
Software is the primary component in today’s world that drives mainframe expenses, and software expense correlates to CPU consumption in almost all license models. In this blog series, I am covering several areas where possible CPU reduction (and thus mainframe cost savings) can be achieved. The first two blogs (Part 1: Processor Cache, and Part 2: 4HRA, zIIP Overflow, XCF, and Db2 Memory) presented several opportunities that could be implemented through infrastructure changes.
This final blog in the series will cover potential CPU reduction opportunities that produce benefits applicable to a specific address space or application as listed here:
- Write / rewrite programs in Java
- Reduce job abends
- Non-database data set tuning
- Compile programs with current compiler versions and newer ARCH levels
- Database and SQL tuning
- HSM optimization
As was also the case with the prior blogs, many items on these lists may not represent opportunities in your environment for one reason or another. But I expect you will find several items worth exploring which may lead to substantive CPU savings and reduced mainframe expense.
I will briefly address the first three items in this list, and then cover the last three in more detail.
Write or Rewrite Programs in Java
Since Java programs are eligible to execute on zIIP engines, and work that executes on zIIPs does not incur software expense, writing new programs or re-writing high CPU-consuming programs in Java can present a significant opportunity to reduce general purpose CPU and software expense.
Many sites find leveraging Java on the mainframe aligns well with their overall mainframe modernization initiatives. This was the case at one site with a successful initiative developing new RESTful APIs to access z/OS resources in Java. Leveraging z/OS Connect as their primary RESTful API provider, they have a 1700 MSU workload executing on zIIPs that would otherwise have been generating software expense on general-purpose central processors (GCPs).
Java programs also have an additional performance benefit for sites with sub-capacity processors. In contrast to GCPs running at the sub-capacity speed, zIIP engines always execute at full speed, benefiting Java programs executing on those zIIPs benefit.
Reduce Job Abends
Reducing job abends that have to be rerun and thus consume additional CPU can represent an opportunity for sites operating under a consumption-based software licensing model.
The cost saving benefit of avoiding job reruns provides additional impetus to the traditional rationale for wanting to reduce abends, namely avoiding elongating batch cycle elapsed times and their potential impacts on online transaction availability or other business deliverables.
Non-Database Dataset Tuning
Non-database data set tuning represents another opportunity to apply the principle that reducing I/Os saves CPU.
Avenues to explore here include ensuring data sets are using system-determined blocksize and improving buffering for high-I/O VSAM data sets through approaches such as Batch LSR or System-Managed Buffering.
Compile Programs with Current Compiler Versions and Newer ARCH Levels
Since IBM Z machine cycle speeds have been more or less flat since the zEC12 and are likely to remain that way in the future, increases in capacity delivered by each new processor generation are increasingly dependent on other factors. One very important aspect of that is exploiting new instructions added to the architecture for each new model.
IBM hardware chip designers have been working closely with compiler developers for some time now to identify frequently used high level language statements and adding new CPC instructions to optimize the speed of those operations. As each processor model delivers a new set of hardware instructions, that becomes a new architecture (ARCH) level.
A simple way to remember the ARCH level is that it is “n-2” from the processor model, so for example a z15 CPC has an ARCH level of 13.
