
Having an optimal processor configuration results in more efficient processor cache usage to get more work done with fewer processor cycles, which is important for reducing CPU cost. Being able to easily see, filter, compare, and interact with the processor topology enables analysts to easily configure their processor configuration.
In this blog, I will discuss and show how interactive topology views can assist in optimizing processor cache usage. If you prefer to jump straight to the video demonstration at the bottom, click the link below.
What is Processor Topology?
During LPAR design, many things are analyzed: workloads, setting appropriate LPAR weights, and specifying the number of logical processors and types that are required. Physical processors rely on different levels of cache to obtain instructions and data necessary to execute the workload. This differs between z series hardware processor generations and is referred to as the processor topology.
Which SMF Records Support z/OS Topology?
SMF 99, subtype 14 HiperDispatch records contain important processor information and should be gathered on each LPAR.
RMF and SMF generate CPU records SMF 70 subtype 1, and the hardware instrumentation services process generates hardware capacity statistics SMF 113’s which are interesting for looking at the cache utilization (i.e. cache misses).
Using Processor Topology for Processor Cache Optimization
LPAR topology can have a very significant impact on processor CPU efficiency. Remote cache accesses can take hundreds of machine cycles; SMF 99.14 records are produced every 5 minutes and capture drawer/node/chip location data for each logical CP.
Visualizations of LPAR Topology data, such as in Figure 1 below, makes this data far easier to analyze and interpret.
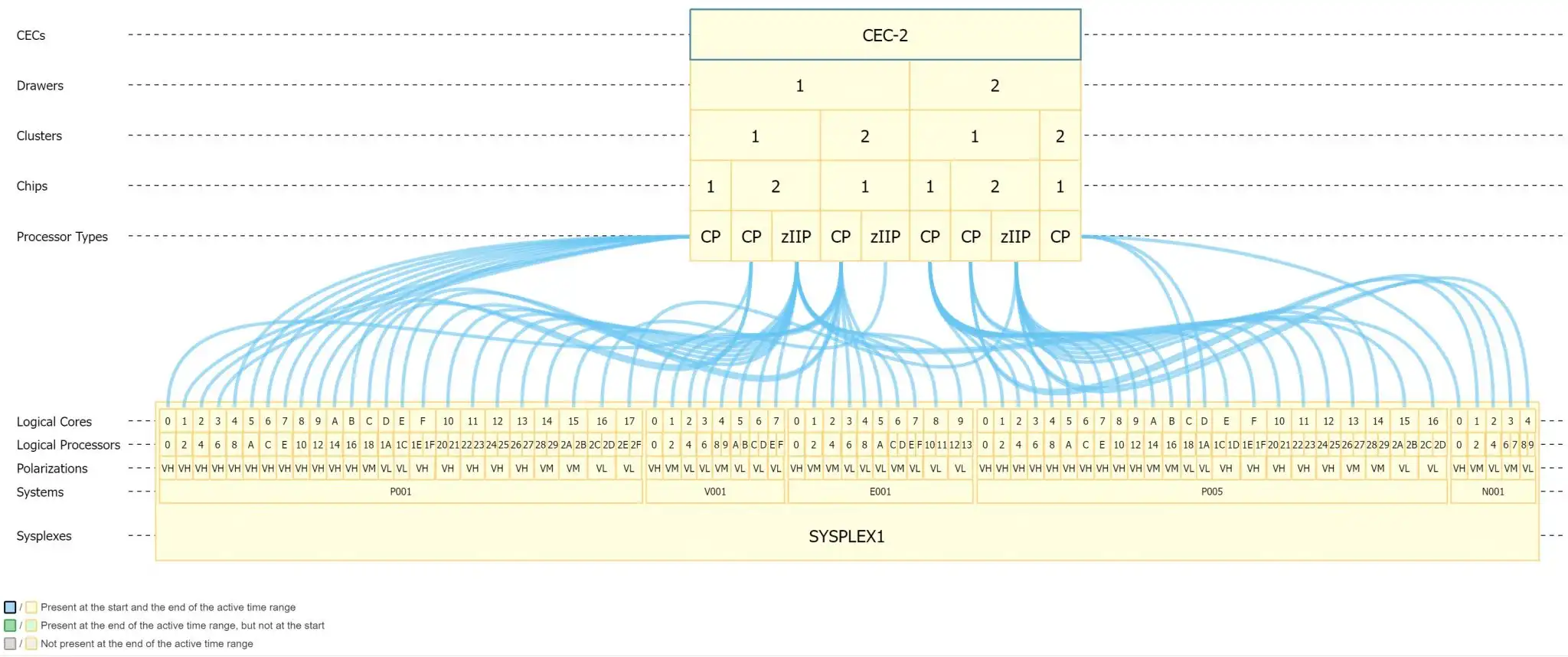
Figure 1: Interactive LPAR Topology Viewer from IntelliMagic Vision
Notice a number of chips and logical cores, polarity of the general processors, and their location on this CEC. Hovering over any component of the visualization will highlight the connection or processor for more information.
