
When looking ahead at 2022, there’s a lot for z/OS performance analysts to consider. Mainframe transaction volumes continue to grow for most sites, and the size and complexity of the z/OS environment is increasing, yet, the number of deep z/OS infrastructure performance experts continues to shrink.
Without the right z/OS performance monitoring practices in place, these challenges can lead to excessive application downtime, lost revenue, customer frustration, burn-out, and more. Even after excluding the direct financial costs, once we consider the true cost of downtime it’s clear why avoiding or preventing service disruptions is the number 1 priority for most mainframe performance teams.
Narrowing down priorities for the year can be difficult, but these three top most lists:
- Ensure Optimal Application Performance and Availability (Zero Downtime)
- Reduce Mainframe Costs
- Improve Staff Efficiency and Resolve the Skills Gap
Utilizing the right strategic and technical plan for your performance monitoring can mean the difference between achieving these goals in 2022 or missing them.
Goal 1: Ensure Optimal Application Performance and Availability
When z/OS technical experts are looking to manage and monitor their z/OS infrastructure performance, it’s logical to seek out a real-time performance monitor. After all, doesn’t it make sense to want to know about a service disruption or application downtime as soon as it occurs?
When the only options are either knowing right away or after end-users report the issue, then yes, knowing right away is the better option. But knowledge about upcoming disruptions that can be prevented before they affect the end-user is much more valuable.
AIOps solutions use built-in expert knowledge about the hardware and a site’s specific workloads to identify potential issues before they ever impact application availability.
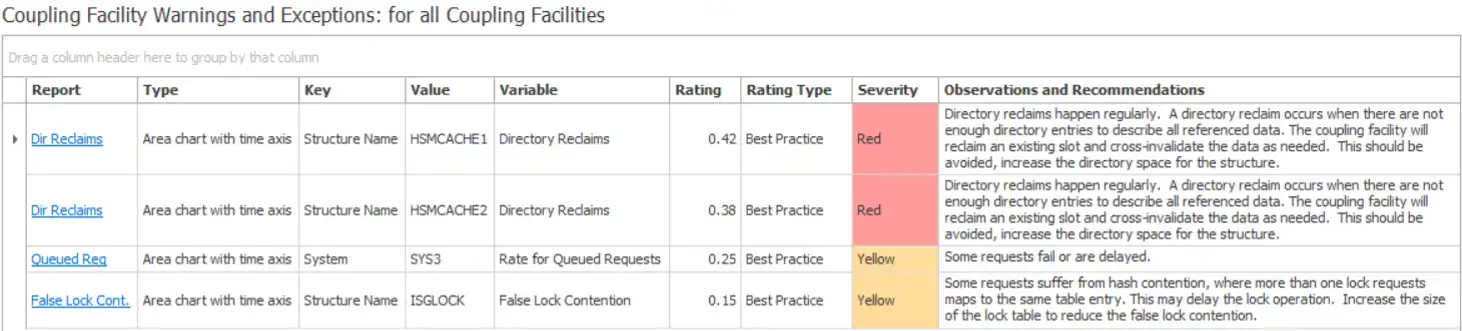 The image above, taken from IntelliMagic Vision for z/OS, shows an exception table for all warnings and exceptions for Coupling Facility and includes a prioritized rating of each issue with built-in recommendations.
The image above, taken from IntelliMagic Vision for z/OS, shows an exception table for all warnings and exceptions for Coupling Facility and includes a prioritized rating of each issue with built-in recommendations.
This report required no coding or report building. The AIOps engine automatically identified and rated each of the performance warnings and exceptions, detailed them, and placed them in this high level report for the expert to analyze and deal with. Better yet, each of these reports comes with extensive built-in drill-downs to make root cause analysis far more efficient and pain-free.
This leads us to our first best practice.
Best Practice #1: Utilize a Predictive Analytics Solution to Eliminate Disruptions
Goal 2: Reduce Mainframe Costs
When it comes to reducing mainframe costs, usually the first culprit is MLC (Monthly License Charges), and rightly so. MLC costs consume up to 30% of some mainframe budgets and if left unchecked can skyrocket out of control.
There are many options available to lower or reduce a site’s MLC costs, from capping and MLC-specific solutions to simple tuning activities that just require the right visibility and knowledge of the critical areas.
From a z/OS performance management perspective, the real key is to lower costs without negatively impacting performance – and those two rarely cooperate with each other.
