
Most IT organizations today are highly focused on expense reduction. For the mainframe platform, this leads to efforts to reduce software expense, which typically represents the largest line item in the infrastructure budget. Since software expense is invariably highly correlated with CPU consumption (either in the near- or longer-term), this places a priority on CPU efficiency.
On modern z processors, cycles spent waiting to stage data and instructions into Level 1 cache constitute at least thirty and sometimes more than fifty percent of total CPU consumption. This leads to the conclusion that without an understanding of this vital role processor cache plays in CPU consumption and clear visibility into the key cache metrics in your environment, significant opportunities to reduce CPU (and software expense) may be missed.
This is the third article in a four-part series seeking to enable readers to achieve improvements in this area. (You can read the first and second articles here.) This article will explore three ways to optimize physical hardware configurations that have the potential to improve processor cache efficiency and thus reduce CPU. They are: (1) On/Off Capacity on Demand; (2) additional hardware capacity; and (3) sub-capacity processor models.
Each of these approaches seeks to increase the percentage of work executing on Vertical High (VH) logical CPs through increasing the number of physical CPs. Restating one of the key findings of the first article, work executing on VHs optimizes processor cache effectiveness because its one-to-one relationship with a physical CP enhances the likelihood that the data it references will already reside in processor cache.
Before examining these approaches in detail, a note about software license models is in order. Pricing quantities of most mainframe software, including IBM Monthly License Charge (MLC), IBM One Time Charge (OTC), and products from Independent Software Vendors (ISVs), have historically been based on the peak four-hour rolling average (4HRA) realized during the billing period. Some sites have recently entered into an “Enterprise Consumption” model for some or most of their software which charges based on all CPU usage for the entire billing interval.
The first technique, On/Off Capacity on Demand, only yields potential savings for 4HRA-based software. The other two alternatives are fully applicable to both license models.
On/Off Capacity on Demand
Sites operating under a peak 4HRA-based software license model for a sizable portion of their products may be able to reduce total expense by leveraging On/Off Capacity on Demand (CoD). On/Off CoD is an IBM offering designed to enable sites to enable and disable physical CPs to meet temporary peak business requirements for hardware capacity.
If monthly peaks occur at predictable time intervals, On/Off CoD can be activated during those peak intervals. Deploying this additional capacity creates more physical CPs and thus more VHs, enabling more of the workload to experience the cache efficiencies of executing on VHs.
For systems where work not executing on VHs experiences a significantly higher Finite CPI, this additional hardware capacity can create a sizable reduction in peak MSUs. And since this temporary capacity can typically be activated with minimal incremental hardware cost, the overall expense outcome can be attractive.[1]
Deploy Additional Hardware Capacity
A second way to increase the number of physical CPs is to install or deploy additional capacity, leveraging a one-time hardware expense to potentially achieve greater, recurring software savings. This concept is equally applicable to 4HRA-based and consumption-based license models.
Traditional mainframe capacity planning has been predicated on the assumption that running mainframes at high utilizations is the most cost-effective way to operate.
Traditional mainframe capacity planning has been predicated on the assumption that running mainframes at high utilizations is the most cost-effective way to operate. The results of multiple processor cache case studies challenge that assumption, indicating that in some environments significant reductions in CPU consumption can be achieved by operating at lower utilizations due to the increased impact that cache effectiveness has on current generation z processors.[2]
Understandably, developing the business case to acquire additional hardware capacity may be challenging. But many sites would not require that business case because they already have a business practice of pre-purchasing additional capacity they do not immediately deploy.[3] But even these sites tend to deploy that previously acquired capacity in a “just in time” manner, rather than reaping the recurring benefits of software expense savings by deploying the surplus capacity as soon as it is acquired.
In either case, whether acquiring additional hardware capacity or deploying previously acquired capacity, the framework for reevaluating this approach is that in most mainframe environments software represents a much larger expense than hardware. If a one-time hardware acquisition expense achieves software savings which are realized on a recurring basis year after year, there may be a strong business case for acquiring or deploying hardware capacity that significantly exceeds the business workload requirements.
One reservation frequently expressed about this approach is that Independent Software Vendor (ISV) licenses are a barrier to deploying surplus capacity because many ISV contracts are capacity-based and not usage-based. Capacity-based ISV contracts can severely limit your operational flexibility unless they are renegotiated to become usage-based. A proactive initiative to renegotiate any capacity-based ISV contracts can place you in the enviable position of having the flexibility to configure your environment in the most cost-effective manner going forward.
MSU/CP Ratio
Another important factor impacting measured CPU consumption that adds to the business case for acquiring or deploying additional hardware relates to the multiprocessing (MP) effect. The MP effect applies to any hardware environment and reflects the fact that adding cores (CPs) increases the overhead required to manage the interactions between physical processors and shared compute resources.