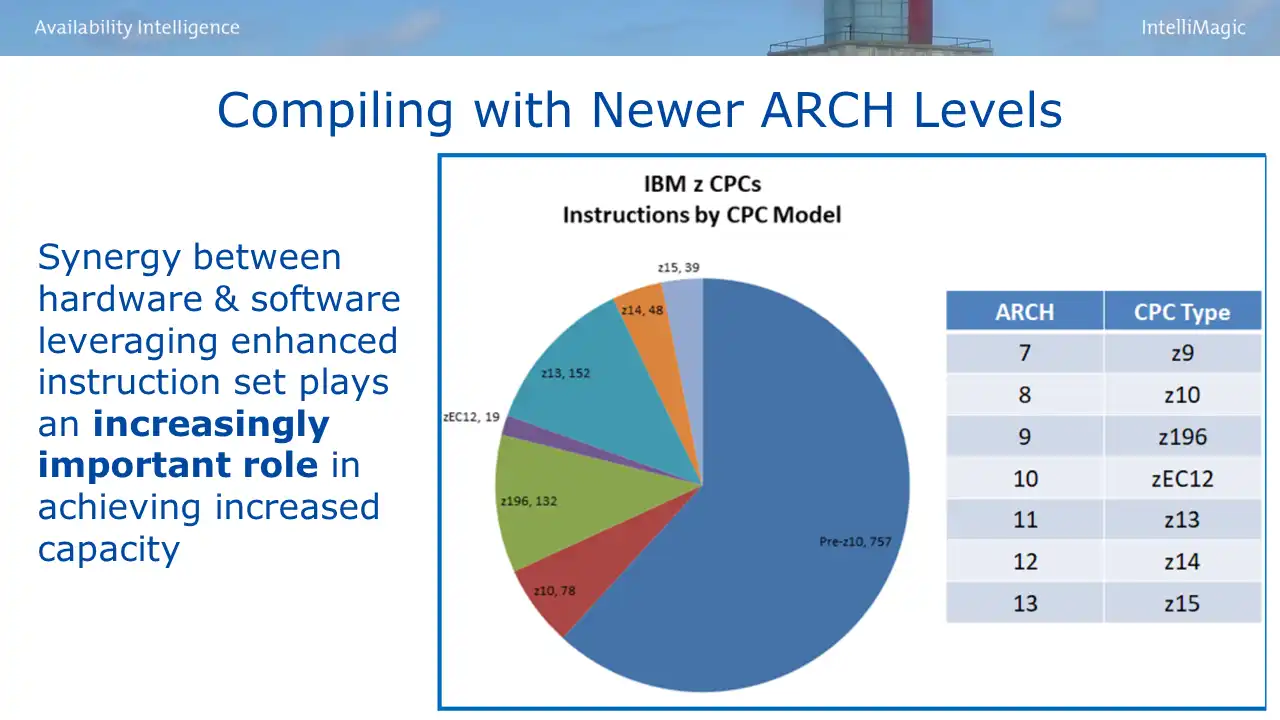
Figure 1: Compiling with Newer ARCH Levels
The pie chart in Figure 1 shows that almost 20% of the current Z instruction set has been introduced since the z13. And the z16 added 20 more instructions.
Programs that have not been recompiled recently with current compiler versions may be missing out on significant efficiencies.
The table in Figure 2 shows an “average” percent improvement for COBOL programs in IBM’s sample mix from one ARCH level to the next (of course your mileage will vary). The IBM graphic on the right of the figure details specific COBOL functionality that was improved for each ARCH level. We see that decimal floating point arithmetic has been a particular point of emphasis.
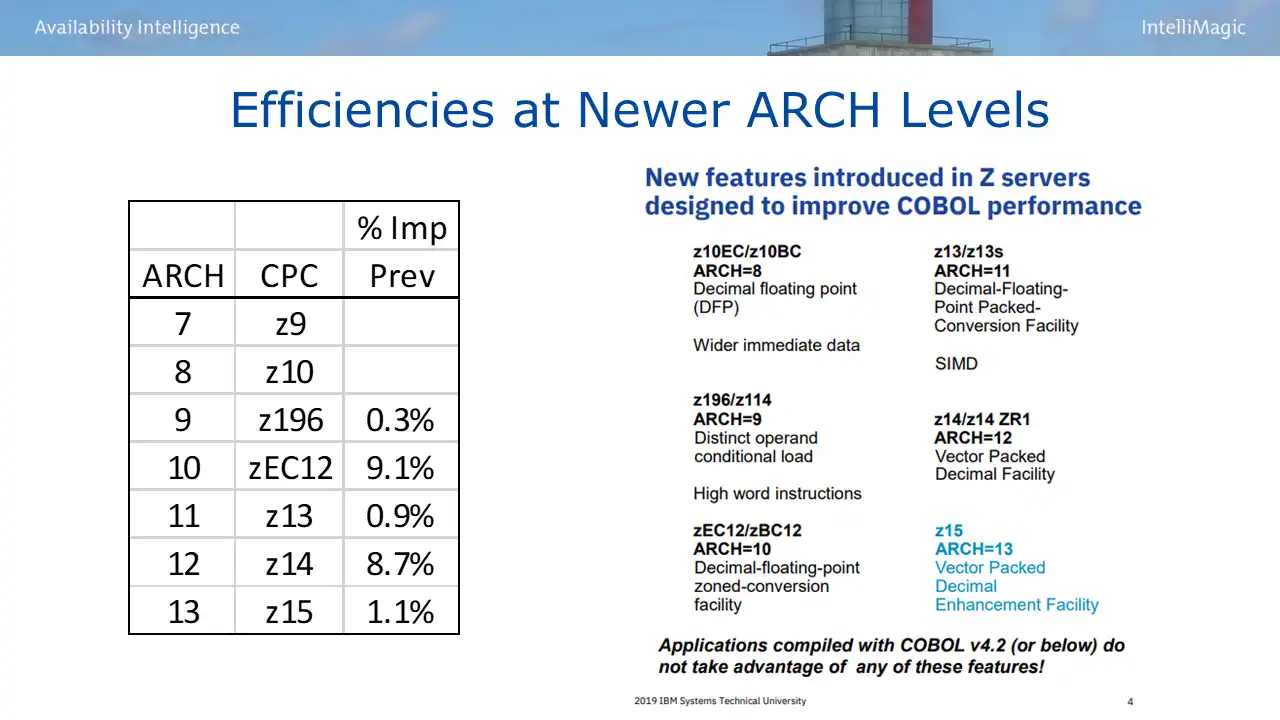
Figure 2: Efficiencies at Newer ARCH Levels