From this view, one can see how the vertical high processors, the vertical medium processors, and the vertical low processors are spread across the chips, clusters, and drawers. Work is dispatched on a processor, and it may sometimes be a different one than was originally used. The result is typically an increase in cache misses, which requires many more processing cycles to complete, depending on the configuration.
Processor Cache Usage
Data and Instructions need to be available in level 1 cache in order that they can be used by the physical processors. When work is dispatched, it may be to a different processor than where it was previously running, but it may be to the same physical processor, but that processor is being shared between other LPARs (e.g. a Vertical Low processor). Data and Instructions may need to be retrieved from higher cache levels, which takes time, and the result is an increase in processor cycles for that work.
This data can be seen in the hardware capacity statistics SMF 113 Subtype 1 data produced by the Hardware Instrumentation Services (HIS) process. Here is an example showing the instruction cost comparison (in Processor Cycles per Instruction) between a Vertical High and a Vertical Low processor.
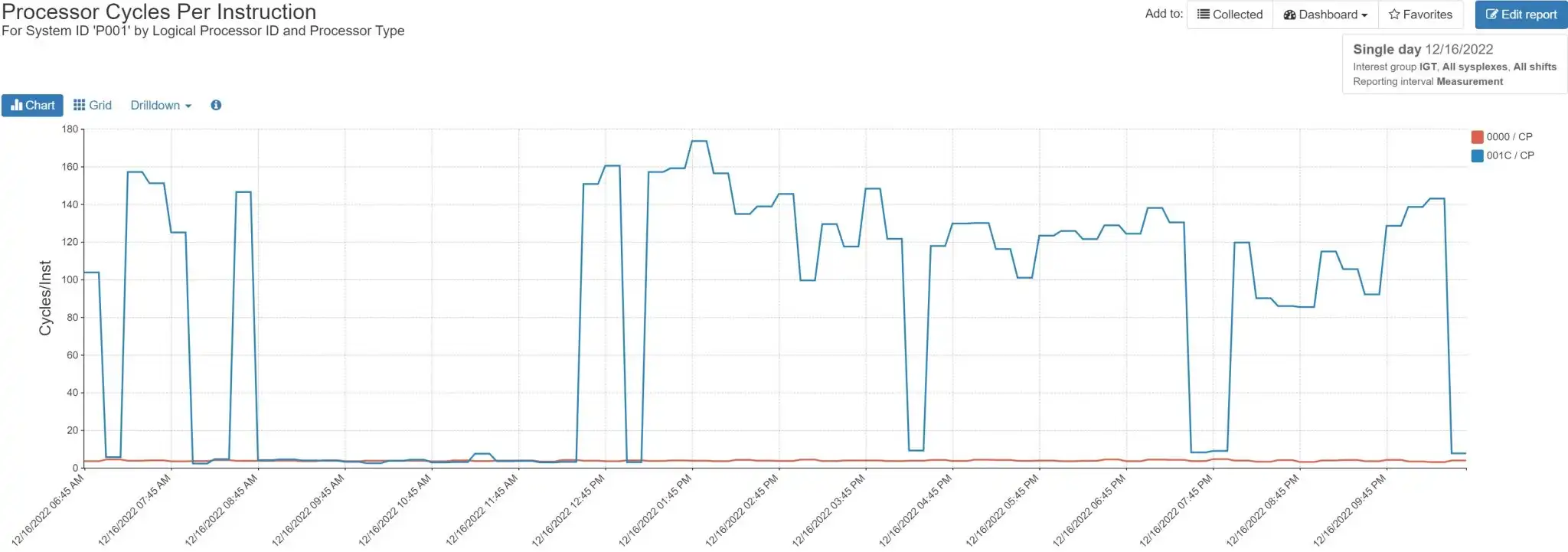
Figure 2: Processor Cycles per Instruction (Vertical High vs. Vertical Low Processors
Note: The primary focus of processor cache analysis is typically on general purpose CPs. Use of that type of processor is reflected in software usage charges. But specialty processors should not be ignored! If your zIIP workload is not running efficiently due to the polarity of the zIIP processors, you may need more zIIP processors and maybe even some of your zIIP workload is running on CPs!