Our resident MLC expert Todd Havekost has written extensively on the effect that processor cache has on MLC costs. Add to the mix that Tailored Fit Pricing has now “Thrown the R4HA Out the Window” as our expert John Baker puts it, and finding the right way to lower costs just keeps getting more complicated.
Rather than having multiple tools or solutions to optimize or reduce MLC costs and another tool to monitor your z/OS performance, save yourself the money and additional headache and look for an end-to-end performance solution that provides built-in MLC visibility.
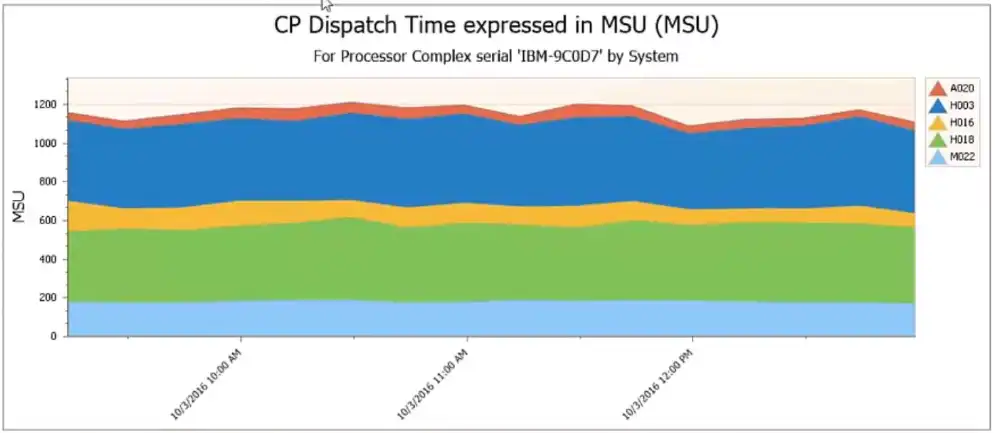
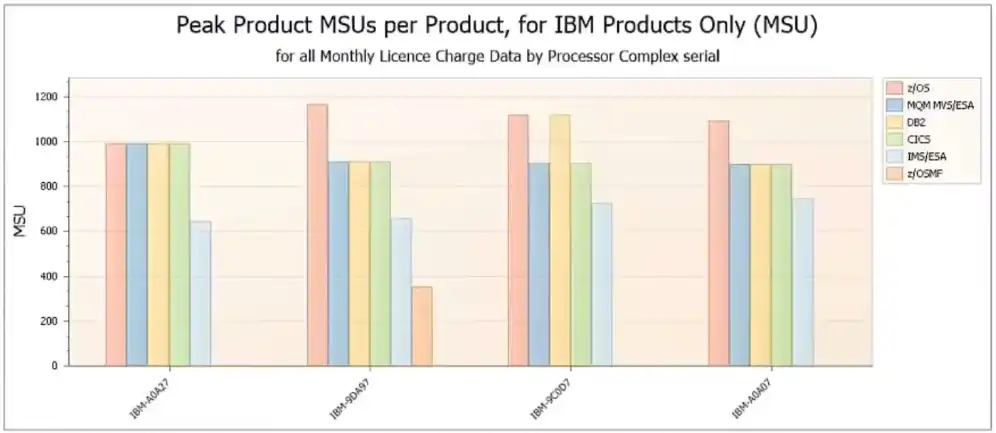
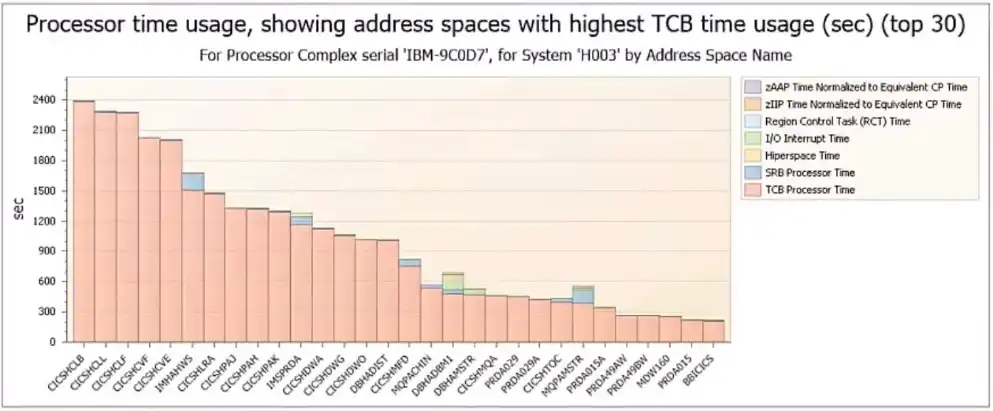 The three images above taken from IntelliMagic Vision for z/OS represent visibility that is critical to understanding what is causing the peaks that drive MLC costs.