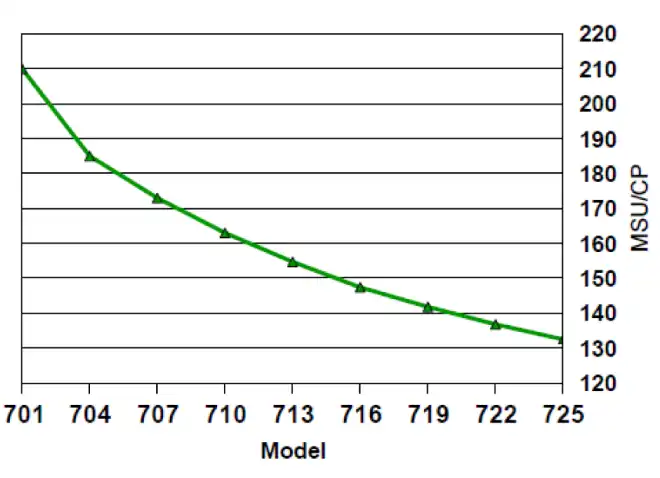
Figure 1: MSU/CP Ratios for Various z13 Models
To account for the typical MP effect when running at relatively high utilizations, the MSU/CP ratios in IBM’s processor ratings are not linear but decrease significantly as more CPs are added. Figure 1 illustrates the decrease in this ratio across several z13 processor models. But if the business workload remains the same when CPs are added, overall processor utilization will decrease and additional overhead from the MP effect is likely to be negligible. In that case, a lower MSU/CP rating can translate directly into lower MSU consumption for the same workload.
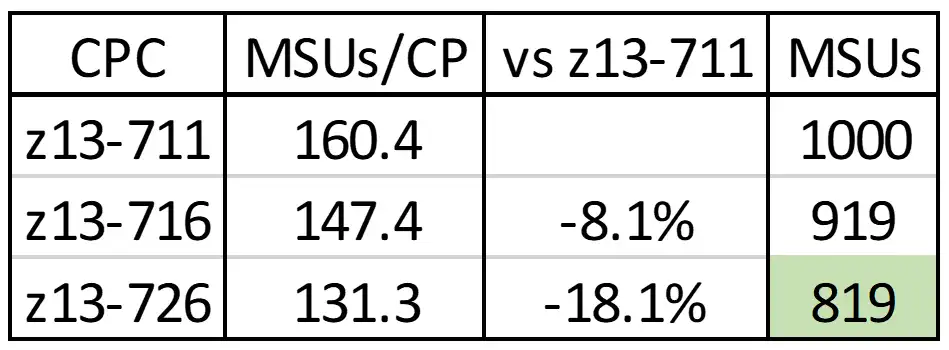
Figure 2: MSU/CP Ratios and Impact on MSU Consumption
Figure 2 compares the MSU/CP ratios for three z13 processor models. Note the decrease of 18 percent in the MSU/CP rating for a z13-726 from a z13-711. With the overhead assumption expressed above, the green value highlights that a workload generating 1000 MSUs on a 711 processor would generate only 819 MSUs when run on a 726, solely due to the reduced MSU/CP rating. This is in addition to the CPU savings from improved processor cache efficiency that would also accompany this change.
The bottom line here is there are two significant benefits of deploying additional hardware capacity while running at lower utilizations that combine to create even larger savings. First, less CPU is consumed due to operating efficiencies from more effective use of processor cache (along with other operating system efficiencies that also result from running at lower utilizations). And second, the CPU that is consumed translates into fewer MSUs, due to the decrease in the processor MSU/CP ratings.
Sub-Capacity Processor Models
A third way to increase the number of physical CPs is to utilize sub-capacity processor models, which deliver more physical CPs for the same MSU capacity. These additional physical CPs enhance processor cache efficiency without incurring additional hardware expense, by (a) increasing the amount of Level 1 and 2 processor cache and (b) increasing the workload executing on VH logical CPs.
The suitability of sub-capacity models for a given environment needs to be carefully evaluated, taking into account the slower single engine speeds of these models along with overall limitations on total processor capacity. But keep in mind that even if production workload capacity requirements require full-capacity models, processors supporting development and test LPARs are often prime candidates to reap the potential cache efficiencies provided by sub-capacity models.

Figure 3: z14 Models with Similar Capacity Ratings
Figure 3 shows multiple z14 models that have MSU capacity ratings comparable to a z13-709. Opting for sub-capacity models in this example would result in seven to 15 more physical CPs than the full capacity z14-708, significantly increasing the available processor cache and workload executing on VHs. The selection of a sub-capacity model would likely result in additional realized capacity due to the CPU savings resulting from increased processor cache efficiency, even though all the rated capacities (and thus hardware acquisition costs) would be comparable.