Constraining Views to Evaluate Processor Cache Efficiency
A common way to use an interactive Topology Viewer is to use the available filters or constrains to view only CPs in order to determine the ideal situation for processor cache efficiency.
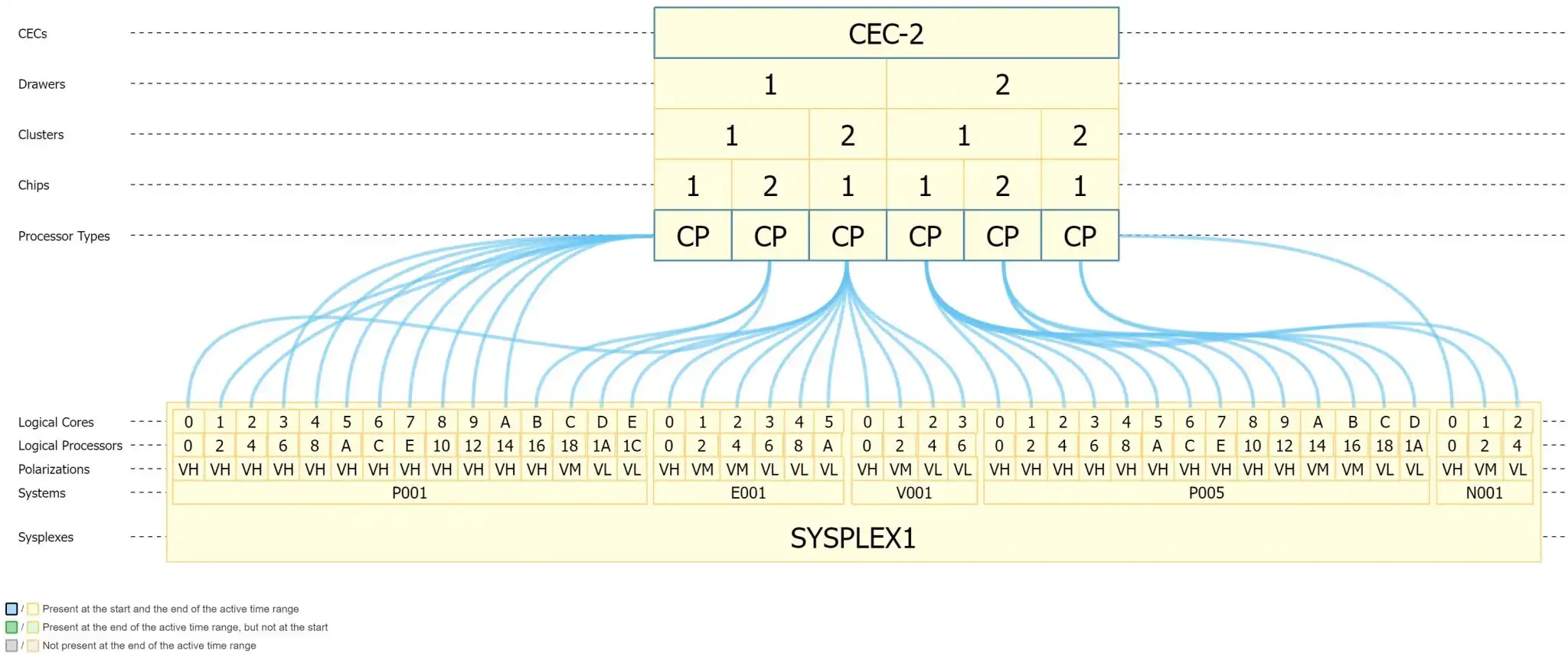
Figure 3: Processor topology constrained to CPs only (zIIPs removed)
We can also look at the zIIP processor topology. The zIIP processors also have a polarity, and one can see here how the vertical highs, the vertical mediums, and the vertical lows are spread across other chips, clusters, and drawers.
