
Splunk® derives its name from spelunking (the recreational activity of exploring caves) with the tie in of exploring vast amounts of data. Splunk has proven extremely useful in many areas of business analytics, and it has opened up a wide variety of data types, data views and analysis options, but there are still gaps. Further, processing vast amounts of mainframe data with Splunk may not be the best approach.
As an outdoorsman, I’m always tinkering with what should be in my backpack for the next adventure. There’s a balance between carrying too much and not having what you need in an emergency. In other words, you need to pack smart. Likewise, anyone with experience in cave adventuring would recommend some key items before descending to the abyss, and a guide is invaluable.
It isn’t really that different in the world of data analysis. In particular, let’s consider evaluating the ‘kitchen sink’ method vs. bringing only the necessary.
Big Data is Easy
Implementing ‘big data’ analytics to identify important actions is both compelling and becoming more economically viable. In fact, like so many other things, the cost of storage and compute have fallen so far that considering petabyte++ data lakes with Watson or Google Analytics is now possible. There is real value in the ability of data science and machine learning to find new relationships in the data.
However, despite today’s inexpensive cost/TB, and cost/GHz CPU, the costs do still add up. In particular, you may be in for a surprise when analytics engines charge by the amount of data processed.
Another item to consider is that most cloud providers give you inexpensive compute and storage, but the costs may increase dramatically if you decide to pump lots of data in and out of the cloud.
If your business model allows and supports Big Data lakes, and you have the compute and funding for it, the costs may not be a problem. Unfortunately, not every problem is solved by throwing petabytes of data through analytics engines to see what interesting correlations pop up.
Smart Data Comparison
Let’s look at the data volume problem with sending RMF/SMF data into a Splunk. The cost of ‘knowing more’ by consuming all of the available data may be easy to justify if doing so allows you to prevent outages and security breaches, but there are limits.
Consider for a moment what that means as it relates to z/OS performance data – a good-sized customer generates about 2 TB/day of compressed RMF/SMF data.
Infrastructure
A decent sized Amazon cloud server will run you $400/month with some reasonably sized disk and I/O performance. (AMZ calculator for EC2 4CPU, 8GB RAM, 6 TB disk).
Some data mining software is sold by the GB processed. As with everything, your mileage will vary, but you will pay. This is not news to anyone.
There are many pricing options in the big data space, but a low-end option of about 100GB/day is going to run you around $600/year/GB. Adding 0’s and multiples for uncompressed data will result in significant cash quickly when considering RMF/SMF data.
It costs you to extract your data from the cloud once you store it there. For example, changing your outbound data requirements for one month from a normal 6 TB, to 60 TB will increase your cloud server cost tenfold.
Support
Many of us have past experience in dealing with complex enterprise environments. It takes people to manage the data collection, gathering, aggregation, transmission, removing duplicates, identifying missing data types, and so on. Automation helps, but changes in your enterprise often will create speed bumps or worse in your automation. At least one person – again your mileage varies – is easily your largest cost.
Consider for a moment, before meandering through vast uncharted data lakes, that there may be some faster and cheaper alternatives. Those alternatives may help you see what you need to see in the cavernous expanse of data that most enterprise IT organizations generate, particularly when we look into the expanse of RMF/SMF data.
A Guide is Great
There is great value in having an expert guide to help find the beauty in some of the Carlsbad or Mammoth cave formations. Consider the time and preparation required for you to research, train, and pack for a one-day expedition on your own, versus the investment in a guided trip. If you aspire to do it on your own, it makes sense to carry the extra necessities and probably build up a few years of experience.
That analogy may help us see that we don’t have the luxury of time to gain experience with new data types, 1000’s of existing metrics and the meaning of whether the metric value is good or bad. Similarly, if you want to spend years and you have tons of money for supplies you could begin to become an expert in the 285 miles of Mammoth cave, but that seems like an approach very few people would undertake.
Smart Data
Instead, let’s consider the level of expertise and integration involved in IntelliMagic Vision, which pares down the thousands of RMF/SMF metrics and automatically provides actionable reports and flexible exports that include meta data on key metrics in a Splunk format. This is a jump start on your path to finding the truth in the big data lakes and dark corners of RMF/SMF data caverns. A ‘smart’ data jump start for your enterprise Splunk integration.
At IntelliMagic, we have leveraged decades of experienced technical expertise to harden some very helpful white box analytics. Ignoring these is like leaving a guide behind and venturing out on your own into the caverns.