Bottom line, compiling and recompiling COBOL programs with current compiler versions and ARCH levels is probably one of the biggest potential CPU reduction opportunities. This is a message IBM’s David Hutton repeatedly emphasizes in his conference presentations on processor capacity improvements.
Database and SQL tuning
Another area that has the potential to generate significant CPU efficiencies is database and SQL tuning.
The data manipulation capabilities of SQL are extremely powerful, but execution of the requested query can be very resource intensive, particularly since SQL’s advertised ease-of-use often puts coding of queries in the hands of inexperienced users.
To me that feels a bit like handing the keys to your Ferrari to your twelve-year-old. Sure you can do it, but what kind of outcome do you expect?
So giving attention to optimizing high-volume queries and the structures of their associated tables can be a source of major CPU-reduction opportunities. Let’s consider a real-life example of dramatic benefits from a Db2 SQL change.
Figure 3 is an example where visibility provided by a top 10 CPU report can help focus the analysis. Looking here at top DDF consumers, an opportunity was identified involving the second highest CPU consuming authorization ID.
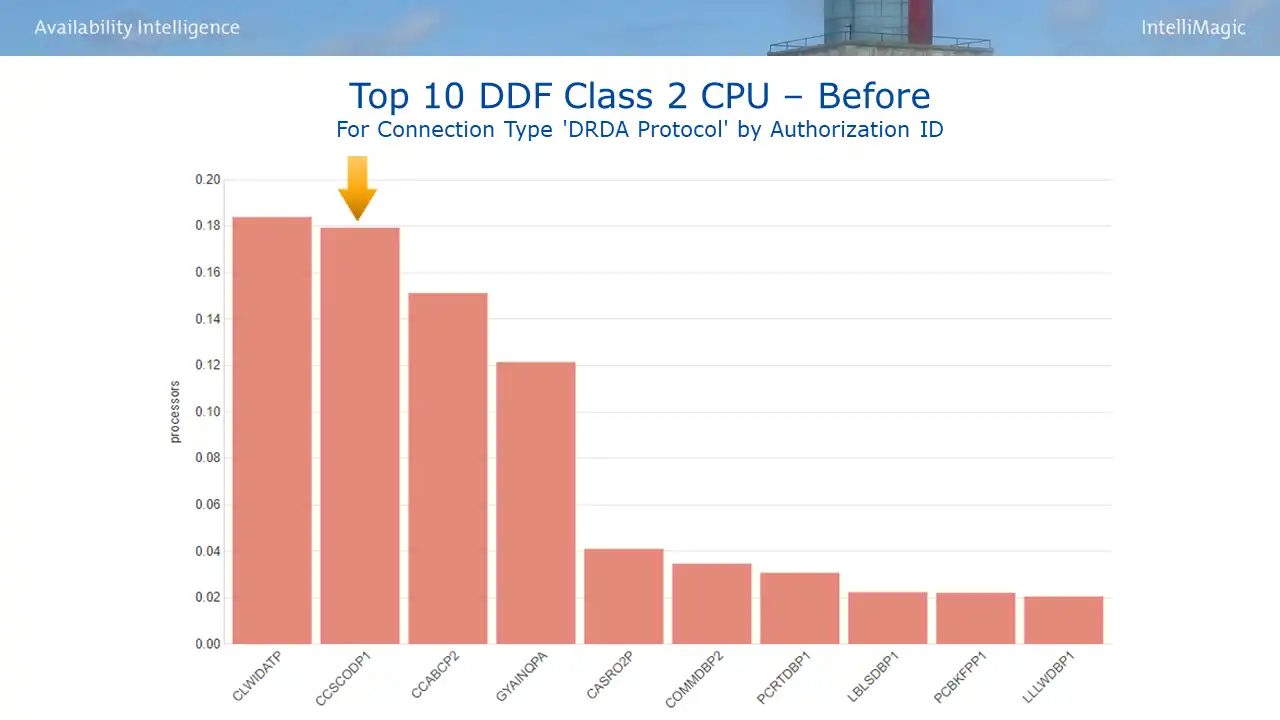
Figure 3: Top 10 DDF Class 2 CPU – Before
CPU reduction efforts can represent a great opportunity for the performance optimization team to partner with Db2 teams in their buffer pool and SQL tuning efforts. The focus of the Db2 team is often on reducing response times by turning I/Os synchronous with units of work into memory accesses resulting from buffer pool hits. They typically