
In social situations, people sometimes bring up what they do for a living. When I say, “I am a Storage Performance consultant,” I usually get blank stares. When I am asked for more details, I usually reply “I do a lot of modeling.” This often elicits snickers which is entirely understandable. Anyone that has met me knows that I don’t have the physique of a model! When I add that it is MATHEMATICAL modeling that I am talking about it usually clears up the confusion.
In fact, folks are typically impressed, and I have to convince them that what I do is not rocket science. Of course, a lot of rocket science is not “rocket science” either, if you use the term as a euphemism for something very complex and challenging to understand. In this article, I will try to help you understand how computer system performance modeling is done, specifically for disk storage systems. Hopefully, you will have a better appreciation of performance modeling after reading this and know where it can be used and what its limitations are.
Performance Modeling and Queuing Theory
Performance modeling is based on queuing theory. This is a branch of mathematics that describes how long you have to wait in line. Queuing theory has many practical applications in areas such as traffic planning, communications networks, and computer systems.
In graduate school, I did a modeling project that studied the utilization of bathrooms at the university theater during performances. One unique finding from the project was that arrivals to the men’s room followed an exponential distribution, suggesting they were random in nature. Conversely, visitors to the women’s room were hyper-exponential, suggesting that they arrived in bunches. Thus, I was able to prove mathematically with measured data that women do go to the bathroom in groups. It is not just an urban legend!
Discrete Event Simulation
When it comes to computer system modeling, there are different approaches that can be taken. The most detailed approach is a discrete event simulation, sometimes called Monte Carlo simulation.
Doing an accurate discrete event simulation requires a very detailed knowledge of the hardware, software, and interactions. They tend to be compute-intensive and not very reusable. But implemented correctly, a discrete event simulation can be very accurate and provide insight into things like the expected variability of certain performance metrics.
“Back of the Envelope” Modeling
Another common approach is what I call “back of the envelope” modeling. Actually, this is just applying common sense supplemented by a few simple calculations.
For example, if a disk drive has an average base latency (seek + rotational latency + overhead + data transfer) of 10 ms or 0.01 sec, how many IO/sec can it run before it hits 100% utilization? Since a drive can only do one I/O at a time, this is simply calculated as one divided by latency.
In this case, the resulting estimate is 100 IO/sec. This is fine as a first approximation, but in reality modern disk drives include seeking optimization algorithms. When there are queued operations, the average seek time goes down, and the maximum IO/sec will actually be higher. Back of the envelope modeling is useful, but typically relatively rough.
Analytic Modeling
A more rigorous approach is analytic modeling. This uses queueing networks to estimate things like how long a job will take or the response time of an I/O operation. The figure below illustrates how a queueing network may be applied to model storage performance metrics.
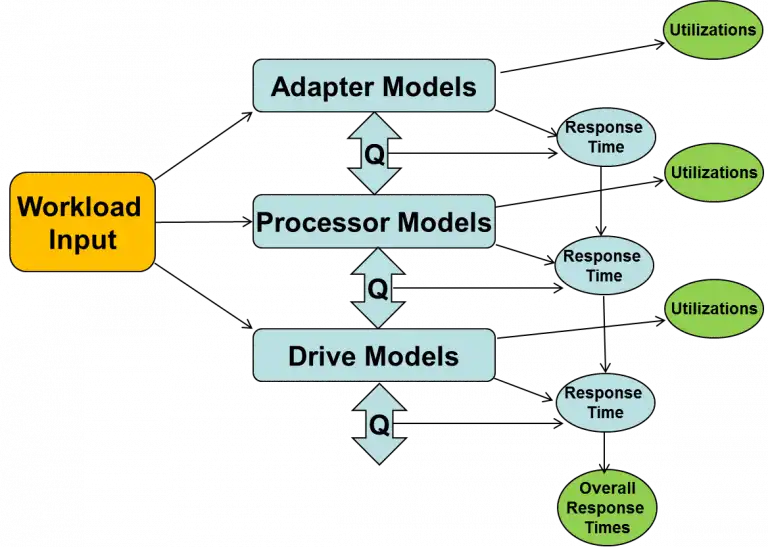
The workload is abstracted in terms of the number of IO/sec, size of I/Os, read and write %, cache hit %, etc. The workload is then parsed and assigned to various hardware components such as adapters, internal processors, channels, drives and internal connections.
These components are modeled based on their capabilities including how many operations per second each resource can handle and how long each operation takes. The subcomponent models calculate queue lengths, queue times, and utilizations.
By adding up all the service times and queue times of the individual component models, the overall response time of the queueing network may be calculated.
Note that this approach only models the average behavior of the system. To gain insight into distributions, a simulation model would be required. However, an accurate measure of average behavior can be very valuable for capacity planning or comparing hardware alternatives.
Analytic Storage Performance Models
IntelliMagic Direction is an example of an analytic storage performance model. IntelliMagic has been developing storage models for over 20 years based on deep knowledge of the internal hardware capabilities. Our original analytic storage performance model was Disk Magic, which IBM has licensed since 1994.
Disk Magic is licensed for IBM and IBM business partners to use in the support of sizing and selling IBM Disk Subsystems and is limited to performance modeling for IBM storage systems whereas the end-user version IntelliMagic Direction provides support for many other disk storage systems including those from IBM, HPE, HDS and EMC.
If you are looking at new hardware acquisitions or just want to have a good sense of how much performance capability is left in your current storage systems, a IntelliMagic Direction study can be very valuable.
With IntelliMagic Direction, your measured peak workload is used as input and expected response times and utilization of your storage components are estimated based on expected I/O growth.
Hardware configuration changes or migration to new storage platforms may be easily evaluated. IntelliMagic also leverages built-in knowledge about the hardware in IntelliMagic Vision, which is a solution focused on proactive monitoring and infrastructure analytics.
IntelliMagic Direction studies are available as a service from IntelliMagic. As part of an IntelliMagic Direction study, IntelliMagic’s experienced consultants use your data to create models and recommend what changes may help optimize your storage performance.
Although some storage vendors offer services, only IntelliMagic can provide an unbiased, vendor independent viewpoint on what will best meet your performance needs.
Do you see modeling in your future? If so, please contact us or email us at info@intellimagic.com and we will introduce you to a “supermodel!”
This article's author
 Lee LaFrese
Lee LaFrese Share this blog
Related Resources
Challenging the Skills Gap – The Next Generation Mainframers | IntelliMagic zAcademy
Hear from these young mainframe professionals on why they chose this career path and why they reject the notion that mainframes are obsolete.
New to z/OS Performance? 10 Ways to Help Maintain Performance and Cost | IntelliMagic zAcademy
This webinar will delve into strategies for managing z/OS performance and costs. You'll gain insights into key metrics, learn how to identify bottlenecks, and discover tips for reducing costs.
What's New with IntelliMagic Vision for z/OS? 2024.2
February 26, 2024 | This month we've introduced changes to the presentation of Db2, CICS, and MQ variables from rates to counts, updates to Key Processor Configuration, and the inclusion of new report sets for CICS Transaction Event Counts.
Book a Demo or Connect With an Expert
Discuss your technical or sales-related questions with our mainframe experts today