The three images above taken from IntelliMagic Vision for z/OS represent visibility that is critical to understanding what is causing the peaks that drive MLC costs.
Best Practice #2: Use a z/OS Monitoring Tool that Lets You Manage Performance AND Lower Costs
But MLC costs are not the only line item that can be lowered with the right visibility. Others include:
- Eliminating emergency hardware purchases
- Purchasing the right amount of hardware
- Purchasing the right amount of flash storage
- Rebalancing workloads and applications
- Avoiding costly mainframe outsourcing mistakes
Clear visibility into your z/OS infrastructure allows you to monitor its performance, but advanced analytical solutions can forecast your workload growth to ensure you’re only purchasing the right amount of storage that you actually need, rather than playing it safe and over purchasing.
Best Practice #3: Forecast Workload and Capacity Growth to Eliminate Guesswork from Storage Purchases
Goal 3: Overcome the z/OS Skills Shortage and Improve Staff Efficiency
Overcoming the mainframe performance and capacity skills shortage and improving IT staff efficiency is essential for the long-term viability of mainframe operations. Otherwise, it’s impossible to ensure optimal application performance.
Even with less heads to pay for, mainframe costs will likely go up rather than down due to the lack of efficiency and paying for likely service disruptions.
If you’ve attended a SHARE conference in the past 2-3 years then you know that there are now numerous initiatives underway to try and fill in the gap left behind by a retiring workforce of deep performance experts. These initiatives are working to hire and train a new generation of mainframe performance analysts, but the process is slow and doesn’t solve the issue of faster skill acquisition.
The fastest way to train the incoming workforce is to equip them with tools that allow them to easily visualize a new environment, pick up on the critical areas, and easily navigate through the data. In his white paper, 5 Key Attributes of an Effective Solution to the z/OS Performance Skills Gap, Todd Havekost writes that such a solution must be:
- Fast and Current
- Visual and Interactive
- Predictive and Contextual
- Versatile with Expanded Applications
- Cloud-based and Collaborative
Having a powerful tool not only trains incoming staff but makes even the deepest subject matter experts more efficient and effective with their time and energy. By eliminating the need for manual SAS and MXG coding or excessive report creation, and by making the sharing of reports and knowledge quick and easy, experts can instead spend the bulk of their time in reducing costs, optimizing performance, and preventing disruptions.
Best Practice #4: Ensure your z/OS Performance Monitor is Easy to Use and Set Up for Quick Skill-Acquisition
Best Practices for Monitoring Your z/OS Performance in 2022
Recent years have changed the game for how RMF (or CMF) and SMF data is used by mainframe performance and capacity teams. The capabilities and expectations for what a z/OS performance monitor can and should do has dramatically shifted. 2022 will push antiquated methods of analyzing and using RMF/SMF data off the table.
In this blog I covered the following Best Practices for z/OS Performance Monitoring:
- Predictive Analytics > Real-Time Monitor
- Use 1 solution with visibility into performance & MLC (and other) costs
- Save on unnecessary storage purchases by forecasting workload and capacity growth
- Make IT staff more efficient and easier to train with an easy to use performance solution
Check out the free webinar series, IntelliMagic zAcademy for additional best practices for ensuring efficient application availability from the z/OS infrastructure.
This article's author
 Morgan Oats
Morgan Oats Share this blog
Related Resources
Why Am I Still Seeing zIIP Eligible Work?
zIIP-eligible CPU consumption that overflows onto general purpose CPs (GCPs) – known as “zIIP crossover” - is a key focal point for software cost savings. However, despite your meticulous efforts, it is possible that zIIP crossover work is still consuming GCP cycles unnecessarily.
What's New with IntelliMagic Vision for z/OS? 2024.1
January 29, 2024 | This month we've introduced updates to the Subsystem Topology Viewer, new Long-term MSU/MIPS Reporting, updates to ZPARM settings and Average Line Configurations, as well as updates to TCP/IP Communications reports.
Top ‘IntelliMagic zAcademy’ Webinars of 2023
View the top rated mainframe performance webinars of 2023 covering insights on the z16, overcoming skills gap challenges, understanding z/OS configuration, and more!
Book a Demo or Connect With an Expert
Discuss your technical or sales-related questions with our mainframe experts today