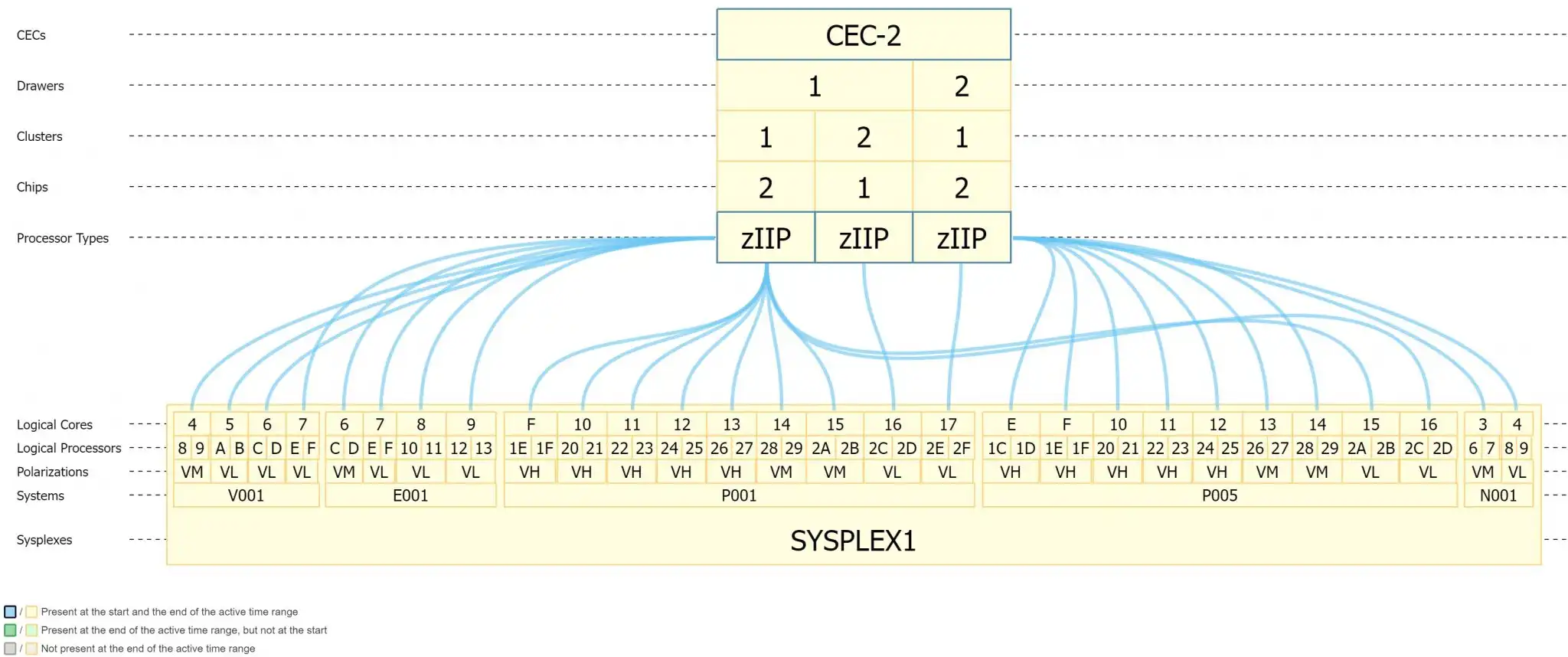
Figure 4: Processor Topology constrained to zIIPs only (CPs removed)
Having the ability to quickly constrain views by CP or zIIP greatly reduces the time needed for an analyst to analyze and interpret the information needed to make important decisions regarding processor cache optimization.
Comparing LPAR Topology Time Intervals to Evaluate Changes
When looking at the LPAR topology, it’s important to realize that the processor assignments could change. The topology may well be different during the peak day online timeframe compared to the evening batch timeframe, for instance. It’s important to be able to easily verify the changes and understand what impact they may have had. In this case, interactivity with the processor topology is crucial.
Figure 5 below compares LPAR topologies between two selected time intervals separated by one day. The legend in the bottom left shows that if there are differences, the color will explain the difference. Hovering over a colored line or box will describe when the change occurred.