Db2 and CICS data alone dwarf the already voluminous SMF/RMF data that many are processing. IntelliMagic Vision now supports CICS and Db2 data. In most IT environments, processing the SMF data for these in your analytics solution represents a 15-fold increase in the volume and cost. If you walk into analysis with ‘blind bias’, which doesn’t really exist anyway, to seek out the nuggets of useful truths, it’s like leaving your headlamp with the guide. You have just handicapped yourself.
Out of the piles of 200 plus RMF/SMF types and subtypes, what makes sense to integrate?
Experts matter.
Blindly comparing CPU consumed by address space to all of the other potential metrics is not likely to explain the cause for the change and what actions could be taken. However, with intelligent reporting focused on action, you may find-with some available drilldowns and detailed meta data-that the increase was the new annual security audit, and it was nothing to be concerned about since the priority of the job was managed by WLM and didn’t create any undue stress in your systems.
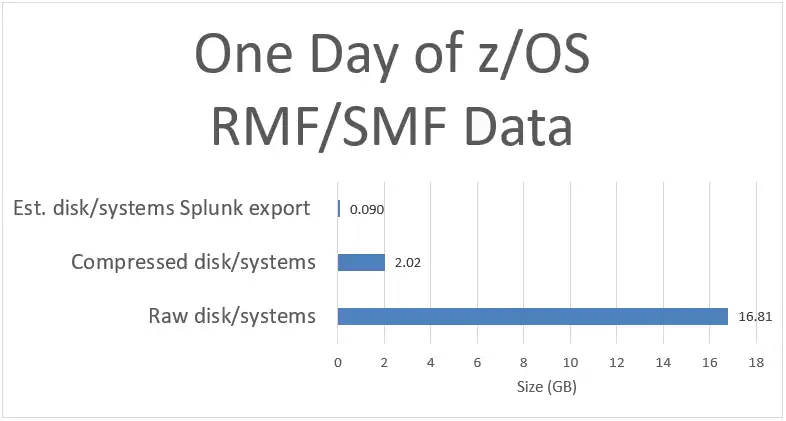
Summary of IntelliMagic “Smart Data” Export (186 times less than the raw data example set)
Lighten Your Load
The real value in a guide is the time savings you gain from his or her experience and the gratification of seeing some stunning scenery.
Choosing to navigate caverns of data with the power of Splunk and other analytics engines has great value. The outcomes can be enlightening, but sometimes they are not actionable.
There is real satisfaction in gaining the experience yourself, however, the technology continues to change, and by the time you have learned about the latest details required to effectively manage zEDC or cryptographic SMF records, there will be changes and newer analysis required as the technology evolves. Furthermore, the time requirement to establish root cause and resolve issues has moved from days to hours and less.
Guiding toward Prevention
We suggest that a coordinated integration with Splunk or other analytics engines will be more valuable by including smart data:
- integrated data
- enhanced with experienced expertise
- that helps determine whether the metric is important and if it is important, what level is good or bad
- and recommended actions in some cases
It’s like taking the guide with you on the trek. It also has the added value of reducing your investment in the ‘big data’ infrastructure and support.
We would welcome an opportunity to make that trek memorable in a good way, and less time consuming and less costly for you and your organization. Your checkbook will thank you, and your integration with other technologies, including Splunk will be improved when you include us on your journey.
This article's author
 Jack Opgenorth
Jack Opgenorth Share this blog
Related Resources
Banco do Brasil Ensures Availability for Billions of Daily Transactions with IntelliMagic Vision
Discover how Banco do Brasil enhanced its performance and capacity management with IntelliMagic Vision, proactively avoiding disruptions and improving cross-team collaboration.
What's New with IntelliMagic Vision for z/OS? 2024.1
January 29, 2024 | This month we've introduced updates to the Subsystem Topology Viewer, new Long-term MSU/MIPS Reporting, updates to ZPARM settings and Average Line Configurations, as well as updates to TCP/IP Communications reports.
From Taped Walls to Your PC: z/OS Configuration Made Simple with Topology | IntelliMagic zAcademy
In this webinar, we explore a technique that integrates diverse data sources from z/OS, presenting them in a clear, concise, and interactive visual format.
Book a Demo or Connect With an Expert
Discuss your technical or sales-related questions with our mainframe experts today