seek to accomplish that in one of two ways, by increasing buffer pool sizes, or even better, by optimizing the SQL to eliminate the getpages and I/Os altogether.
The latter took place here – a SQL change that resulted in a dramatic reduction in I/Os (seen in Figure 4). The DBA SQL experts identified a table structure change. (It involved denormalized tables to avoid the need to run summarization calculations on child rows. Denormalization is the intentional duplication of columns in multiple tables to avoid CPU-intensive joins.)
This change reduced I/Os for the affected Db2 page set (red line) from peaks of 20K per second down to 500, a 97% reduction.
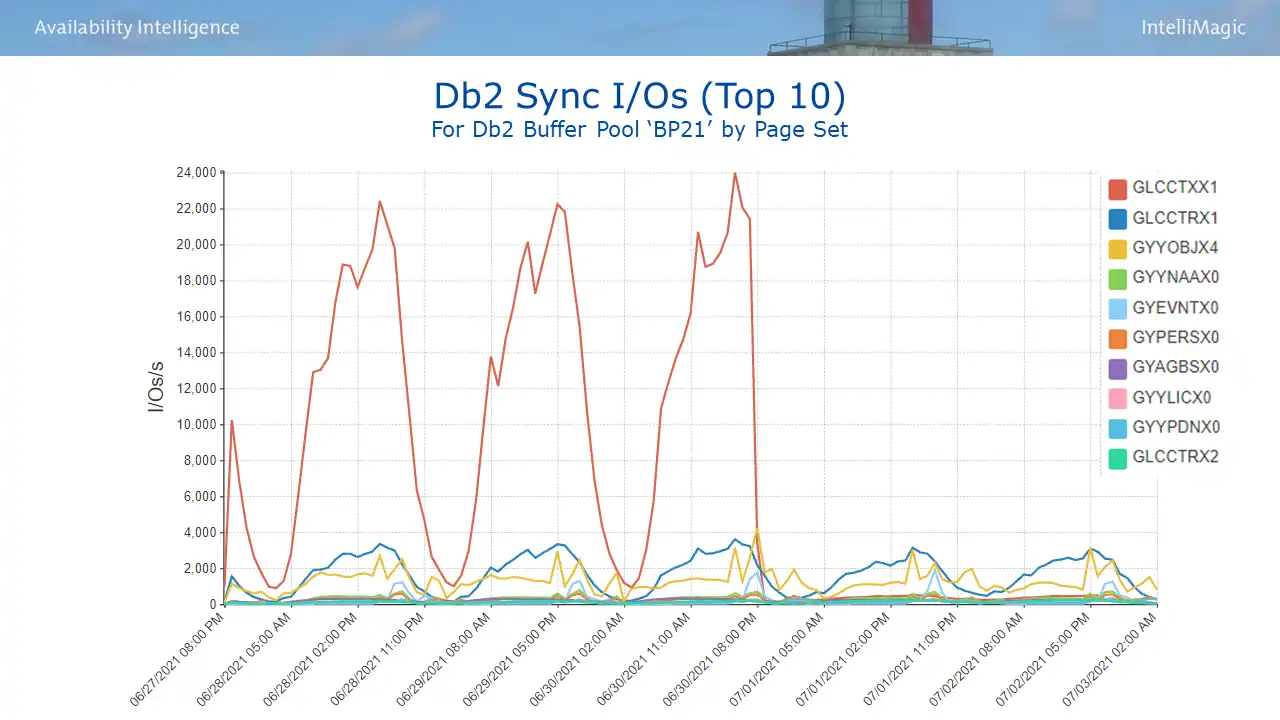
Figure 4: Db2 Sync I/Os (Top 10)