Use Case: Sub-Capacity Processor Models
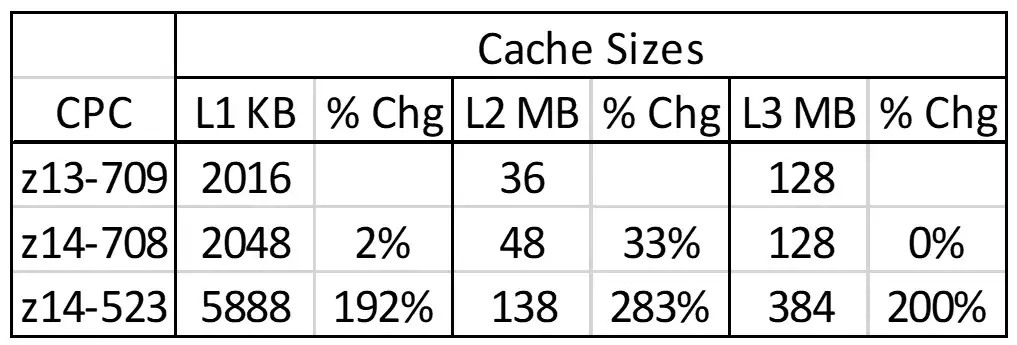
Figure 4: Configured Cache Sizes for Processor Model Options
The following use case shows the increase in overall delivered capacity one site experienced from implementing a sub-capacity processor model, and how those processor cache benefits were reflected in the pertinent metrics.[4] Figure 3 showed the options for a lateral upgrade (with comparable MSU ratings) from a full-capacity z13-709 to a (1) full-capacity z14-708 or (2) sub-capacity z14-523. Figure 4 quantifies the tripling (or more) in configured processor cache across the first three levels resulting from selection of the sub-capacity model.
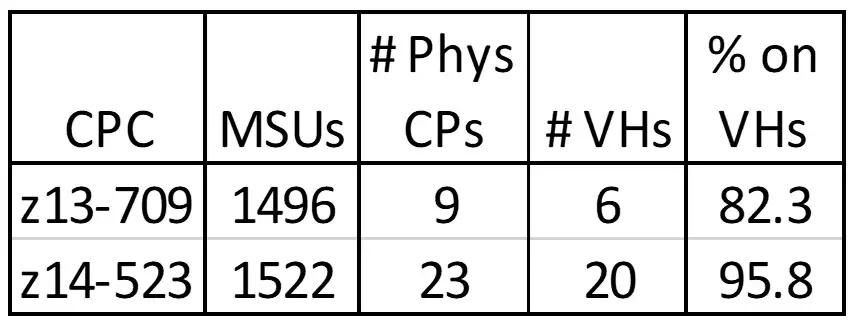
Figure 5: Increased Workload Executing on VHs
The more advantageous vertical CP configuration enabled by the additional physical CPs resulted in an increase in the workload executing on VHs from 82% to 96% (see Figure 5). Even though the 15% VM penalty this workload previously experienced when executing on the z13 was modest, this almost entire elimination of work not executing on VHs was a key contributor to the significant decrease in Finite CPI (waiting cycles) seen in Figure 6.
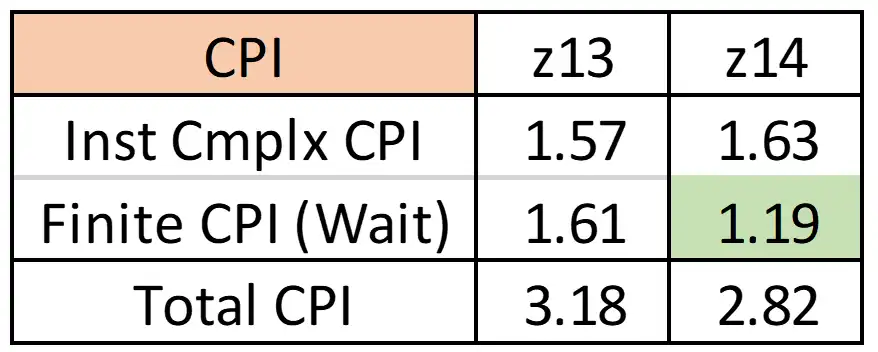
Figure 6: Impact of Upgrade on Cycles Per Instruction by Component
Figure 7 quantifies that this significant improvement in CPI for the workload in this use case translated into an increase in delivered capacity of 17% from what was essentially a “lateral” upgrade (see Figure 7). This outcome that far exceeds the 2% increase in the rated MSU capacities between the two models reflects processor cache efficiencies experienced from the additional cache and additional workload executing on VHs.
