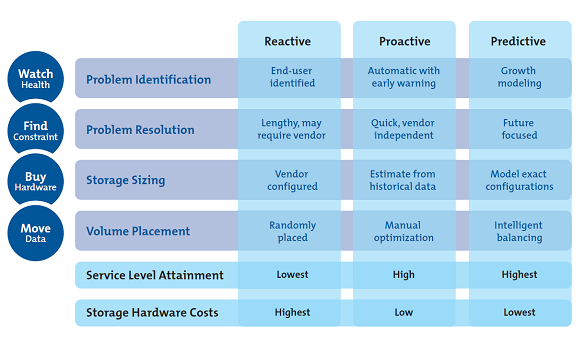
Storage Performance Management Matrix
The various areas and stages of robust Performance Management as they apply to Storage and Infrastructure are described in the maturity matrix.
Sites where these processes are in an immature stage are characterized by significant manual effort, hardware vendor dependence and reactive incident management. Mature implementations are characterized by deep visibility, automated early warnings, reduction of availability risks, hardware vendor independence, and incident prevention.
-
Reactive
In a reactive environment issues in the infrastructure are detected by real-time monitors after they occurred. Sometimes it’s even left to the end-users to report an incident. Problem resolution often requires support from the vendors since no good tools are available to the internal team.
In a reactive environment, the infrastructure is typically sized by the vendor, making it likely to be oversized. Oversizing does not protect against the risks caused by lack of visibility. Early warning software could have been bought to properly manage the storage performance for a fraction of the extra money that oversizing the configuration costs.
Volume placement is random, or automatic tiering is used based on the vendor’s recommendations, without up front analysis on which tier technologies to use.
-
Proactive
In a proactive environment, most performance problems are identified through detection systems that identify delays, long response times, and SLO violations. Problem resolution takes place without assistance from the vendor, as tools, procedures and skills are in place to resolve problems.
Planning is performed internally using historical data and estimating techniques. The company understands that performance management tools that provide deep insight have a significantly higher return on investment than a severely oversized infrastructure.
Volumes are placed based on best practices and hardware optimization techniques, and if automated tiering is used, the tier usage is closely monitored.
-
Predictive
In a predictive environment, upcoming bottlenecks are identified before they occur. Early detection systems designed to identify whether resource usage approaches internal limits warn well in advance of any risk to production. Availabìlity is protected by the significant reduction in the number of incidents, as well as by deep visibility into replication health.
Analytical modeling software is used to predict the impacts of new applications and regular workload growth. Potential problems are avoided because sufficient time is carved out to plan changes to the environment such as hardware upgrades or optimization of existing hardware.
New hardware is chosen after using vendor-independent modeling. Volume placement is optimized for the entire storage infrastructure using advanced modeling solutions to select the right solution, including the best tier or combination of tiers for the workloads.
In a predictive environment, service level attainment is the highest and availability risks, storage hardware costs and management costs are the lowest.
Interesting Resources
Challenging the Skills Gap – The Next Generation Mainframers | IntelliMagic zAcademy
Hear from these young mainframe professionals on why they chose this career path and why they reject the notion that mainframes are obsolete.
Making Sense of the Many I/O Count Fields in SMF | Cheryl Watson's Tuning Letter
In this reprint from Cheryl Watson’s Tuning Letter, Todd Havekost addresses a question about the different fields in SMF records having different values.
Insights into Subsystem and Hardware Configurations through Topology Views | IntelliMagic zAcademy
Explore mainframe complexities and visualize hardware/software connections with Todd and John in our webinar. Gain insights into ensuring application resilience.