As you might expect, there was a similar magnitude of CPU reduction for the associated authorization ID (shown in Figure 5). This is another application of the principle we have seen across many of the tuning opportunities listed across all three blogs, namely, whenever you can eliminate I/Os, you achieve big wins for both CPU and response times.
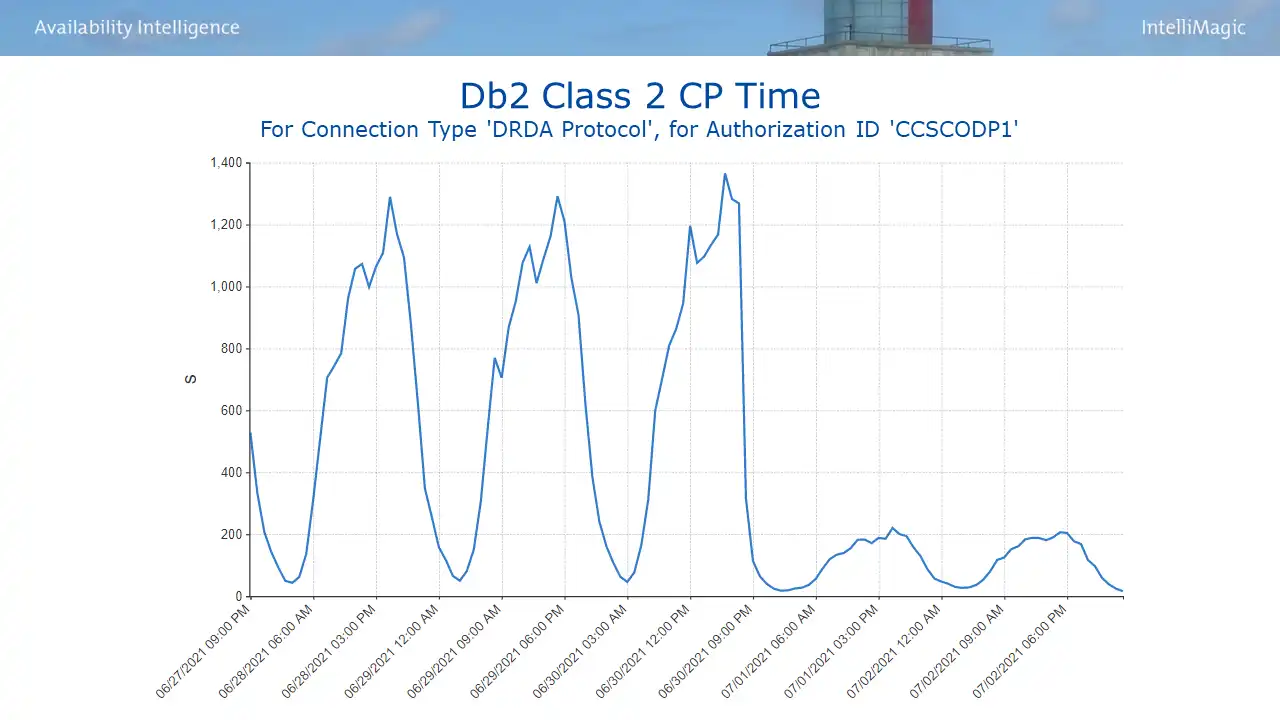
Figure 5: Db2 Class 2 CP Time
Comparing before and after CPU for the affected authorization ID indicated a CPU reduction (15% of a CP) that translated into 175K consumption MSUs annually. And users experienced a 90% reduction in elapsed time per commit (Figure 6). So partnering together with the Db2 team you collectively become heroes not only for saving money but also with users for improved response times.
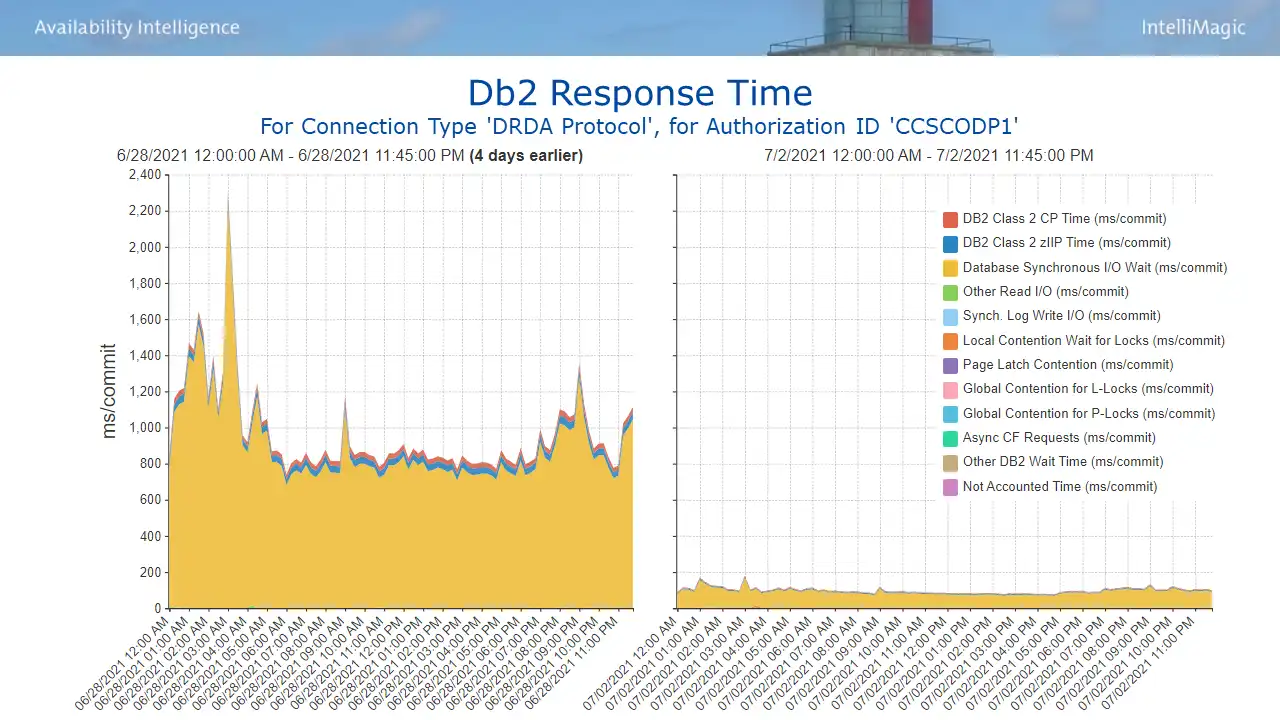
Figure 6: Db2 Response Time
HSM Optimization
The last tuning opportunity we will cover in this blog is HSM.