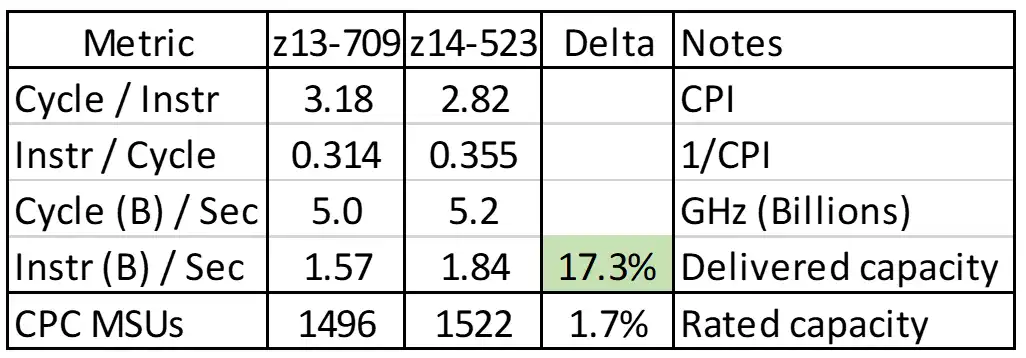
Figure 7: Delivered Capacity vs. Rated Capacity
This increase in delivered capacity translated into reduced CPU consumption for the business workload, reducing the monthly peak 4HRA by 22%, which generated MLC savings exceeding $1M annually [Kyne2018]. This site is realizing significantly more capacity from the sub-capacity z14 model, even though the rated capacity was essentially the same as the full capacity z13 model. The results of this case study reinforce the prominent role processor cache efficiency can play in CPU consumption.
Summary
Processor cache performance plays a more prominent role than ever before in the capacity delivered by z processors, beginning with the z13 and continuing with z14 and z15. And this is a trend that can be expected to continue due to the engineering challenges associated with increasing cycle speeds.
Since unproductive cycles spent waiting to stage data into L1 cache represent a significant portion of overall CPU, it is incumbent on the mainframe performance analyst to have clear visibility into the key cache metrics and to leverage those metrics to identify opportunities to optimize processor cache. This series of articles has presented several approaches that have led to reductions in Finite CPI and thus CPU consumption in real-life environments.
The final article in this series will examine key changes in processor cache design for the z14 and z15 processor models and how they contribute to the capacity increases delivered by these newer technologies.
Read Part 4: Impact of z14 and z15 Models on Processor Cache
Sources
[Havekost2017] Todd Havekost, “Achieving CPU (& MLC) Savings Through Optimizing Processor Cache,” SHARE Session #21045, August 2017.
[Kyne2018] Frank Kyne, “Customer Sub-capacity CPC Experience”, Cheryl Watson’s Tuning Letter 2018 #3, pp. 57-75.
[1] See [Havekost2017] for results from one site that effectively used this approach to achieve MLC savings of several hundred thousand dollars annually.
[2] [Havekost2017] contains two published case studies of CPU savings from deploying surplus capacity, and this author has viewed detailed SMF data from a third site. The magnitude of the CPU reductions at all three sites correlates to annual software expense savings in the millions.
[3] Reasons for this practice include negotiating a volume discount or long-term lease, avoiding the procurement effort involved with frequent acquisitions, or acquiring capacity required for seasonal peaks.
[4] See [Kyne2018] for a detailed discussion on the approach used to assess the suitability of a sub-capacity model for the production workload in this case study.
How to use Processor Cache Optimization to Reduce z Systems Costs
Optimizing processor cache can significantly reduce CPU consumption and z Systems software costs for your workload on modern z Systems processors. This paper shows how you can identify areas for improvement and measure the results, using data from SMF 113 records.
This article's author
 Todd Havekost
Todd Havekost Share this blog
Related Resources
Why Am I Still Seeing zIIP Eligible Work?
zIIP-eligible CPU consumption that overflows onto general purpose CPs (GCPs) – known as “zIIP crossover” - is a key focal point for software cost savings. However, despite your meticulous efforts, it is possible that zIIP crossover work is still consuming GCP cycles unnecessarily.
Top ‘IntelliMagic zAcademy’ Webinars of 2023
View the top rated mainframe performance webinars of 2023 covering insights on the z16, overcoming skills gap challenges, understanding z/OS configuration, and more!
Making Sense of the Many I/O Count Fields in SMF | Cheryl Watson's Tuning Letter
In this reprint from Cheryl Watson’s Tuning Letter, Todd Havekost addresses a question about the different fields in SMF records having different values.
Book a Demo or Connect With an Expert
Discuss your technical or sales-related questions with our mainframe experts today