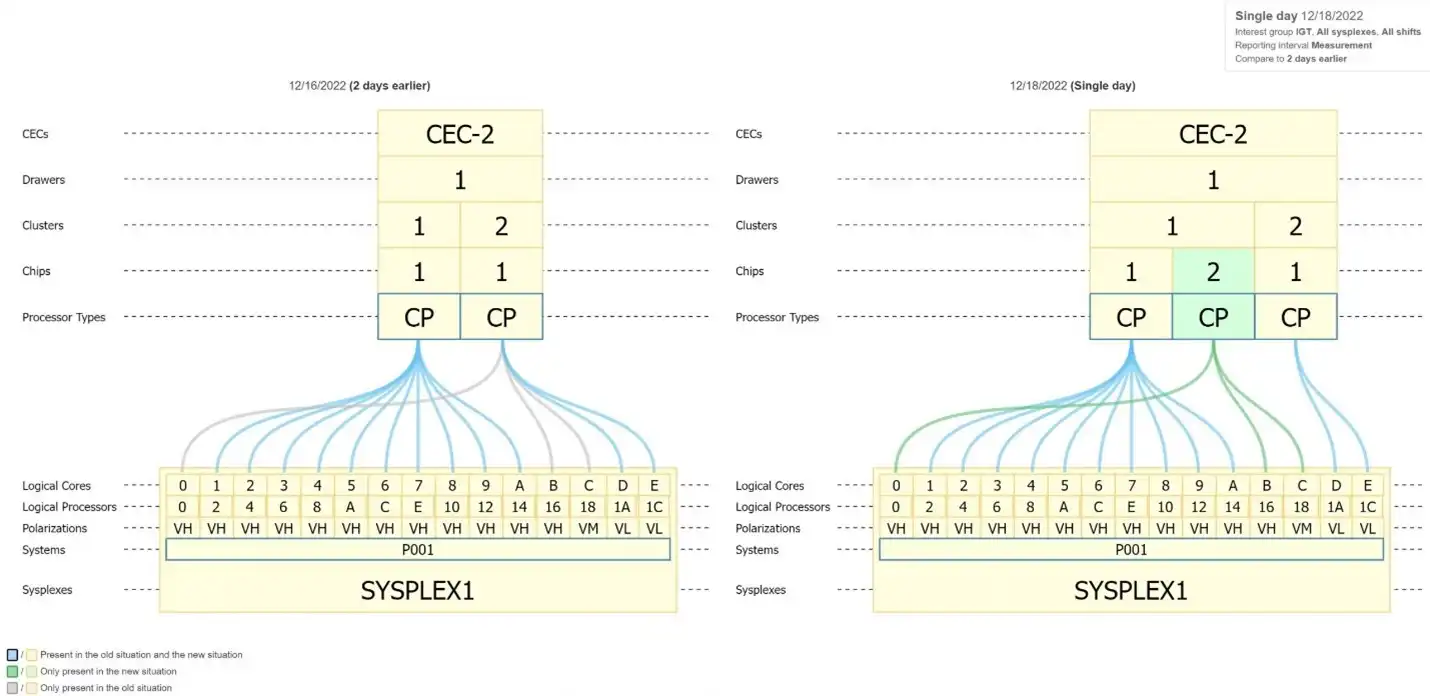
Figure 5: Comparing LPAR Topology differences over 2 days
Utilize Interactivity to Optimize Processor Cache Usage
An important aspect of reducing CPU cost is optimizing processor cache usage to get more work done with fewer processor cycles. To achieve this, you need to be able to optimize your processor configuration.
Interactivity, the ability to easily see, filter, and interact with the processor topology, provides a method for experienced analysts to configure processors quickly and easily while providing an avenue for newer staff to understand the data and system interactions at a much faster pace.
For resources that go into great detail about why optimizing processor cache usage can reduce software costs and what steps you can take to optimize your processor cache, view these:
The video below demonstrates what was covered in this blog and demonstrates how interactive access with the processor topology enables analysts to easily configure their processor configuration.

Job-level CPU Saving Opportunities in an Enterprise Consumption Environment
Analysts involved in leading CPU reduction efforts will have to focus limited staff resources on the top potential savings opportunities. This article focuses on job-level CPU reduction opportunities.
This article's author
 John Ticic
John Ticic Share this blog
You May Also Be Interested In:
What's New with IntelliMagic Vision for z/OS? 2024.2
February 26, 2024 | This month we've introduced changes to the presentation of Db2, CICS, and MQ variables from rates to counts, updates to Key Processor Configuration, and the inclusion of new report sets for CICS Transaction Event Counts.
From Taped Walls to Your PC: z/OS Configuration Made Simple with Topology | IntelliMagic zAcademy
In this webinar, we explore a technique that integrates diverse data sources from z/OS, presenting them in a clear, concise, and interactive visual format.
IntelliMagic Releases Breakthrough Interactive z/OS Subsystem Topology Viewer
November 6, 2023 | With the release of 12.10.0, IntelliMagic Vision has introduced an interactive z/OS Subsystem Topology Viewer, allowing performance analysts to visualize and directly interact with subsystem connections.
Book a Demo or Connect With an Expert
Discuss your technical or sales-related questions with our mainframe experts today