System-started tasks like HSM are workhorses, performing tasks essential to the functioning and management of z/OS environments. But they can also consume sizable quantities of CPU. I am highlighting HSM here because it is found very frequently in lists like Figure 7 of the “10 Most Wanted” CPU users among system tasks.
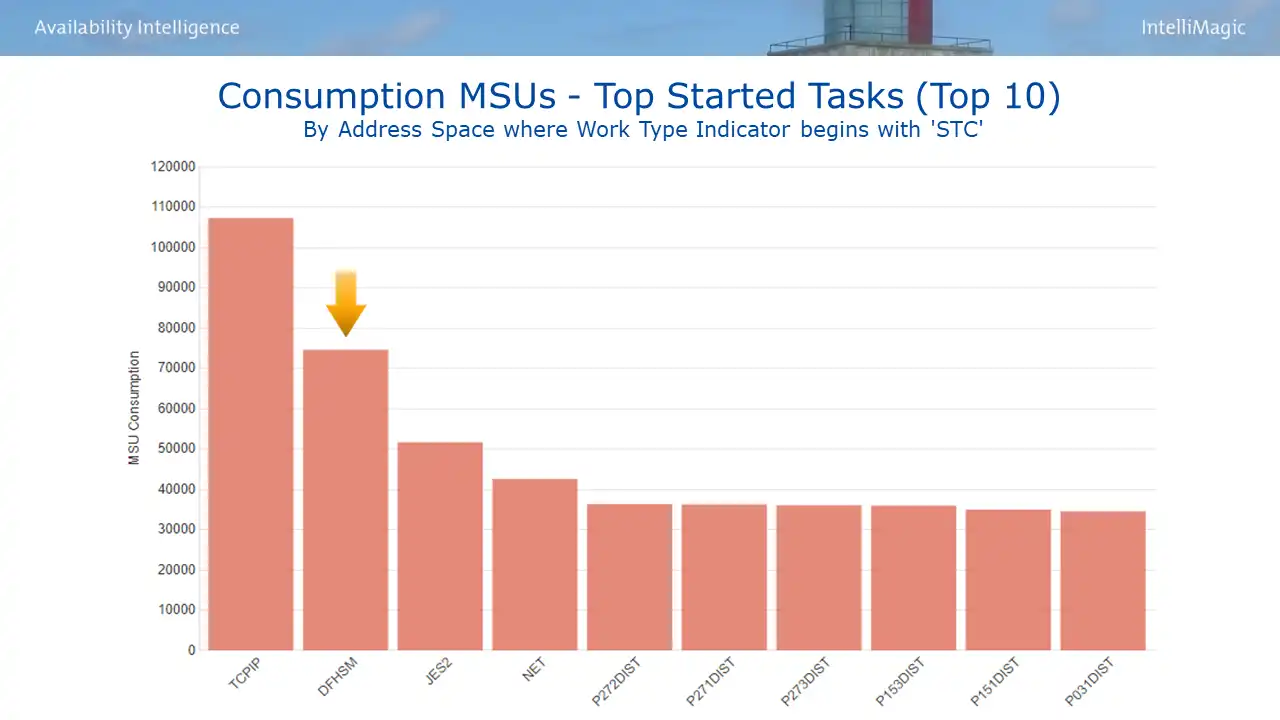
Figure 7: Consumption MSUs – Top Started Tasks
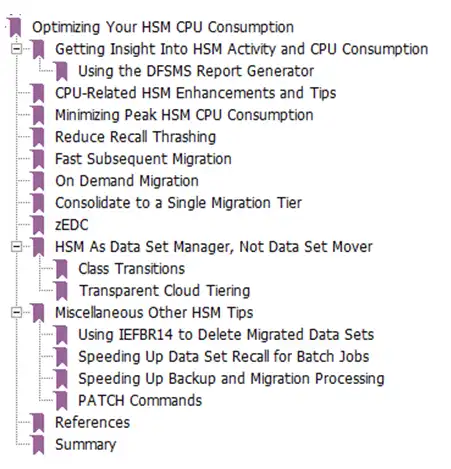
Figure 8: Section Headers from “Optimizing Your HSM CPU Consumption”, Cheryl Watson’s Tuning Letter 2018 #4.
HSM is likely to be a prime opportunity under Tailored Fit Pricing (TFP) Software Consumption licensing models where all CPU is in scope. But I have also frequently seen opportunities for sites using a Rolling 4-hour Average (R4HA) model who had HSM maintenance cycles running during monthly peak intervals.
Fortunately, Frank Kyne and IBM’s Glen Wilcock wrote an extensive article on this subject in the 2018 #4 issue of Cheryl Watson’s Tuning Letter that explained many suggested ways to reduce HSM CPU, as indicated by the section headings captured in Figure 8.
Achieving Mainframe Cost Savings Through CPU Optimization Opportunities
There is a pervasive focus today across the industry on achieving mainframe cost savings, which is primarily achieved through reducing CPU. This series of blog articles has sought to equip teams tasked with leading such initiatives by expanding awareness of common types of CPU optimization opportunities. It has presented a “menu” of opportunities, some broadly applicable across the infrastructure, and others that benefit a single address space or application.
Along with this awareness, optimization teams are aided in their mission by having good visibility into top CPU consumers and top drivers of CPU growth to help focus limited staff resources on the most promising opportunities. Several of the “top 10” views utilized through this blog series facilitate that.
And finally, effective analytical capabilities are essential in order to maximize CPU savings. The multitude of diverse workloads and subsystems in today’s mainframe environments combine to generate a mountain of data, making the capability to rapidly derive answers to identify and evaluate the multitude of potential CPU savings opportunities essential. Time consuming analysis reduces the set of opportunities that can be investigated and thus will inevitably result in missed savings opportunities. Or said another way, the site that can explore and close on ten lines of analysis in the time it takes another site to answer a single query will be able to identify and investigate and implement ten times as many savings opportunities.
The below resources will also be of use to you as you continue on your CPU reduction journey.
- Reporting on Tailored Fit Pricing Software Consumption – Cheryl Watson’s Tuning Letter 2020 No. 3
- Infrastructure CPU Reduction Opportunities in a Software Consumption Environment – Cheryl Watson’s Tuning Letter 2020 No. 4
- Job-level CPU Saving Opportunities in a Software Consumption Environment – Cheryl Watson’s Tuning Letter 2021 No. 1
- Ways to Achieve Mainframe Cost Savings [IntelliMagic zAcademy #42]
IntelliMagic has extensive experience helping our customers identify CPU reduction opportunities. If you would like to explore avenues for savings applicable to your environment, please feel free to reach out to us for a free consultation.
This article's author
 Todd Havekost
Todd Havekost Share this blog
You May Also Be Interested In:
Why Am I Still Seeing zIIP Eligible Work?
zIIP-eligible CPU consumption that overflows onto general purpose CPs (GCPs) – known as “zIIP crossover” - is a key focal point for software cost savings. However, despite your meticulous efforts, it is possible that zIIP crossover work is still consuming GCP cycles unnecessarily.
Top ‘IntelliMagic zAcademy’ Webinars of 2023
View the top rated mainframe performance webinars of 2023 covering insights on the z16, overcoming skills gap challenges, understanding z/OS configuration, and more!
Making Sense of the Many I/O Count Fields in SMF | Cheryl Watson's Tuning Letter
In this reprint from Cheryl Watson’s Tuning Letter, Todd Havekost addresses a question about the different fields in SMF records having different values.
Book a Demo or Connect With an Expert
Discuss your technical or sales-related questions with our mainframe experts today